Neue ATi-Grafikkarten im Test: Radeon HD 4850 und eine Vorschau zur HD 4870
3/34Technik im Detail Part 1
Allgemeines:
Mit der ursprünglichen R600-Architektur hat sich ATi sicherlich keinen großen Gefallen getan. Der auf der Radeon HD 2900 XT eingesetzte Chip war nicht nur sehr groß, leistungshungrig sowie kompliziert zu fertigen, zu allem Übel war er auch noch relativ langsam. Einen Schritt weiter ging der RV670, obwohl sich an dem eigentlichen Aufbau nicht viel geändert hat.
Nun geht es mit dem RV770 einen weiteren Schritt nach vorne, der im Vergleich R600 vs. RV670 allerdings eher als Sprung bezeichnet werden darf. Die eigentliche Architektur ist zwar immer noch identisch mit der des R600, jedoch hat man viele Details verändert, weswegen der Chip nun spürbar schneller als der Vorgänger werden soll. Dabei setzt der RV770 immer noch auf den 55-nm-Prozess bei TSMC (wobei man bedenken sollte, dass 55-nm-Prozess nicht gleich 55-nm-Prozess ist; so gibt es alleine bei TSMC zwei verschiedene 55-nm-Prozesse), die Anzahl der Transistoren ist aber auf 965 Millionen Schalter und die Chip-Fläche von 193 mm² auf 260 mm² gestiegen. Der RV670 gab sich noch mit 666 Millionen Transistoren zufrieden.

Die nackten Daten des RV770 hören sich viel versprechend an: 160 5D-Shadereinheiten (RV670: 64), 40 vollwertige Textureinheiten (RV670: 16), 16 stark verbesserte ROPs (RV670: 16), ein nochmals effizienteres 256-Bit-Speicherinterface und vieles mehr hat sich in der RV770-Architektur geändert. Die Direct3D-10.1-API wird natürlich weiterhin von der Radeon-HD-4800-Serie, so der Name der ersten Produktreihe mit dem neuen Rechenkern, unterstützt und selbst die bis jetzt noch nie verwendete Tessellations-Einheit (die nun völlig kompatibel zu Direct3D 10.1 ist) hat wieder Einzug gefunden.
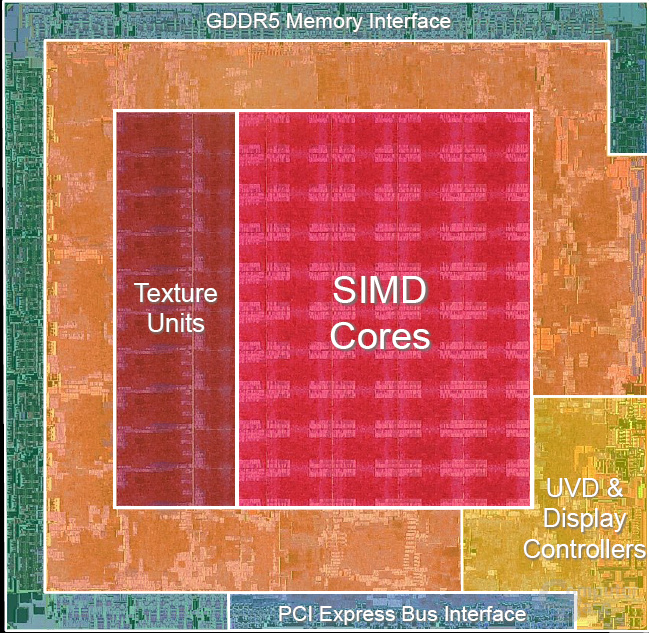
Bevor wir uns die einzelnen Einheiten und Veränderungen im RV770 anschauen, stellen wir uns eine Frage, die sicherlich viele Leser interessieren wird. Wie kann man mehr als doppelt so viele ALUs und Textureinheiten verbauen, ohne dass die DIE-Größe und die Anzahl der Transistoren um das Doppelte in die Höhe schnellt? Erst kürzlich hat Nvidias GT200-Chip eindrucksvoll gezeigt, dass solch ein Vorhaben nur bedingt möglich ist.
