Nvidia GeForce GTX 750 (Ti) „Maxwell“ im Test: Vier Grafikkarten im Vergleich

„Maxwell“ ist da
„Maxwell“, Nvidias neue GPU-Architektur für Desktop- und Notebook-Grafikkarten, ist da. Doch anders als bis jetzt gewohnt, betritt der Neuling nicht in Form einer High-End- oder einer Performance-Karte, sondern auf zwei Mittelklasse-Produkten den Markt. An der Leistungsspitze legt Nvidia stattdessen noch einmal mit dem Vorgänger „Kepler“ nach und schickt mit dem heutigen Tag auch die GeForce GTX Titan Black ins Rennen.
An dieser Stelle geht es allerdings um die ersten beiden Produkte mit Nvidias neuer GPU-Generation: die GeForce GTX 750 Ti und die GeForce GTX 750. Die neue Maxwell-Architektur soll doppelt so energieeffizient wie die alte Kepler-Architektur sein, verspricht Nvidia.
Auf den folgenden Seiten fühlen wir „der ersten Generation von Maxwell“ in Form von vier ganz unterschiedlichen Grafikkarten auf den Zahn. Insbesondere der Frage, inwieweit Nvidia gegenüber der im März 2012 vorgestellten „Kepler“-Architektur die Energieeffizienz steigern konnte, gehen wir dabei auf den Grund.
An dieser Stelle danken wir Nvidia, Palit und Zotac für die Bereitstellung der GeForce-GTX-750-Ti-Karten. Der Online-Shop Caseking* steuerte freundlicherweise die GeForce GTX 750 bei.
Das ist neu bei „Maxwell“
Der Die und die Fertigung
Der erste Chip der „Maxwell“-Generation ist der im 28-nm-Prozess bei TSMC gefertigte GM107. Er kommt sowohl auf GeForce GTX 750 als auch GTX 750 Ti zum Einsatz. Ob es sich um den klassischen 28-nm-HP- oder möglicherweise den stromsparenderen 28-nm-HPM-Prozess handelt, wollte Nvidia auf Nachfrage nicht verraten.
Der heute vorgestellte GM107 setzt sich aus 1,87 Milliarden Transistoren zusammen. Die Größe des Chips liegt bei 148 mm². Im Vergleich dazu: Der GK107 der „Kepler“-Generation auf der GeForce GTX 650 ist 118 mm² groß und basiert auf 1,3 Milliarden Transistoren, der GK106 auf der GeForce GTX 650 Ti wiegt 2,54 Milliarden Transistoren auf 214 mm².
Insbesondere der Vergleich zwischen GM107 und GK106 ist interessant, da Nvidia Maxwell eine höhere Energieeffizienz unterstellt. Will heißen: der mit 1,87 Mrd. Transistoren bestückte neue Chip soll auf der GeForce GTX 750 Ti trotz gleichem Fertigungsverfahren weniger verbrauchen und trotzdem schneller sein als die GeForce GTX 650 Ti.
| GM107 „Maxwell“ | GK107 „Kepler“ | GK 106 „Kepler“ | |
|---|---|---|---|
| Fertigung | 28 nm (HPM?) | 28 nm HP | |
| Transistoren | 1,87 Mrd. | 1,30 Mrd. | 2,54 Mrd. |
| Chipfläche | 148 mm² | 118 mm² | 214 mm² |
| Grafikkarte | GeForce GTX 750 Ti GeForce GTX 750 |
GeForce GTX 650 GeForce GT 640 GeForce GT 630 |
GeForce GTX 660 GeForce GTX 650 Ti GeForce GTX 650 Ti Boost |
Der Hersteller selbst spricht in Bezug auf den Chip von der „ersten Generation Maxwell“. Chips der ersten Generation werden in Bezug zu den Vorgängern die höhere Energieeffizienz in erster Linie in weniger Verbrauch umsetzen, eine höhere Leistung am oberen Leistungsbereich steht nicht im Fokus.
Erst in der „zweiten Generation“ wird Nvidia die Architektur mit ihrer höheren Energieeffizienz dazu nutzen, schnellere GPUs zu entwickeln, die schlussendlich „Kepler“ an der Leistungsspitze beerben werden. Wann dieser Schritt erfolgen und ob auch dann noch im 28-nm- oder bereits im 20-nm-Prozess gefertigt wird, ist zurzeit noch unklar. Die Ankündigung einer GeForce GTX Titan Black auf „Kepler“-Basis zum Marktstart der ersten Generation deutet allerdings darauf hin, dass nicht vor dem Jahresende mit einer Wachablösung zu rechnen ist.
