Hot Chips 33: IBMs Telum-Architektur setzt auf 32 MB L2-Cache – pro Kern

IBMs neuer z-Chip „Telum“ muss sich nicht hinter x86-CPUs verstecken: Zu den Design-Raffinessen des Mainframe-Prozessor gehören unter anderem 32 MB L2-Cache – pro Kern. Aber auch andere Eigenschaften suchen in der x86-Welt bisher ihresgleichen. Anfang 2022 sollen erste Systeme verfügbar werden.
IBM z16 dürfte auf Telum setzen
IBM gehört seit Jahrzehnten zu den Unternehmen mit den meisten Patentanmeldungen. Nicht nur auf dem Heimatmarkt USA, sondern auch global stand der Konzern wiederholt am Ende des Jahres sogar ganz an der Spitze. Viele Patentanmeldungen kommen dabei aus dem CPU-Bereich, aus dem auch IBM auf der Konferenz Hot Chips 33 einige interessante Dinge enthüllt hat. So heißt die neue Chiparchitektur für die z-Reihe „Telum“, Prozessoren auf dieser Basis werden den aktuellen z15 vermutlich als z16 ablösen.
Wer die Architektur-Eckdaten auf dem Papier nur grob überfliegt, findet zuerst einmal bekanntes wieder. Groß waren IBMs Prozessoren zum Beispiel schon immer, 530 mm² sind für eine Telum-Chip deshalb keine Besonderheit. 22,5 Milliarden Transistoren bringt IBM auf dieser Fläche mithilfe von Samsung unter, zum Einsatz kommt ein 7-nm-Prozess, der bereits EUV nutzt, zumindest für einige der 17 Metal Layer.
-
 IBM Telum alias z16 (Bild: IBM)
IBM Telum alias z16 (Bild: IBM)





Dass auf 530 mm² „nur“ acht Kerne zu finden sind, während AMD bei Zen 3 ebenfalls 8 Kerne inklusive 32 MB L3-Cache auf lediglich 81 mm² unterbringt, liegt am Aufbau mit langer Pipeline, sehr großen Branchtables und vor allem der Nutzung riesiger nativer Caches, die bei den Vorgängern zum Teil noch ausgelagert waren. Zu den 256 KByte L1-Cache pro Kern, die je zur Hälfte für Daten und Instruktionen gedacht sind, kommen 32 MByte L2-Cache – ebenfalls pro Kern! Das 8-Kern-Design bringt es demnach auf 256 MByte L2-Cache, ein doppelter Ringbus mit 320 GB/s Bandbreite bindet die Kerne an den Cache an.
-
 IBM Telum zu Hot Chips 33 (Bild: IBM)
IBM Telum zu Hot Chips 33 (Bild: IBM)



Der riesige L2-Cache ist allerdings nicht nur L2-Cache, sondern auch ein virtueller L3-Cache – diesen Ansatz gab es noch nie. Das Resultat: Die auf die Prozessoren abgestimmte Software sieht den Cache als physikalisch vorhandenen und über alle Kerne geteilten L3-Cache, wenn sie den Prozessor anspricht. Das System geht mit einer vierten Cache-Ebene weiter und skaliert vom Dual-Chip-Module (ein z16 wird vermutlich über zwei Telum-Chips verfügen) über den 4-Sockel-Drawer bis hin zum kompletten System mit vier Drawern und insgesamt 32 Telum-Chips (4 Drawer mit jeweils vier CPUs mit je zwei Chips) mit 8 GByte L2-Cache und dessen virtuellen Abstufungen.
