Raytracing in Spielen IV: Ray-Tracing in der Cloud
4/8Client-Server-Rendering
Auf dem Core i7 des Servers läuft eine Spiele-Engine, die alle Zustände verarbeitet und aktualisiert (z.B. Position des Spielers, welche Waffe derzeit gewählt ist etc.). Sie kommuniziert diese Informationen an die Ray-Tracing-Engine, die wie oben beschrieben ein Interface auf der CPU des Servers hat und das Rendern über Knights Ferry bewerkstelligt. Der Server transferiert dann die gerenderten Pixel über TCP/IP zum Client.
Der Client verarbeitet die Eingaben des User-Interfaces (gedrückte Tasten, Mausbewegung etc.) und wertet deren Aktionen aus (z.B. durch das Drücken der Nach-Oben-Taste bewegt sich der Spieler nach vorne). Die aktualisierten Zustände des Spiels werden dann an den Server geschickt. Der Client empfängt danach die Pixeldaten des Servers und zeigt sie am Bildschirm an. Der Client selbst rendert nichts.
Um die Berechnungskraft mehrerer Hardwareeinheiten zu kombinieren (in diesem Fall die der vier Server), gibt es verschiedene Möglichkeiten. Zwei davon werden im folgenden im Detail beschreiben:
- Verteiltes, kachel-basiertes Rendern über alle Server
Bei dieser Methode werden die Aufgaben des Renderns eines Bildes mit Ray-Tracing in mehrere kleine Kacheln (etwa 32x32 oder 64x64 Pixel) zerteilt und bestimmten Servern zugewiesen. Der Vorteil dieses Ansatzes ist, dass er eine sehr geringe Latenz hat. Die Maschinen arbeiten zusammen um so schnell wie möglich den einen Frame fertigzustellen. Der Nachteil ist jedoch, dass man gute Algorithmen benötigt, um die Lasten gleichmäßig zwischen den Servern zu verteilen. Einige Kacheln könnten viel schneller fertig sein als andere (z.B. das Berechnen des Himmels ohne Geometrie ist sehr schnell). Daher könnte es passieren, dass alle bis auf einen Rechner schon mit der Arbeit fertig sind und diese dann warten müssen, bis auch der letzte alles beendet hat. Um solche Optimierungsprobleme zu lösen, gibt es Ansätze wie das Task-Stealing, bei dem ein nicht beschäftigter Thread Arbeit aus der Pipeline eines anderen beschäftigten Threads heraus „stehlen“ kann. - Alternate frame rendering.
Bei diesem Ansatz wird ein kompletter Frame einer spezifischen Maschine zugewiesen. Der Vorteil ist, dass die Zuweisung sehr einfach vorzunehmen ist. In den meisten Fällen gibt es zwischen zwei aufeinanderfolgenden Frames kaum einen Zeitunterschied in der Berechnung, daher sind die Arbeiten gut verteilt zwischen den Rechnern. Der Nachteil ist allerdings, dass dadurch zusätzliche Lags entstehen. Im Falle von vier Servern ergibt sich eine Verzögerung von drei Frames für den Client. Bei einer Framerate von 60 Hz wäre das also eine 50 Millisekunden (ms) Verzögerung. Bei der Benutzung von Double-Buffering wie in dem hier verwendeten Setup ergeben sich sieben Frames Verzögerung (117 ms).
Wegen der zusätzlichen Verzögerungen des zweiten Ansatzes empfehlen wir für eine kommerzielle Implementierung den kachel-basierten Ansatz zu nehmen. Nichtsdestotrotz haben wir im Zuge dieser Forschungsstudie in der ersten Implementierung das Alternate Frame Rendering benutzt – mit der Möglichkeit, diesen Ansatz in einer zukünftigen Version zu verbessern.
Komprimierung
Um ein Bild aus dem Speicher über einer Grafikkarte auf dem Monitor darzustellen, benötigen fast alle modernen Geräte ein Bild mit einem Rot-, Grün-, Blau- und Alpha-Kanal (RGBA) mit jeweils 8 Bit. Bei einer Zielauflösung von 1280x720 benötigt ein einzelnes Bild daher 3600 kB Speicher. Nachdem der Alpha-Kanal in diesem Fall, nämlich Ray-Tracing, keine nützliche Information enthält, kann man die Größe „leicht“ auf 2700 kB reduzieren. Bei 60 Hz benötigt der Transfer der Bilder über das Netzwerk aber immer noch eine Datenrate von 158,2 MB (1264 Mbit) pro Sekunde und übertrifft somit sogar die Bandbreite von Gigabit Ethernet. Daher erscheint es als logische Konsequenz, dass eine Komprimierung benutzt werden muss, um die großen Datenmengen besser handhaben zu können - später sollen sie schließlich über das Internet.
Komprimierung benötigt zusätzliche Berechnungen auf der Seite des Servers zum Kodieren und auf dem Klient zum Dekodieren. Auf dem Server gibt es genug Ressourcen, um effizient zu Kodieren. In unserem Setup führt der ansonsten fast unbenutzte Sechskerner Core i7 einen auf Multi-Threading optimierten Kompressionsalgorithmus aus (alternativ könnte man dies auch direkt auf Knights Ferry tun). Der Client könnte allerdings ein schwächeres System darstellen und durchaus erheblich Zeit für das Dekodieren benötigen, bevor er das Bild darstellen kann.