Wie Eric Demers, Senior Architect bei ATi, uns gegenüber in einem Gespräch verriet, ist der nur unterproportional größere DIE primär auf die höhere Anzahl der ALUs zurückzuführen. Auf der anderen Seite hat ATi vor allem Shader-ALUs sowie die GPR-Stacks (General Purpose Register) überarbeitet, sodass diese nun 40 Prozent weniger Platz als auf einem RV670 einnehmen. Zusätzlich fallen die ROPs kleiner aus und man konnte die Größe sämtlicher anderer Einheiten um fünf bis 20 Prozent verringern.
Stream-Processing-Units (SPU):
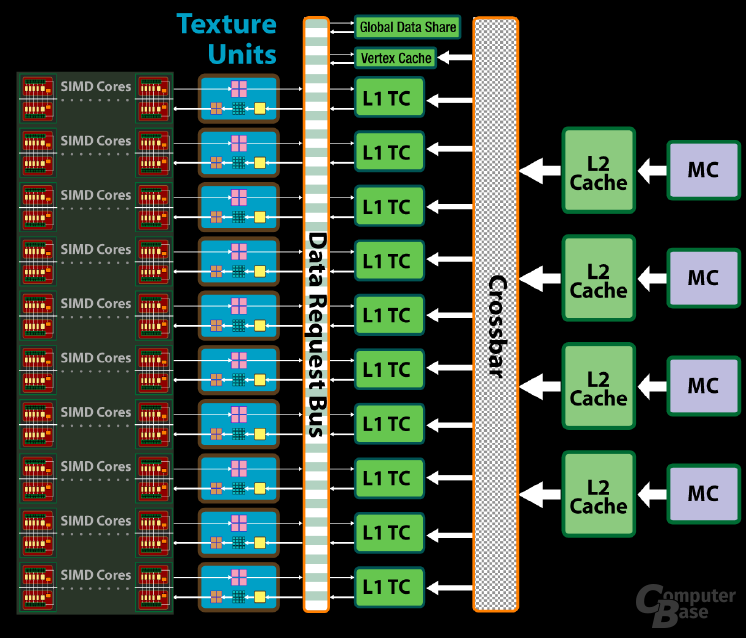
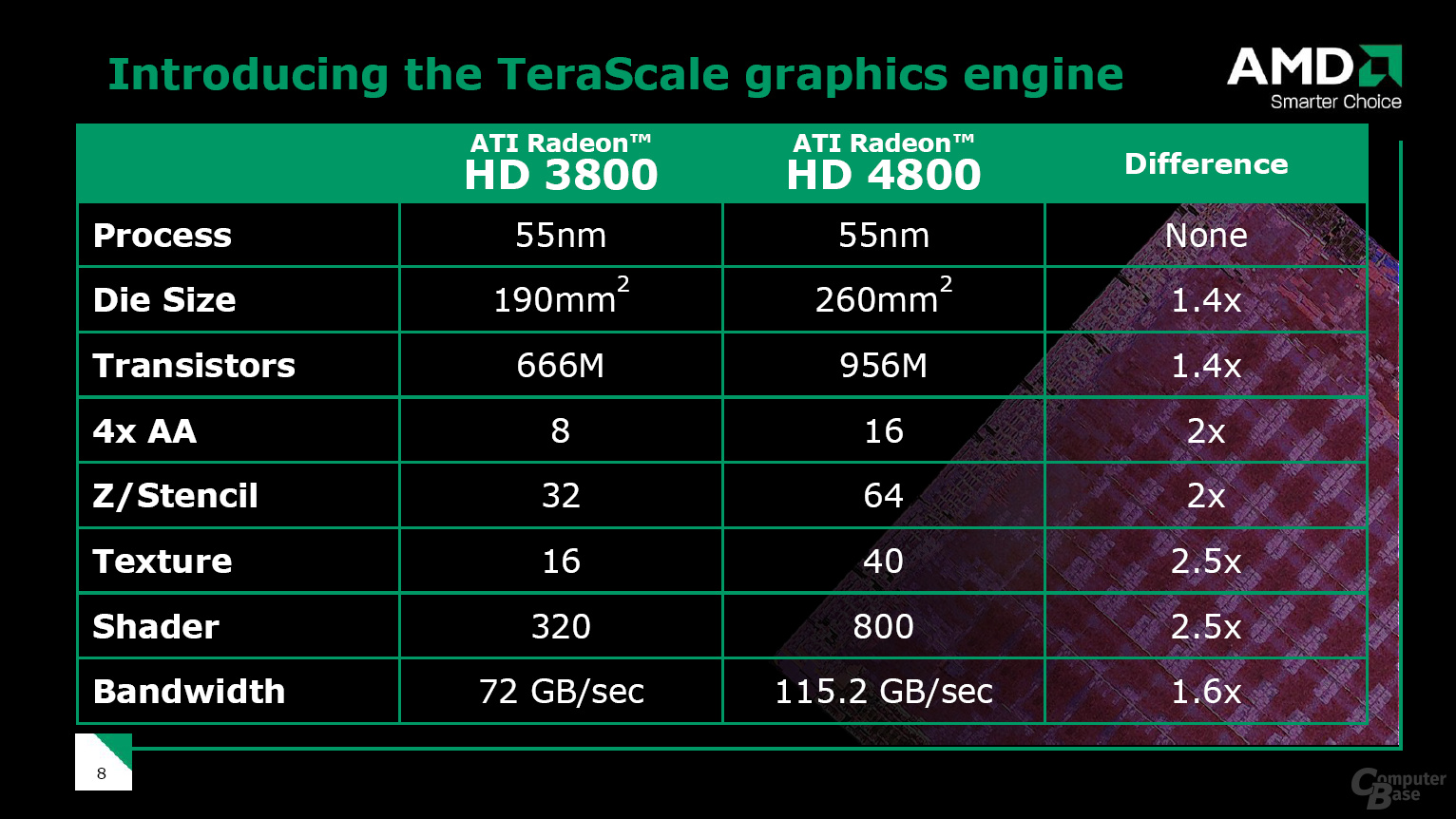
Die Ansteuerung der ALUs im RV770 hat sich nicht geändert. Den Anfang macht die so genannte „Setup Engine“, die die Bits für die Berechnungen in den Stream Processing Units vorbereitet. Je nach Art der Berechnung, die ansteht (Pixel–, Vertex-, oder Geometry-Programm), wird die Kalkulation von einer bestimmten Einheit durchgeführt, wobei alle fertigen Berechnungen anschließend wieder gemeinsam in den „Ultra-Threaded Dispatch Processor“ (UTDP) gelangen. Dieser „Verteilerprozessor“ sorgt dafür, dass die ALUs optimal (möglichst hoch) ausgelastet werden und keine „Blasen“, sprich Leerläufe der ALUs, auftreten.
