F_GXdx
Captain
- Registriert
- März 2006
- Beiträge
- 4.028
Hallo Leute,
ich mache gerade ein Praktikum und soll dazu eine - eigentlich sehr simple - Datenbank modellieren, die folgendes leistet:
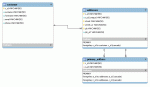
- Es gibt Kunden (table: customers) mit einer ID (c_id)
- Kunden haben mindestens eine Adresse (table: addresses)
- Genau eine der Adressen muss eine Primäradresse sein (table: primary_address)
So, ich habe das wie folgt gelöst:
- Ich möchte gerne die dritte Normalform einhalten
- Adresse enthält die c_id, die wiederum c_id von customers als Fremdschlüssel hat
- primary_address enthält a_id, die wiederum a_id in addresses als Fremdschlüssel hat
- primary_address enthält c_id, die wiederum c_id in addresses als Fremdschlüssel hat
Grafisch im Anhang!
Ja, das wär's. Datenbanken ist relativ lange her in meinem Studium, daher wäre ich interessiert an eurer Meinung. Was spricht eventuell gegen das Design? Was würdet ihr evtl. anders machen?
mfg
ich mache gerade ein Praktikum und soll dazu eine - eigentlich sehr simple - Datenbank modellieren, die folgendes leistet:
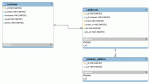
- Es gibt Kunden (table: customers) mit einer ID (c_id)
- Kunden haben mindestens eine Adresse (table: addresses)
- Genau eine der Adressen muss eine Primäradresse sein (table: primary_address)
So, ich habe das wie folgt gelöst:
- Ich möchte gerne die dritte Normalform einhalten
- Adresse enthält die c_id, die wiederum c_id von customers als Fremdschlüssel hat
- primary_address enthält a_id, die wiederum a_id in addresses als Fremdschlüssel hat
- primary_address enthält c_id, die wiederum c_id in addresses als Fremdschlüssel hat
Grafisch im Anhang!
Ja, das wär's. Datenbanken ist relativ lange her in meinem Studium, daher wäre ich interessiert an eurer Meinung. Was spricht eventuell gegen das Design? Was würdet ihr evtl. anders machen?
mfg
Anhänge
Zuletzt bearbeitet: