AMD Bulldozer im Test: Ein schwarzer Mittwoch
7/25„Front End“
Es gibt keinen modernen x86-Prozessor, der komplexe CISC-Befehle variabler Länge direkt verarbeitet. So übersetzen sowohl AMD als auch Intel die eingehenden x86-Befehle in kleine, handliche Instruktionen, die das Prozessor-Back-End versteht. Diese Vorverarbeitung (Dekodierung) erfolgt im Prozessor-Front-End, das die Mini-Instruktionen, so genannte Micro-Befehle (µOps), erzeugt. Die Hauptaufgabe und Herausforderung des „Front End“ ist es nun, stets genügend µOps an das „Back End“ zu liefern, damit dieses unentwegt beschäftigt ist. Genau dort hat AMD umfangreiche Optimierungen angesetzt und in einigen Bereichen das Rad fast neu erfunden, denn je reibungsloser und besser der Datenstrom funktioniert, desto effektiver und schneller wird ein Prozessor.
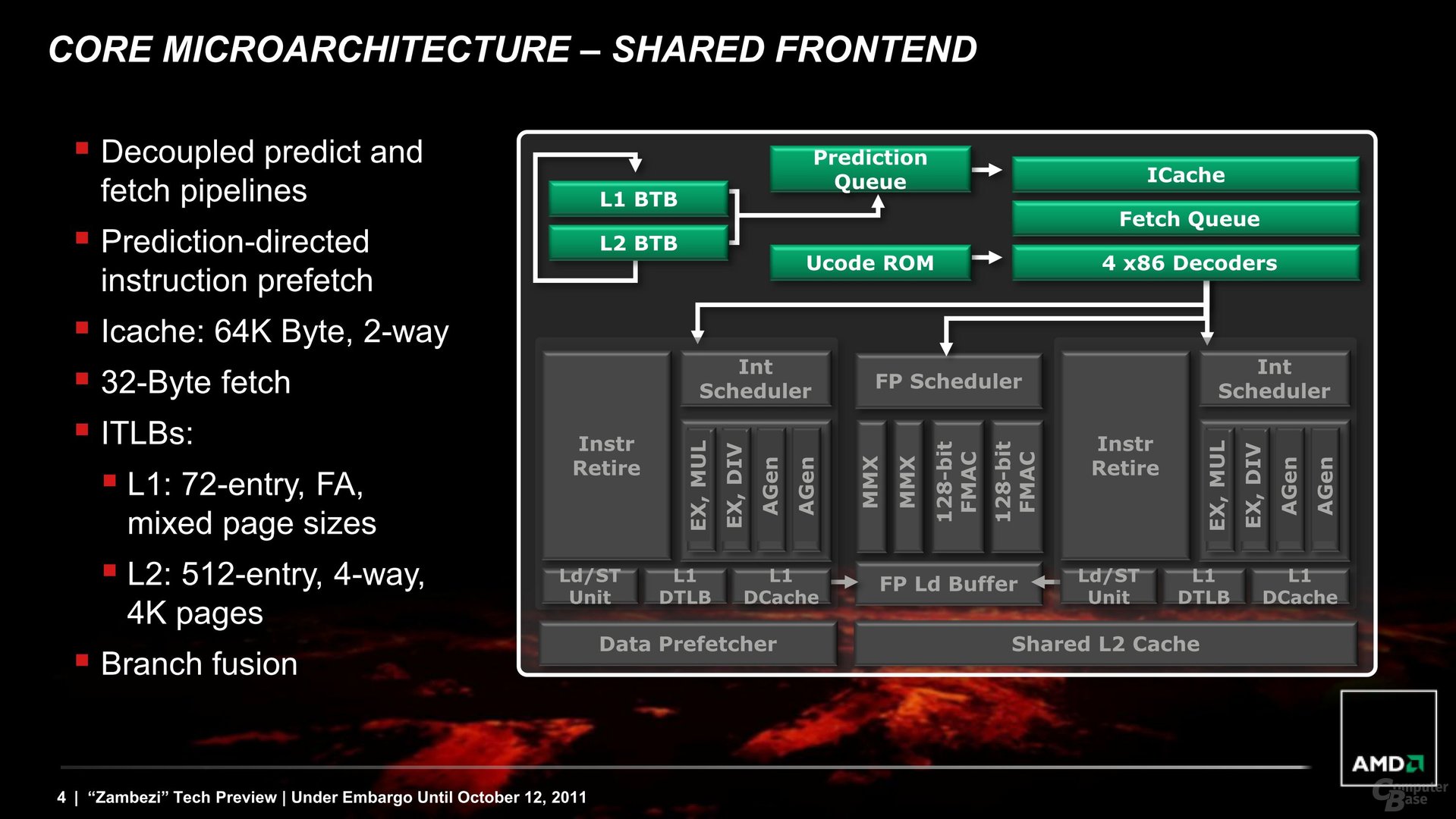
Die Sprungvorhersage markiert mit einigen weiteren Teilen das wichtigste Element des Front End. Genau dort bietet sich für die Architekten ein großer Spielraum für Optimierungen, denn immer wenn ein Sprung (engl. Branch; inhaltlich die nächste Berechnung) falsch vorher gesagt wird, muss die gesamte Pipeline geleert werden. Dies reduziert nicht nur die Performance, auch bereits investierte Energie geht verloren. AMD hat deshalb dort angesetzt und einige neue Dinge implementiert. So gibt es unter anderem sowohl einen L1 Branch-Target-Buffer (BTB) als auch einen L2 Branch-Target-Buffer, in dem unterschiedlich entfernte Sprungziele gespeichert werden.
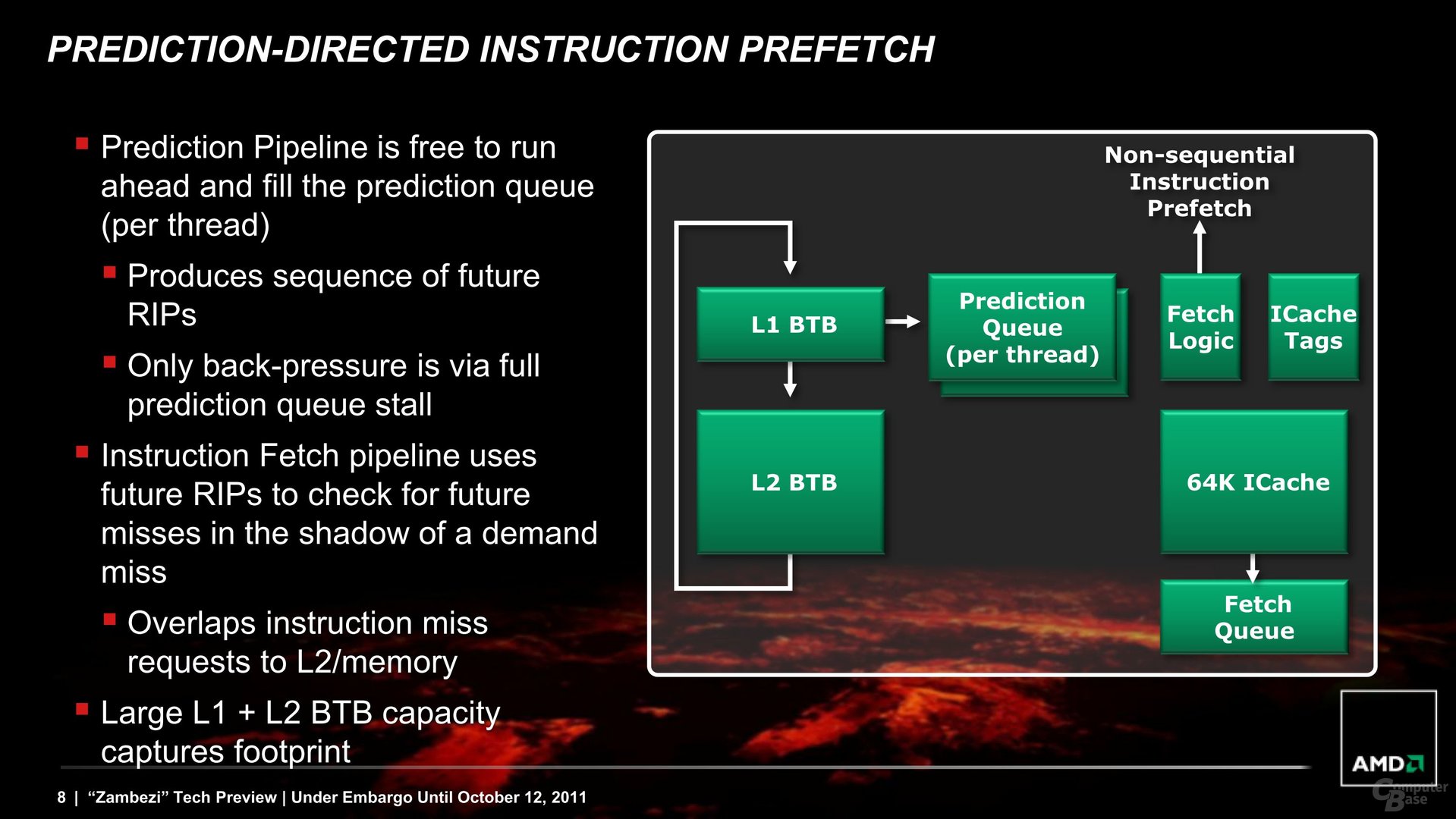
Wie das zweite Bild darlegt, geschieht vor dem eigentlichen Laden des Befehls und der Übergabe an die Integer-Kerne und die Gleitkomma-Einheit (FPU) noch so manches an Vorbereitungen. Neue Relative Instruction Pointers (RIPs) werden so lange gebildet, bis sie abgearbeitet sind, oder die Warteschlange voll ist. Die bereitgestellten Befehle in der Prediction Queue werden dann in Sequenzen auf dem Weg zum Fetch Queue geschickt, der für das Laden der Befehle zuständig ist. Vorher wird jedoch noch der Blick in den 64 KByte großen Instruction Cache geworfen.
Ein „Bulldozer“-Modul kann nun bis zu vier x86-Instruktionen pro Zyklus weiterleiten, der Phenom II brachte es noch auf drei. Der gesamte Bereich des Front Ends ist jedoch auf das komplette Modul ausgelegt, man füttert mit diesem jetzt zwei Integer-Kerne und die Gleitkomma-Einheit, die gemeinsam das „Back End“ bilden.