SchülerVZ-Profile nicht ausreichend geschützt?
Das Unternehmen VZnet Netzwerke sorgt erneut für negative Schlagzeilen: Am Freitag wurde bekannt, dass eine hohe Zahl von schülerVZ-Datensätzen ungeschützt im Internet kursieren. Teile der über eine Million Datensätze fassenden Liste wurden Markus Beckedahl, Netzaktivist und Betreiber des Blogs netzpolitik.org, anonym zugespielt.
Offenbar hat das Unternehmen keine Lehren aus der Datenpanne im Jahr 2006 gezogen. Damals gelang es dem Studenten Hagen Fritsch, eine ähnliche Menge von Datensätzen automatisiert auszulesen und anschließend anonymisiert auszuwerten – im genannten Fall stammten die Daten allerdings aus dem Schwesternetzwerk studiVZ. Auch diesmal ist zu betonen, dass es sich ausschließlich um öffentlich zugängliche Informationen handelt, also solchen, die andere Mitglieder des Netzwerks ohnehin einsehen können. Streng vertrauliche Daten wie Anschriften, E-Mail-Adressen oder gar Passwörter sind von der jüngsten Panne nicht betroffen. Im Februar 2007 hat es allerdings auch einen erfolgreichen Angriff auf solch sensible Daten gegeben.
Im jüngsten Fall handelte es sich wie vor drei Jahren nicht um eine echte Sicherheitslücke in den drei VZ-Netzwerken, sondern vielmehr um ein Problem, mit dem viele Communitybetreiber zu kämpfen haben: Wie schützt man Benutzerprofile vor sogenannten Crawlern und Harvestern? Diese Skripte durchforsten Websites nach verwertbaren Daten und speichern diese in Listen oder Datenbanken. Bei studi-, schüler- und meinVZ hat man Anfang 2007 darauf reagiert: Besucher, die innerhalb kurzer Zeit viele Profile besuchen, müssen seitdem ein CAPTCHA ausfüllen.
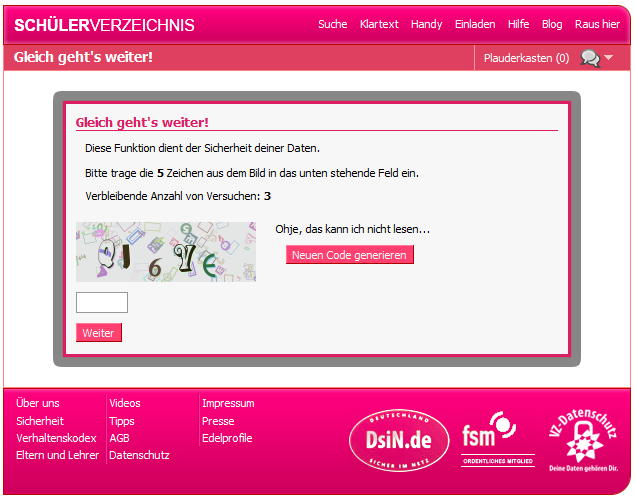
Das schülerVZ hat auf die Vorwürfe, man würde in Anbetracht der besonderen Schutzwürdigkeit der jungen Mitgliederschaft zu wenig für den Datenschutz innerhalb der Community tun, mit einer Stellungnahme im Entwickler-Blog reagiert. Auf Einsicht oder das Eingeständnis von Versäumnissen bei der Sicherheit wartet man bislang jedoch vergebens.
- Der Täter hat einen Crawler geschrieben, der sich mit normalen Nutzer Logindaten in die Community einloggt und die angezeigten Daten abgreift. Die bestehenden Sicherheitsmechanismen in Formularen und insbesondere in Form von Captchas wurden dabei geknackt.
- Der Täter behauptet weiterhin, auch meinVZ und studiVZ Daten gesammelt zu haben. Diese wurden nicht veröffentlicht. Wir versuchen mit allen Mitteln die Veröffentlichung dieser Daten zu verhindern.
- Der Täter hat die Daten weiter konkretisiert: es handelt sich wie bisher angegeben, um für alle Nutzer der Netzwerke einsehbare Daten. Jeder Nutzer in den VZs kann einstellen, welche Daten “von allen” einsehbar sein sollen und nur solche Daten konnte der Täter sehen und sammeln. Alle Schutzmaßnahmen zur Privatsphäre haben gegriffen und wurden explizit NICHT geknackt.