Es gibt eine Vielzahl an möglichen Kodierern-Dekodierern (codecs), die zu diesem Zweck benutzt werden können. OnLive hat angedeutet, dass sie einen speziellen Chip zum Kodieren benutzen, um einen proprietären Videostream mit ihrem eigenen Codec zu erzeugen. Gaikai benutzt dagegen den regulären H.264-Codec, den man auch in YouTube- und Blu-ray-Videos finden kann.
Bei der Verwendung von 5 Mbit/s für den Videostream ergibt sich so eine akzeptable Bildqualität bei 1280x720, jedoch bleibt noch Platz für Verbesserungen. Sobald mehr Bandbreite zur Verfügung steht, können die meistens Codecs diese recht einfach durch das Verändern von Parameter ausnutzen, um ein Bild höherer Qualität zu erzeugen.

Um eine hohe Kompression zu vermeiden und die besten visuellen Ergebnisse zu erhalten, haben wir uns in unserem Experiment für den optimalen Fall eines Netzwerkes mit hoher Bandbreite entschieden: ein Gigabit-Ethernet. Das erlaubt uns eine andere Form der Komprimierung zu nehmen, die jeden Frame komplett einzeln behandelt (im Gegensatz zu einem Video Stream, bei dem ein späteres Bild oft eine Veränderung eines Vorherigen ist). Dies führt zu einer sehr hohen Bildqualität, die stabil bleibt und unabhängig davon ist, wie viel Bewegung zwischen den Bildern passiert. Der benutzte Algorithmus ist DXT1. Dieser hat eine feste Kompressionsrate von 1:8 für RGBA-Daten und findet sich auch oft in Spielen in Form des .dds Datei-Containers. Es gibt hochoptimierte Implementierungen dieser Kompression und Dekompression in den Intel Integrated Performance Primitives (IPP) 7.0, die auch SSE und Multi-Threading nutzen. Manche Grafikkarten unterstützen auch direkt DXT1 über Texturen ohne vorherige manuelle Dekodierung anzuzeigen. Das Ergebnis der Benutzung von DXT1 auf ein Bild ist ein kaum merkbarer Verlust gegenüber dem original Bild bei der Darstellung von Spiele-Szenen.


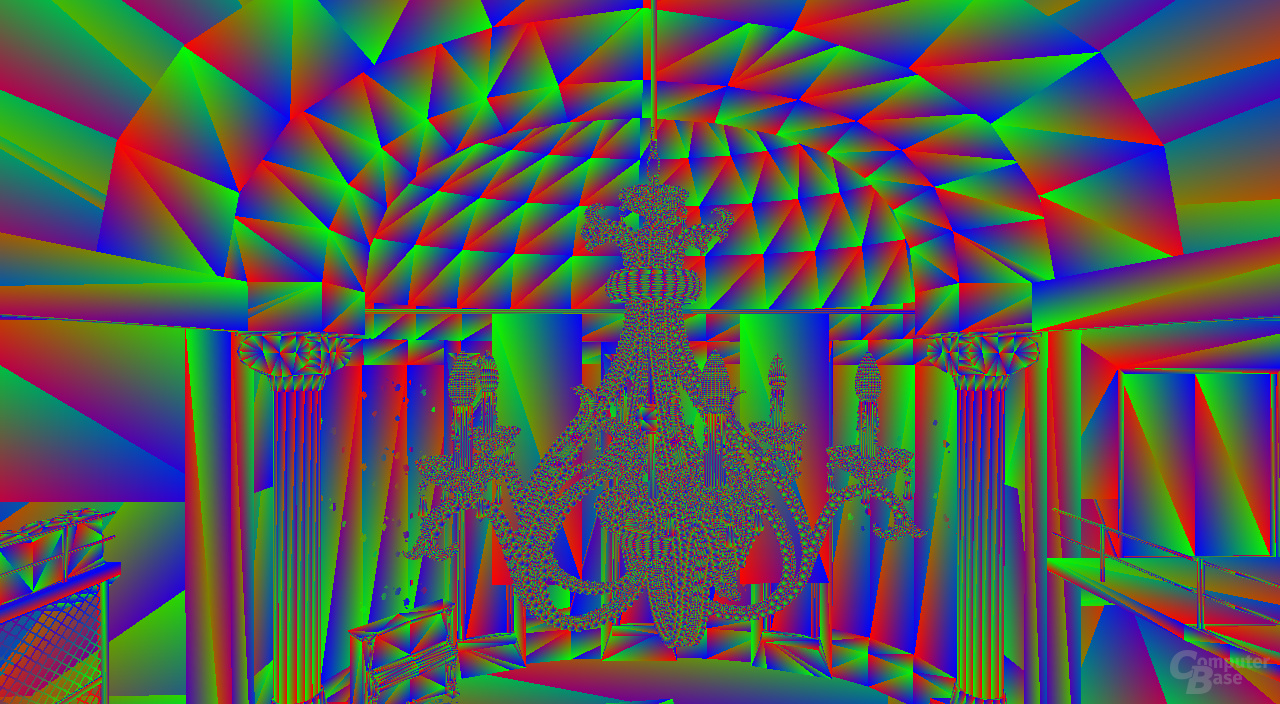
Natürlich gibt es auch Spezialfälle, in denen die Kompressionsartefakte sichtbar werden können. Ein Beispiel ist die Debug-Ansicht, die Dreiecke mit einem Shader darstellt, der für die Eckpunkte Rot, Grün oder Blau annimmt und dazwischen interpoliert. Für solch' unnatürliche Bilder eignet sich der DXT1-Algorithmus nicht besonders gut.