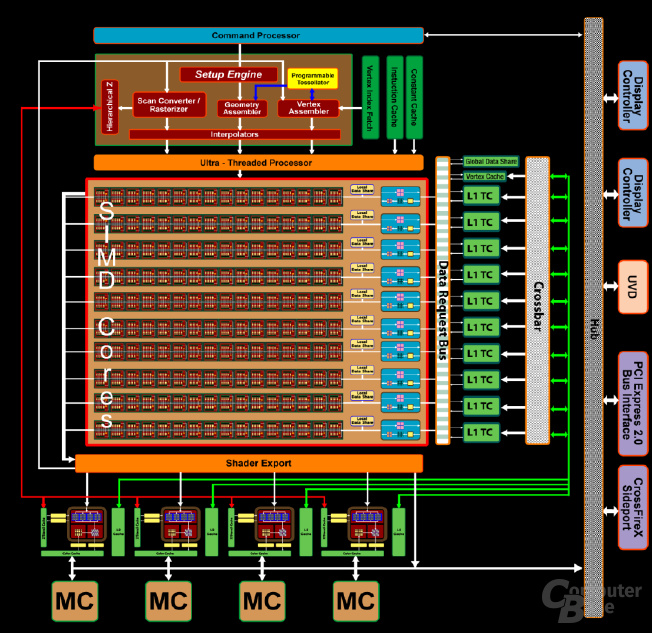
Der UTDP erstellt einzelne Threads, die aus mehreren Befehlen bestehen. Dabei werden mehrere Threads gesammelt, damit die Shaderprogramme in der bestmöglichen Reihenfolge bearbeitet werden können. Die ALUs bauen sich aus zehn SIMD-Blöcken zusammen (Single Instruction, Multiple Data; also auf mehrere Daten kann zeitgleich ein und dieselbe Instruktion angewendet werden), die über jeweils 16 einzelne Shaderkerne sowie einen Textur-Cluster verfügen.
Jeder Shaderkern kann auf einen 16 KB großen Local Data Share zugreifen, um die Daten untereinander schnell auszutauschen zu können weshalb es nicht mehr nötig ist, diese wieder von der CPU anzufordern, falls bereits berechnete Daten erneut gebraucht werden. Vor allem bei GPU-Computing-Berechnungen kann sich solch' eine Art Zwischenspeicher positiv bemerkbar machen. Pro SIMD-Block wird eine Steuereinheit eingesetzt, die die einzelnen ALUs mit einzelnen Threads versorgen kann. Genau Angabe über die Anzahl der Threads macht ATi leider nicht.
Eine Besonderheit der SIMD-Blöcke sollte man noch erwähnen: Jeder SIMD-Block kann mit einem anderen seiner Art mittels eines 16 KB großen „Global Data Share“ kommunizieren. Schon fertiggestellte Daten können also untereinander ausgetauscht werden, ohne dass diese von einem SIMD-Block erneut berechnet werden müssen. Ein Shaderkern ist exakt so aufgebaut wie bei der R600-Generation. Jeder einzelne Kern setzt sich aus fünf einzelnen skalaren ALUs zusammen, die pro Takt jeweils ein MADD berechnen können. Dadurch lassen sich schnell 800 einzelne skalare Shadereinheiten zählen, wobei wir aber lieber von 160 5D-Vektoreinheiten (RGBA, Rot Grün, Blau, den Alphawert und noch eine einzelnes Skalar) sprechen, da die Shaderkerne nicht wie wirkliche Skalareinheiten angesprochen werden können.
Zwar kann jeder Shaderkern die 5D-Einheiten in 1D+1D+1D+1D+1D aufgeteilen, womit man prinzipiell Vektoreinheiten hat, die wie Scalar-Units agieren - dafür müssen die Berechnungen aber komplett unabhängig voneinander sein. Sind diese dagegen abhängig, können längst nicht immer alle ALUs ausgelastet werden und ein Leerlauf entsteht. Eine Aufgabe des Thread-Schedulers ist es, genau diesen Leerlauf so gering wie möglich zu halten. Auf dem Schaubild der ALUs erkennt man, dass eine der fünf Einheiten dicker als die restlichen ist. Die ALU agiert zusätzlich als Special Function Unit (SFU) und berechnet mathematische Operationen wie Sinus-, Kosinus- und Logarithmus-Anweisungen. Zusätzlich ist in einem Shaderkern eine „Branch Execution Unit“ verbaut. Dynamic Branching (Sprunganweisung im Shadercode zum Beispiel durch einen if-/when-Befehl) blockiert also nicht eine MADD-Einheit, sondern wird in einer gesonderten Funktionseinheit berechnet.