Angesichts der Kommentare und Meldungen an verschiedenen Stellen, wollen wir gerne auch noch einmal die rechtliche Relevanz über die Verletzung unserer AGBS hinaus beleuchten:
Das Crawlen eines Netzwerks unter Umgehung von Zugangssperren (Captchas) ist illegal. Zudem verletzt das Crawlen und das Veröffentlichen der gecrawlten Informationen Datenschutzrecht. Wir wollen genauso aber auch darauf hinweisen, dass der Täter die Rechte eines jeden einzelnen Nutzers verletzt hat.
SchülerVZ

Um die eigenen Daten vor den Augen Fremder zu schützen, hält das schülerVZ zwei Funktionen bereit. Die effizienteste ist wohl, sich aus dem Verzeichnis zu verabschieden. Eine zweite schützt zumindest vor Crawlern: Auf der schülerVZ-Website unter „Meine Privatsphäre“ befindet sich seit einiger Zeit eine Liste verschiedener Voreinstellungen. Empfehlenswert sind die beiden im Screenshot grün markierten Optionen – je nachdem, ob man sein Profil für „Freunde von Freunden“ öffnen will. Wer möchte, kann weiterhin detaillierte Einstellungen zur Sichtbarkeit der eigenen Daten vornehmen.
Bleibt abzuwarten, wie ernst die VZnet Netzwerke Ltd. ihre Datenschutz-Offensive nimmt, die seit kurzem unter dem Motto „Deine Daten gehören Dir“ angelaufen ist. In der Zwischenzeit hat sich der „Täter“ bei dem Unternehmen gemeldet und angekündigt, auch Datensätze aus dem meinVZ sowie studiVZ zu veröffentlichen. „Wir versuchen mit allen Mitteln die Veröffentlichung dieser Daten zu verhindern”, heißt es dazu.
Am Wochenende hat das Landeskriminalamt Berlin die Festnahme eines 20-jährigen Manns bekannt gegeben. Dieser sei in den Büros der VZnet Netzwerke Ltd. vorstellig geworden, wo er 80.000 Euro erpressen wollte, ein Viertel davon als Anzahlung. Mitarbeiter riefen daraufhin die Polizei, nachdem der junge Mann aus Erlangen gedroht hatte, die Daten nach Osteuropa zu verkaufen. Er befindet sich nun wegen des Verdachts auf versuchte Erpressung in Untersuchungshaft.
Blogger Markus Beckedahl betonte indes, dass es sich bei der festgenommenen Person nicht um seine Quelle handelt.
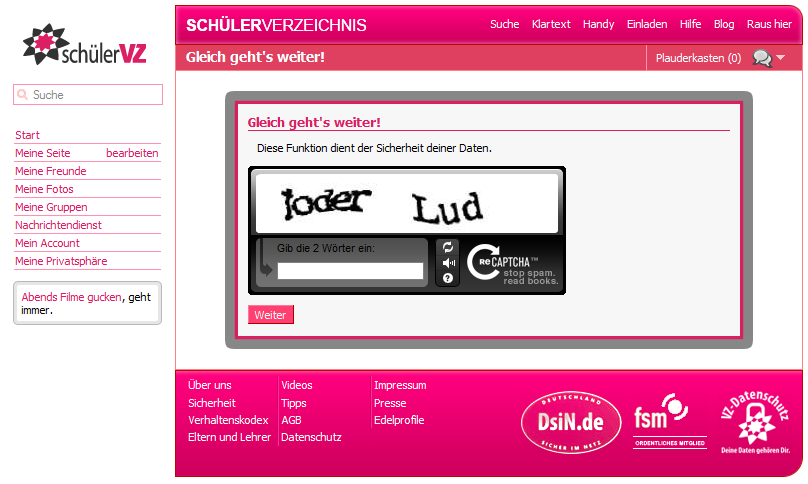
Offensichtlich haben die VZnet Netzwerke mit der Einbindung neuer sogenannter „reCAPTCHA“s reagiert (siehe Screenshot). Diese sollten den meisten Internet-Usern geläufig sein, schließlich finden sie sich mittlerweile in vielen Anmeldeformularen im Web wieder. Statt eines bunten Buchstabensalats muss man zwei aus Büchern eingescannte Wörter erkennen, bei denen die Texterkennungssoftware versagt hat. Eins davon ist bereits bekannt und dient als Prüfung. Die Eingaben zum jeweils anderen Begriff werden gesammelt und ausgewertet. Wenn sehr viele Personen dasselbe Wort erkannt haben möchten, wird dies als korrekt vernommen.