Was Nvidia getan hat, um die Energieeffizienz bei Maxwell zu erhöhen, ohne die Fertigungsstrukturen zu verkleinern, klären wir in den Folgeabschnitten. Ins Detail gehen wollte Nvidia auf einer Veranstaltung im Vorfeld der Markteinführung allerdings nicht. „Wir wollen schließlich nicht, dass die Konkurrenz zu früh zu viel erfährt“, so die Kalifornier.
Das, was bekannt ist, ist den folgenden Abschnitten im Detail zu entnehmen.
Die Streaming-Prozessoren
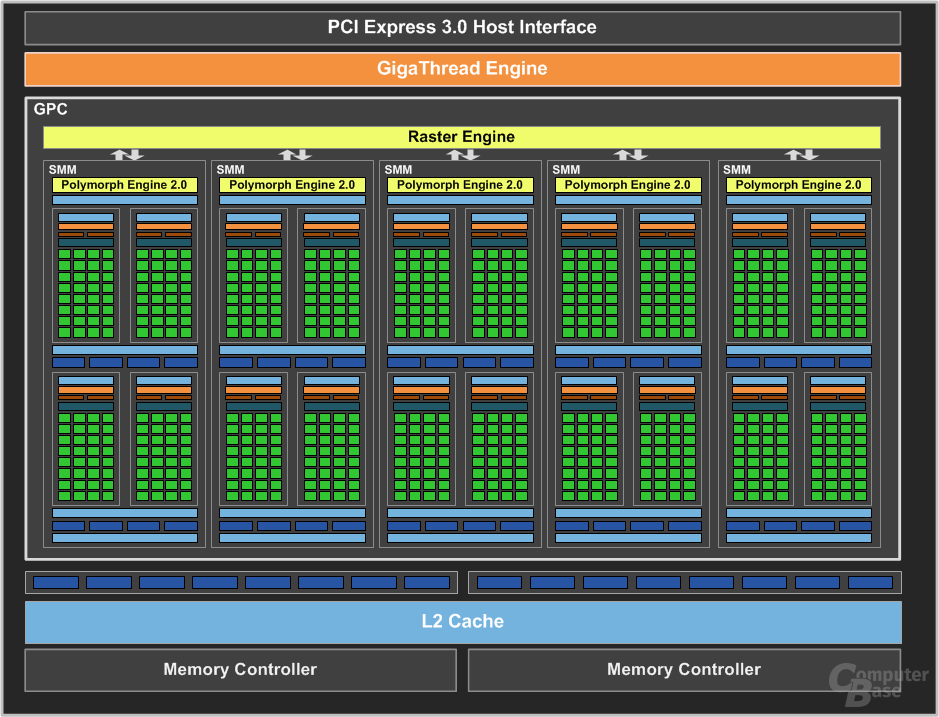
Die grundlegende Zusammensetzung eines „Streaming Multiprocessors“ hat Nvidia mit Maxwell völlig verändert. Der „Maxwell Streaming Multiprocessors“ (SMM) besteht nur noch aus 128 ALUs – ein Drittel weniger als bei Kepler mit 192 Einheiten.
Auch die Anzahl der Kontrolllogiken, die die ALUs mit Rechenaufgaben versorgen, hat Nvidia angepasst. Bei Maxwell kommen pro SMM jetzt vier statt einer zum Einsatz. Jede Kontrolllogik kümmert sich um 32 ALUs. Als Ausgleich fällt die „Control Unit“ deutlich weniger komplex und kleiner aus. Die Summe der vier Einheiten bei Maxwell soll weniger Platz beanspruchen als die eine Einheit bei Kepler. Das spart Platz auf dem Die.
| „Maxwell“ | „Kepler“ | |
|---|---|---|
| ALUs | 128 | 192 |
| Kontrollogik | 4 | 1 |
| Leistung* | 90 Prozent | 100 Prozent |
| * Leistung des SM bei gleichem Takt, Kepler = 100 Prozent | ||
Resultat des stark verschobenen Verhältnisses aus ALUs und Kontrolllogiken je SMM ist, dass die Gesamtauslastung der Recheneinheiten bei Maxwell deutlich gestiegen ist, so Nvidia. Obwohl der SMM mit 33 Prozent weniger ALUs daher kommt, soll er 90 Prozent der Leistung der Variante von Kepler erreichen. Das ist nur möglich, wenn jede ALU bei Maxwell 35 Prozent mehr leisten kann als bei Kepler.
Um die Effizienz weiter steigern zu können, liegt die Aufgabe der Verteilung der Rechenaufgaben nicht mehr nur alleine bei der Kontrollhardware, sondern wird bei Maxwell, anders als bei Kepler, zu einem gewissen Teil auch vom Treiber in Software – und damit von der CPU – übernommen. Bereits dieser „sortiert“ gewisse Daten vor, sodass nicht mehr nur die Hardware entscheiden muss, welche Rechenaufgabe an welche ALU übergeben wird. Dies war für die Vereinfachung der Kontrolllogik notwendig. Genauere Details dazu fehlen aber, sodass unklar ist, inwieweit dies mit Leistungseinbußen verbunden ist.
