ATi Radeon X1900 XTX und X1900 CF im Test: Der Angriff auf die GeForce 7800 GTX 512
3/29Technik im Detail
Auf den ersten Blick unterscheidet sich der neue R580-Chip von ATi gar nicht vom „altgedienten“ R520, der erst im Oktober des vergangenen Jahres präsentiert wurde. So kommen in der X1900-Serie erneut 16 Pixel-Pipelines mit je einer Texture Mapping Unit (TMU) sowie einem Raster-Operation-Processor (ROP) zum Einsatz, womit man immer noch an der traditionellen Architektur, wie sie unter anderem beim G70-Konkurrent von nVidia eingesetzt wird – abgesehen von dessen Reduzierung der ROPs in Bezug auf die Anzahl der Pixel-Prozessoren – festhält. Auch das 256 Bit breite Speicherinterface inklusive des Ring-Bus-Memory-Controllers ist gleich geblieben. Der R580 setzt ebenfalls wie der Vorgänger auf acht Vertex-Shader, an deren Funktionsumfang sich nichts verändert hat – wo also liegt der Unterschied?
Natürlich fallen einem die leicht erhöhten Taktraten bei der XTX-Version ins Auge, der Unterschied ist jedoch so gering, dass er nur für einen geringen Performancegewinn zuständig sein wird. Einen tieferen Blick in das „Innenleben“ zeigt dann endlich den Grund, warum der R580-Chip, der erneut im 90-nm-Verfahren von TSMC gefertigt wird, zirka 384 Millionen Transistoren trägt, knapp 60 Millionen mehr als der R520. Der R580 verfügt über drei gleichwertige Shader-Einheiten pro Pipeline anstatt nur einer wie beim R520, weswegen eine X1900-Grafikkarten auf insgesamt 48 „Arithmetic Logical Units“, kurz ALU, zurückgreifen kann. Theoretisch hat sich die Shader-Rechenkraft bei gleichem Takt dementsprechend um den Faktor drei erhöht. Dieses 3:1-Verhältnis zwischen ALUs und Textureinheiten begründet ATi mit den immer anfordernderen Shaderanweisungen in modernen Spielen, während die Texturberechnungen eher auf einem Level stagnieren. Den Feldversuch hat ATi bereits mit dem RV530 in Form der Radeon X1600 gestartet, die mit eben jenem 3:1-Verhältnis ausgestattet ist.

Doch was macht überhaupt eine ALU? Eine ALU kann verschiedene (arithmetische) Rechenoperationen wie beispielsweise ADD- (Additionen), SUB- (Subtraktionen), NOT- (Negierungen) oder MUL-Anweisungen (Multiplikationen) durchführen, die für die Berechnungen des Shaders von Nöten sind. Im Vergleich dazu bietet nVidia in der GeForce-7800-Serie zwei Shader-Einheiten pro Pipeline an, die jeweils ein MADD (Multiply-ADD: Multiplikation und Addition) ausführen können. Damit weist der G70-Chip 48 ALUs bei 24 Pixel-Pipelines (GeForce 7800 GTX) und 40 ALUs bei 20 Pixel-Pipelines (GeForce 7800 GT) auf. Ein NV40 hat dagegen nur 16 ALUs, obwohl auf diesem prinzipiell zwei Shader-Einheiten verbaut sind. Die erste Shader-Einheit kann allerdings kein MADD sondern nur ein ADD berechnen. Somit fehlt dieser Shader-Einheit der MUL-Befehl und wird allgemein nicht als vollständige ALU angesehen. Ab wann eine ALU nun als eine „richtige“ Shader-Einheit bezeichnen werden kann, ist wie so oft leider unklar. Wir sprechen deshalb von einer vollständigen ALU, falls diese eine MADD-Funktion verarbeiten kann, da das derzeit die entscheidende Operation für die gebrachte Leistung ist.
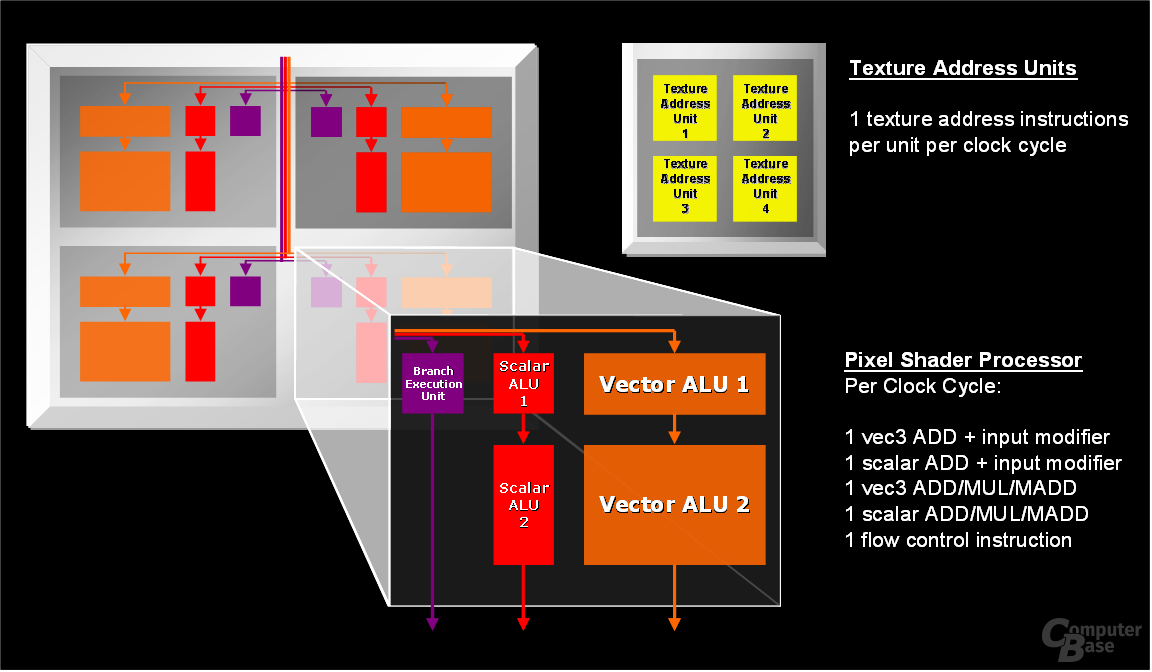
Jede der 48 Shader-Einheiten im R580-Chip beherrscht folgende Rechenfunktionen:
- 1 Vec3 ADD + Input Modifier
- 1 Scalar ADD + Input Modifier
- 1 Vec3 ADD/MULL/MADD
- 1 Scalar ADD/MULL/MADD
- 1 Flow Control Instruction