Verbessert hat ATi die Rechenleistung jeder ALU was „Bit Shift“-Operationen angeht. Die Leistung wurde um den Faktor 12,5 erhöht. Die Geometryshader-Performance soll einen weiteren guten Schritt nach vorne gemacht haben. Interessanterweise verneinte Eric Demers explizit, dass es im RV770 eine eigene Shaderdomäne mit einem höheren Takt gibt. Die ALUs werden mit derselben Frequenz wie die restlichen Einheiten angesprochen, was laut dem ATi-Ingenieur auch beim R600 und RV670 der Fall sein soll. Bei letzterem ging man bis jetzt davon aus, dass die ALUs leicht schneller angesteuert werden.
Textureinheiten:
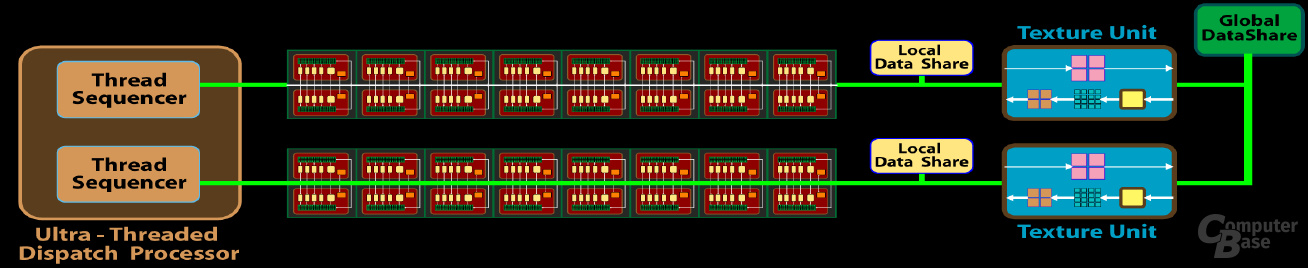
Eng mit den ALUs sind in der RV770-Architektur die Textureinheiten verwandt, da jede einzelne SIMD-Einheit einen Textur-Cluster beinhaltet. Deaktiviert oder entfernt man einen SIMD-Block, gehen einem also auch Textureinheiten verloren. Jeder einzelne Texturcluster setzt sich aus vier einzelnen, vollwertigen Textureinheiten zusammen, womit der RV770 also auf insgesamt 40 TMUs (Texture Mapping Units) zurückgreifen kann. Diese haben sich gegenüber den Vorgängern aber etwas geändert. So können pro Texturcluster zwar weiterhin vier Pixel bilinear texturiert, aber nur noch vier Pixel adressiert werden. Auf einem R600/RV670 war es noch möglich, doppelt so viele Pixel zu adressieren wie zu texturieren.
Da einem Texturcluster nun vier Texture Adressing Units (TAU) fehlen, sinkt auch die Zahl der „Texture Samplers“. Anstatt 20 pro Cluster gibt es deren jetzt nur noch 16. Dies ist aber durchaus zu verschmerzen, da die Texture Samplers zu einem Großteil ihrer Zeit wohl eh ohne Arbeit dastanden. Wie beim R600 kann jeder Texturcluster weiterhin auf einen L1- und einen L2-Cache zurückgreifen. Die Kommunikation des L2- mit dem L1-Cache wird durch den altbekannten Crossbar realisiert. Somit kann jeder Zwischenspeicher ohne Umwege auf jeden anderen seiner Art zugreifen. Modifiziert hat ATi die Bandbreite des Texture Cache, der nun doppelt so schnell wie auf der Vorgänger GPU arbeiten soll. Darüber hinaus konnte man die 32-Bit- (Faktor 2,5) und die 64-Bit-Filterrate (Faktor 1,25) steigern.