Eine SMM besteht aber natürlich nicht nur aus ALUs, sondern auch noch aus anderen Einheiten. Bei den Polymorph-Engines (zuständig für Tessellation) und der Größe des Shared-L1-Cache pro SMM (weiterhin 64 KB) hat sich allerdings gegenüber Kepler nichts geändert. Allerdings ist der ehemals geteilte L1-Cache bei „Maxwell“ jetzt ein reiner klassischer Shared-Cache, während es einen zusätzlichen kombinierten L1-Cache für Texturen und Compute gibt. Dessen Größe ist unbekannt.
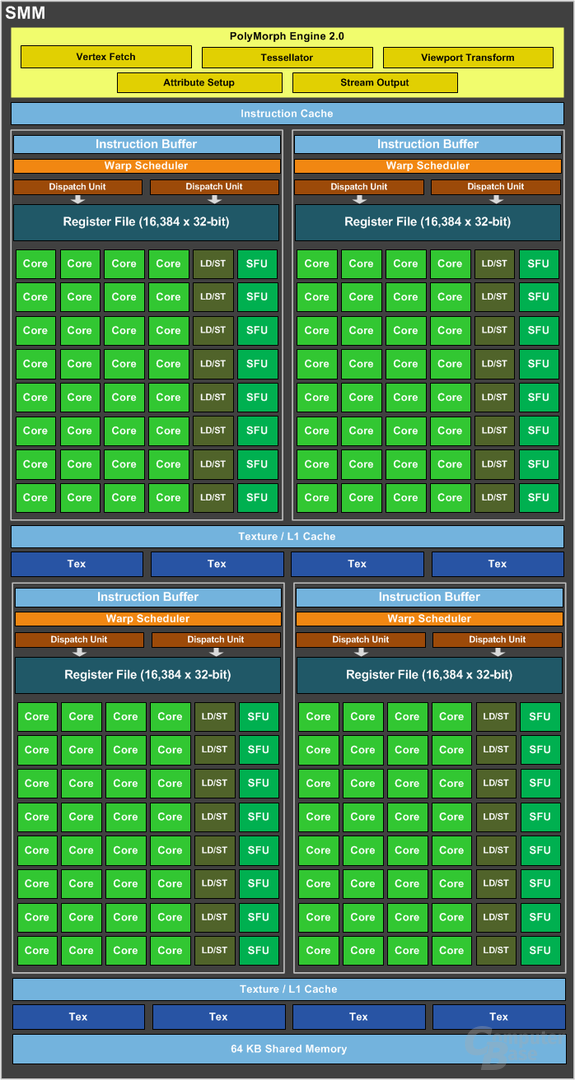
Deutliche Veränderungen gibt es auch bei den Textureinheiten (TMU). Auf Kepler gab es pro SM 16 Stück. Auf Maxwell sind es aber nur noch deren acht. Nvidia ist sich zwar bewusst, dass dieser Einschnitt Leistung kosten kann, hat ihn aus Gründen der Energieeffizienz aber dennoch vollzogen. Mehr TMUs hätten zu sehr auf die Leistungsaufnahme gedrückt.
| „Maxwell“ | „Kepler“ | „GCN“ | |
|---|---|---|---|
| TMUs je SMM / Compute Unit | 8 | 16 | 4 |
| Verhältnis TMUs zu ALUs | 1:16 | 1:6 | 1:16 |
Setzt man ALUs und TMUs auf Kepler, Maxwell und AMDs Graphics Core Next (GCN) ins Verhältnis, zeigt sich: Maxwell bietet ab sofort dasselbe Verhältnis wie AMDs GCN-Architektur.
Die SMMs sind auch bei Maxwell in einem „Graphics Processor Cluster“ (GPC) zusammengefasst, der die „Raster-Engine“ beherbergt. Der GPC bildet das sogenannte „Front-End“, das sämtliche SMM mit Aufgaben versorgt und damit für deren Auslastung zuständig ist. Ein GPC besteht bei Maxwell aus fünf SMM. Bei Kepler waren es dagegen zwei. Dennoch bleibt es, zumindest den offiziellen Informationen zufolge, bei einer einzelnen Raster-Engine. Ob diese verbessert worden ist, bleibt unklar. Dies ist aber anzunehmen, da eine Raster-Engine auf Maxwell mehr Einheiten mit Aufgaben versorgen muss als auf Kepler.
(*) Bei den mit Sternchen markierten Links handelt es sich um Affiliate-Links. Im Fall einer Bestellung über einen solchen Link wird ComputerBase am Verkaufserlös beteiligt, ohne dass der Preis für den Kunden steigt.