-
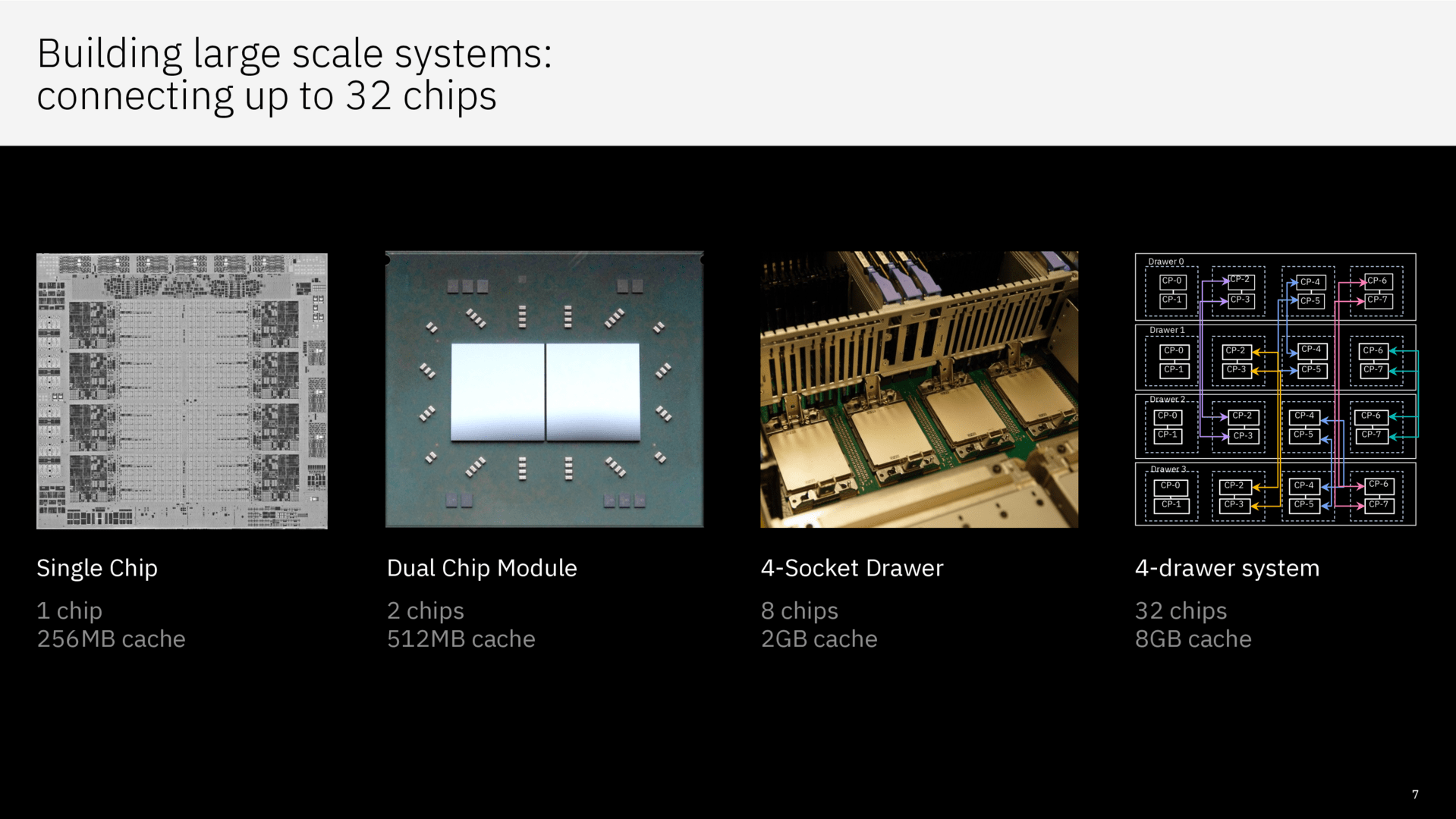 IBM Telum zu Hot Chips 33 (Bild: IBM)
IBM Telum zu Hot Chips 33 (Bild: IBM)



Mit der neuen Architektur wirft IBM auch Altlasten über Bord, Telum ist wirklich ein Neuanfang. Zu den eingestellten Technologien zählen auch Interconnect und Fabric, SMT8 (wie bei den Power-Prozessoren) oder SMT4 gibt es nicht, die neuen Modelle werden auf SMT2 setzen.
40 Prozent mehr Leistung pro Sockel
Bei Taktraten von über 5 GHz – der Vorgänger hatte 5,2 GHz – verspricht IBM 40 Prozent mehr Leistung pro Sockel. Der Bezug auf den Sockel relativiert die Leistungssteigerung pro Kern allerdings deutlich, der Vorgänger z15 hatte nämlich zwölf Kerne pro Sockel, nun sind es 16 in einem Dual-Chip-Design. So bleibt pro Kern nur eine Leistungssteigerung von rund 7 Prozent übrig.