Interessante Neuigkeiten gibt es über den „Dispatch-Prozessor“. Dieser teilt den Shader im R520 in einen 4x4 Pixel großen Block auf, weswegen nicht nur die Latenzen extrem gering gehalten werden, sondern zusätzlich das „Dynamic Branching“ (Sprunganweisung durch If- oder Else-Befehle in einem Shader) extrem schnell ausgeführt werden kann. Durch die höhere Anzahl der ALUs im RV530 (wie beim R580 ein 3:1 Verhältnis) werden die Shader in einen 4x12 großen Block geteilt, wodurch der Chip etwas ineffizienter arbeitet. Wie ATi uns auf Anfrage aber mitteilte, ist dies beim R580 nicht der Fall. Dieser benutzt weiterhin einen 4x4 Pixel großen Thread; die GPU rendert mit der identischen Effektivität wie der R520. Doch auch abseits der Shader-Einheiten gibt es Detail-Verbesserung. Der R580 kann gegenüber dem Vorgänger R520 mit einer verbesserten HierarchicalZ-Funktion aufwarten. HierarchicalZ ist die erste Stufe der Berechnung von nicht sichtbaren Pixeln.
Zuerst wird jeder Pixel in einen Block kleinerer Pixel unterteilt, die einzeln auf Sichtbarkeit untersucht werden. Während Blöcke, die komplett unsichtbar sind, direkt verworfen werden, werden komplett oder teils sichtbare Pixelblöcke weiter in die Pixel-Engine geleitet. Durch dieses Vorgehen kann unter anderem wichtige Speicherbandbreite gespart werden und höhere Auflösungen sind eher realisierbar. Für HierarchicalZ-Berechnungen wird ein On-Chip-Speicher benötigt, der aber recht klein ausfällt. Falls für extrem hohe Auflösungen dieser Speicher zu klein ist, arbeitet der vorgezogene Tiefentest deutlich langsamer. Um diesem Effekt entgegenzuwirken, verbauen die Kanadier auf dem R580 einen doppelt so großen On-Chip-Speicher, womit selbst in hohen Auflösungen wie 2560x1600 HierarchicalZ mit der vollen Effektivität arbeiten kann.
Die letzte nennenswerte Neuerung ist ein Feature namens „Fetch4“, welches bei Shadow-Maps zum Einsatz kommt. Shadow-Maps werden in vielen Spielen zur Darstellung von Schatten eingesetzt. Ein Nachteil dieser Methode sind die harten Kanten der Schatten, welche in einer realen Umgebung nicht vorkommen; dort sind die Schatten meistens weich. Um dieses Problem zu umgehen, kann die GPU eine gewisse Anzahl an Samples aus der Shadow-Map nehmen und diese im Pixel-Shader bilinear filtern. Somit erscheint der Schattenverlauf weicher. Diese Methode hat aber auch einen Nachteil, so sinkt die Performance bei zu vielen Samples in den Keller, da entsprechend viele Befehle ausgeführt werden müssen (pro Sample ein so genannter TEX-Befehl) . Nun kommt Fetch4 ins Spiel, was diesen Vorgang beschleunigt.
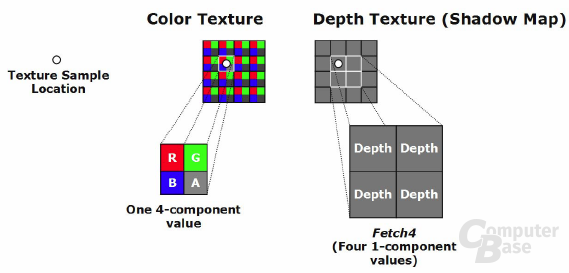
Der R580 nutzt bei Fetch4 den Umstand aus, dass jeder Farbwert aus vier Werten besteht – Rot, Grün, Blau sowie dem Alpha-Kanal (Transparentwert). Fetch4 kann nun jene Werte gleichzeitig in einem Durchgang samplen sowie berechnen und benötigt dafür nur einen TEX-Befehl; eine Shadow-Map kann deutlich schneller erstellt werden. Einen Nachteil besitzt Fetch4 allerdings, da die Shadow-Maps nicht gefiltert werden und dadurch des Öfteren unschöne Schatten produzieren. Zur Filterung müssen die Daten in den Pixel-Shader geschickt und dort verrechnet werden, was einige Rechenzeit in Anspruch nimmt. nVidias Verfahren namens PCF (Percentage Closer Filtering) geht einen Schritt weiter und filtert die Shadow-Map in einem Durchgang in der TMU. Fetch4 und PCF werden aktuell beispielsweise im 3DMark06 sowie den Spielen Far Cry, Battlefield 2 und Age of Empires 3 eingesetzt.