Um in ausgewählten Anwendungsfällen noch deutlicher zulegen zu können, kommt auch noch ein AI-Chip zum Einsatz, der als Co-Beschleuniger für alle CPU-Kerne in einem Telum-Chip zur Verfügung steht und mit darauf angepasster Software funktioniert. In diesen hat IBM viel Forschung und Entwicklung investiert, bereits im Februar dieses Jahres hatte der Konzern erste Details enthüllt. Der Chip unterstützt FP16- und FP32-Operationen und weist eine sehr geringe Latenz aus, die über viele Kerne und Chips je nach Einsatzgebiet nahezu unverändert bleibt respektive fast ideal skalieren soll.
-
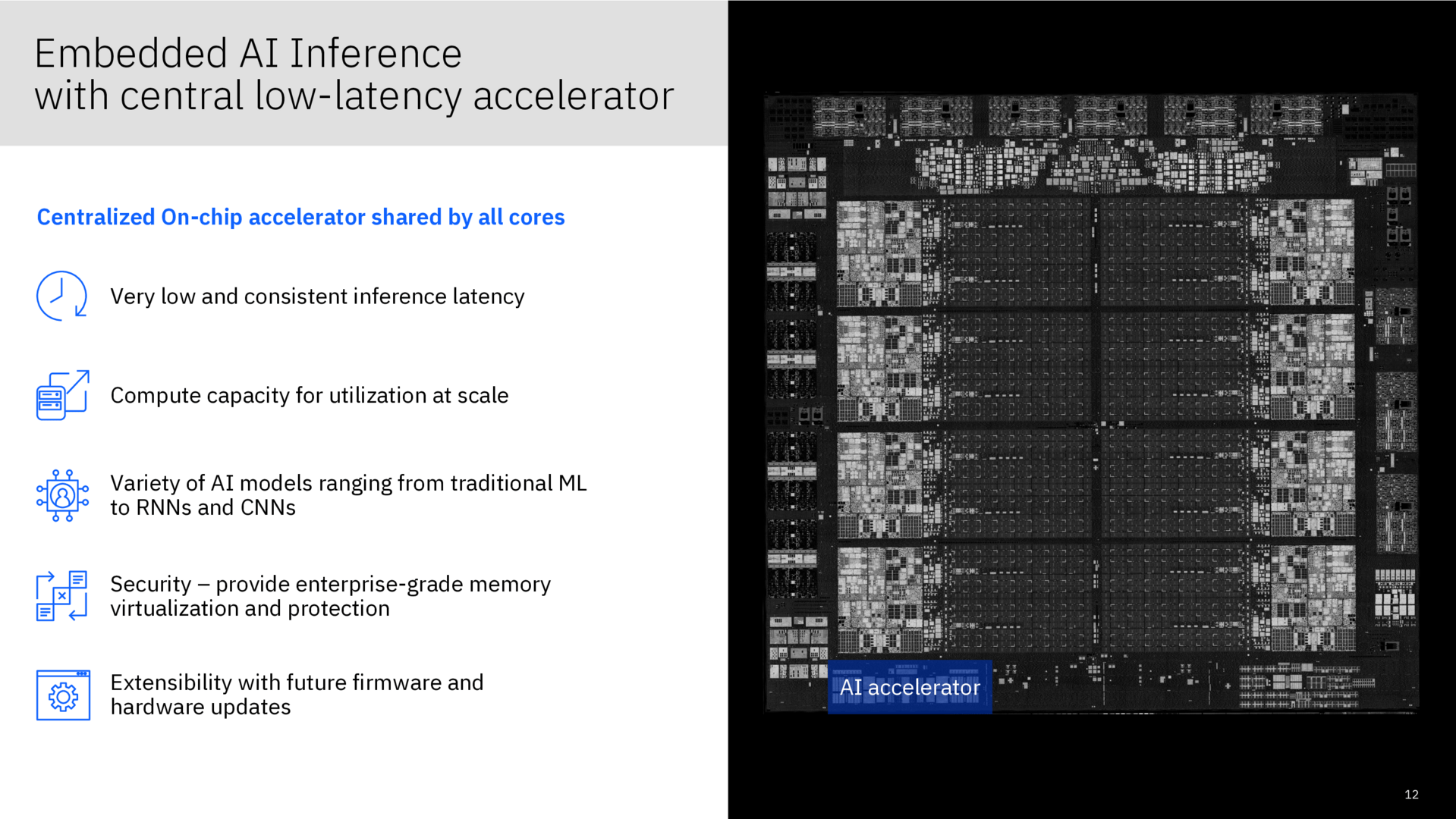 IBM Telum zu Hot Chips 33 (Bild: IBM)
IBM Telum zu Hot Chips 33 (Bild: IBM)

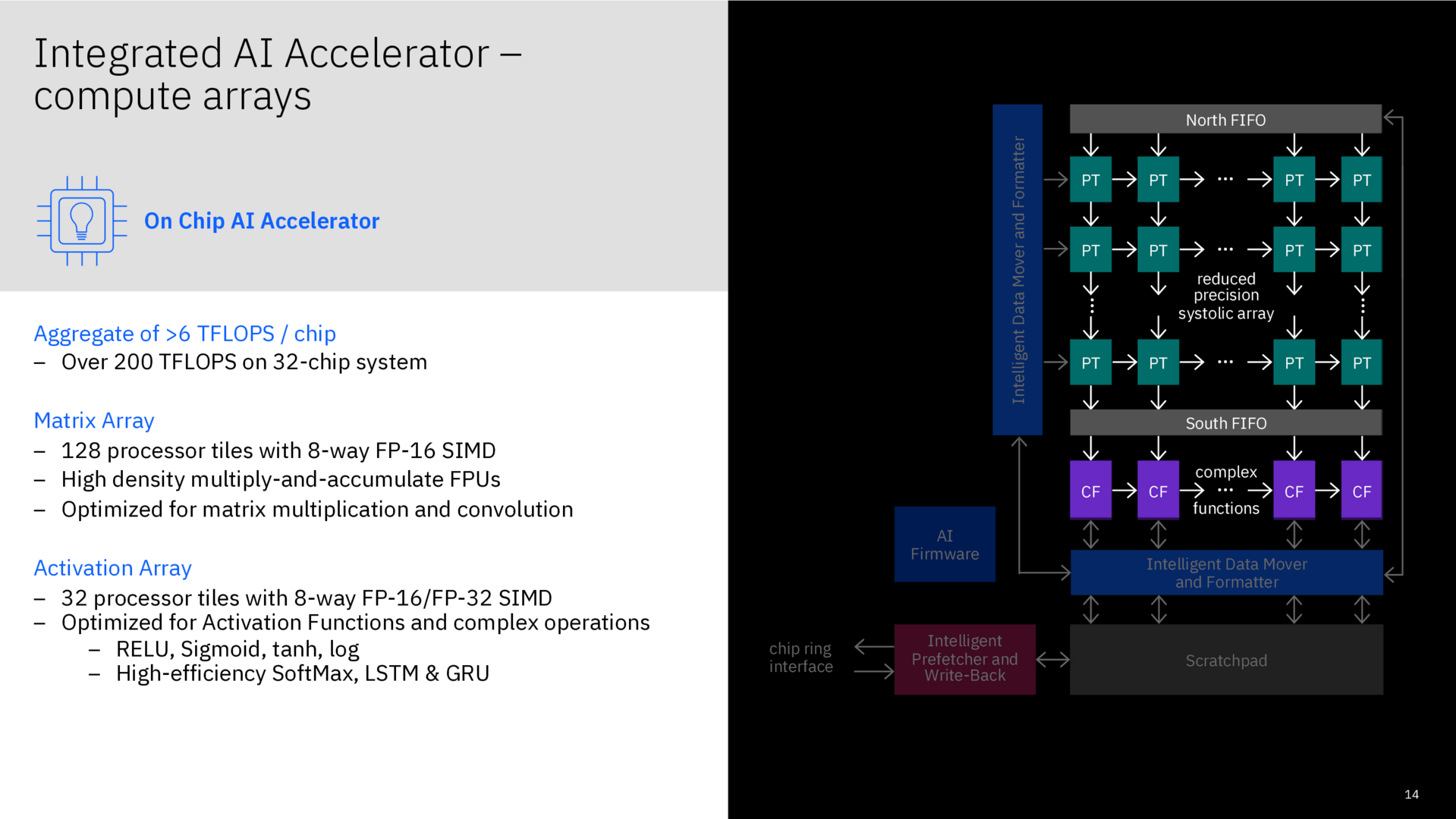
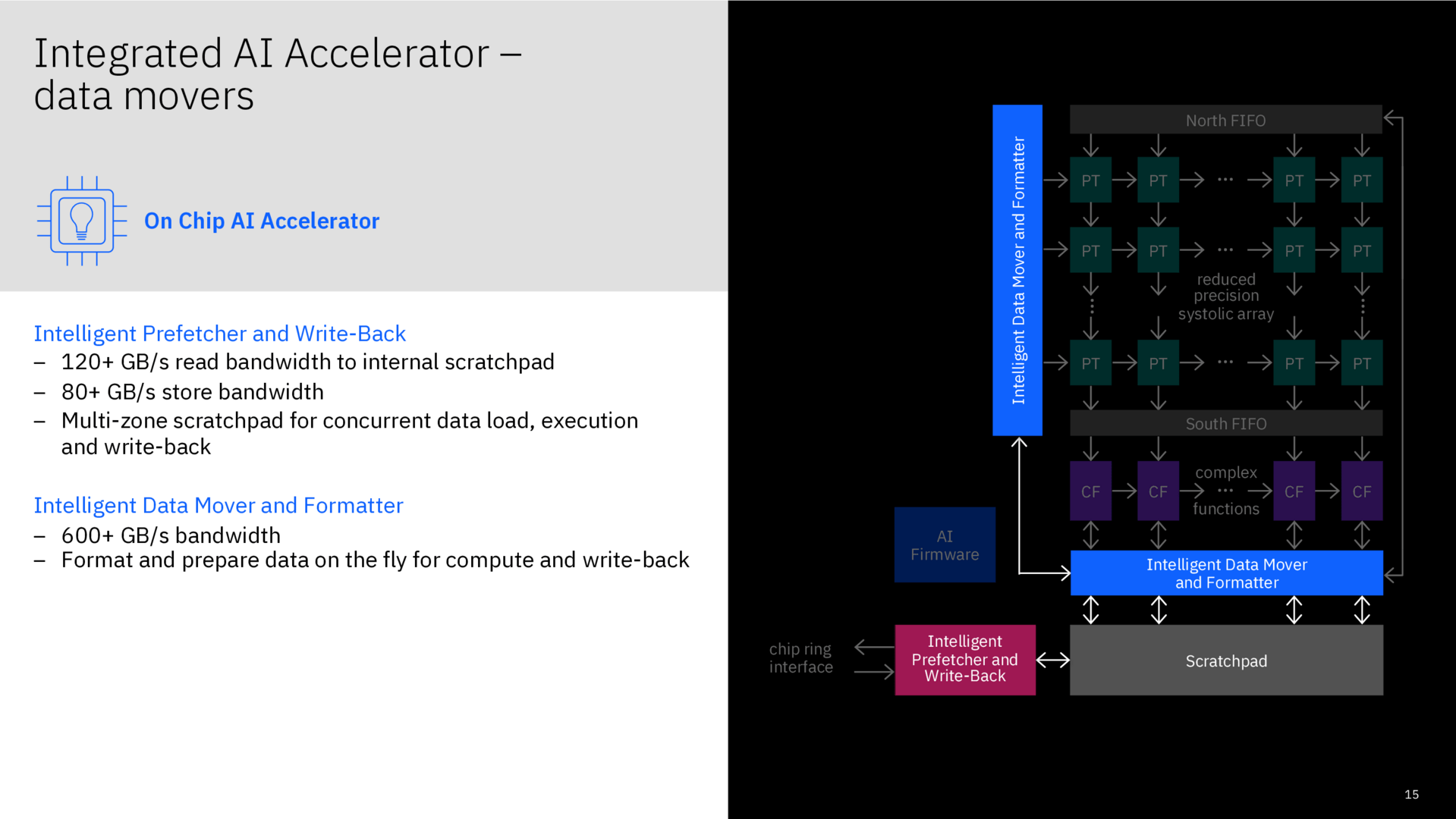
Als prädestiniertes Einsatzgebiet für die Telum-Architektur nennt IBM Kreditkartenabrechnungen in Echtzeit, die Optimierung auf die AI-Fähigkeiten der Architektur wurde in Kooperation mit einer Bank vorgenommen. Bei Hunderttausenden Transaktionen pro Sekunde sollen Latenzen von 1,1 bis 1,2 Millisekunden in Real-World-Szenarien erreichbar sein. Das soll es möglich machen, von der Erkennung eines Betrugs zur Prävention zu wechseln.
-
 IBM Telum zu Hot Chips 33 (Bild: IBM)
IBM Telum zu Hot Chips 33 (Bild: IBM)
Ab dem ersten Halbjahr des kommenden Jahres sollen die ersten Systeme mit den neuen CPUs ausgeliefert werden. Die neuen Mainframes werden dann die vor rund zwei Jahren eingeführten z15-Systeme ersetzen.

