GeForce GTX 280 im Test: Neues Nvidia-Flaggschiff lässt die Konkurrenz hinter sich
3/35Technik im Detail Part 1
Allgemeines:
Auch wenn es zuerst den Anschein macht, ist die GT200-GPU kein komplett neu entwickelter Chip, sondern der eigentliche Refresh der G80-GPU, der deutlich überarbeitet und vor allem im Bereich des GPU-Computings erweitert worden ist. Den G92 sehen wir nur bedingt als Refresh-Chip an, da es abseits des kleineren Fertigungsprozesses nur geringe Veränderungen am Chip gegeben hat. Somit bietet der GT200 zu einem Großteil die Vor- und die Nachteile der G80-Architektur, was aber sicherlich alles andere als schlecht ist, da eine entsprechend ausgestattete Grafikkarte wie die GeForce 8800 GTX selbst nach mehr als anderthalb Jahren immer noch nicht zum alten Eisen gehört.
Gleichzeitig hat man aber ebenso einen Nachteil geerbt, und zwar die fehlende Unterstützung von Direct3D 10.1. Stattdessen bleibt man bei der Direct3D-10-API stehen, was im Moment aufgrund fehlender Software kein Nachteil ist, was sich aber durchaus in einigen Monaten ändern kann. Assassin's Creed hat in der Ursprungsversion schon einen kleinen Ausblick darauf gegeben, was man mit Direct3D 10.1 für Vorteile gegenüber der Grund-API erreichen kann.

Die GT200-GPU wird erneut bei TSMC gefertigt und weiterhin im altbewährten 65-nm-Prozess hergestellt. Mit einem 55-nm-Chip würde man Wafer-Fläche (und damit Geld) sparen, jedoch kann es dann schnell zu Fertigungsproblemen kommen, da eine größtenteils neue Architektur auf einem noch unbekannten Fertigungsprozess erfahrungsgemäß kritisch ist. Die Zahl der Transistoren beläuft sich auf satte 1,4 Milliarden, womit man die Schaltkreise gegenüber dem G80 mehr als verdoppelt hat – ein Großteil davon wurde in die Verbesserung der GPU-Computing-Fähigkeiten gesteckt.
Der GT200 wird auf der GeForce-GTX-200-Serie eingesetzt, die aus zwei verschiedenen Modellen besteht: die GeForce GTX 260 sowie die GeForce GTX 280. Beide unterscheiden sich nicht nur in den Taktraten, sondern ebenfalls in der Anzahl der Ausführungseinheiten, die auf der GeForce GTX 260 teilweise deaktiviert, physikalisch aber noch vorhanden sind. Die Eckdaten der GT200-GPU hören sich beeindruckend an: 240 Shader-, 80 Textureinheiten, 32 ROPs, ein 512 Bit breites Speicherinterface und einen Gigabyte großen Framebuffer. Doch was für Veränderungen hat es in der internen Organisation gegeben?

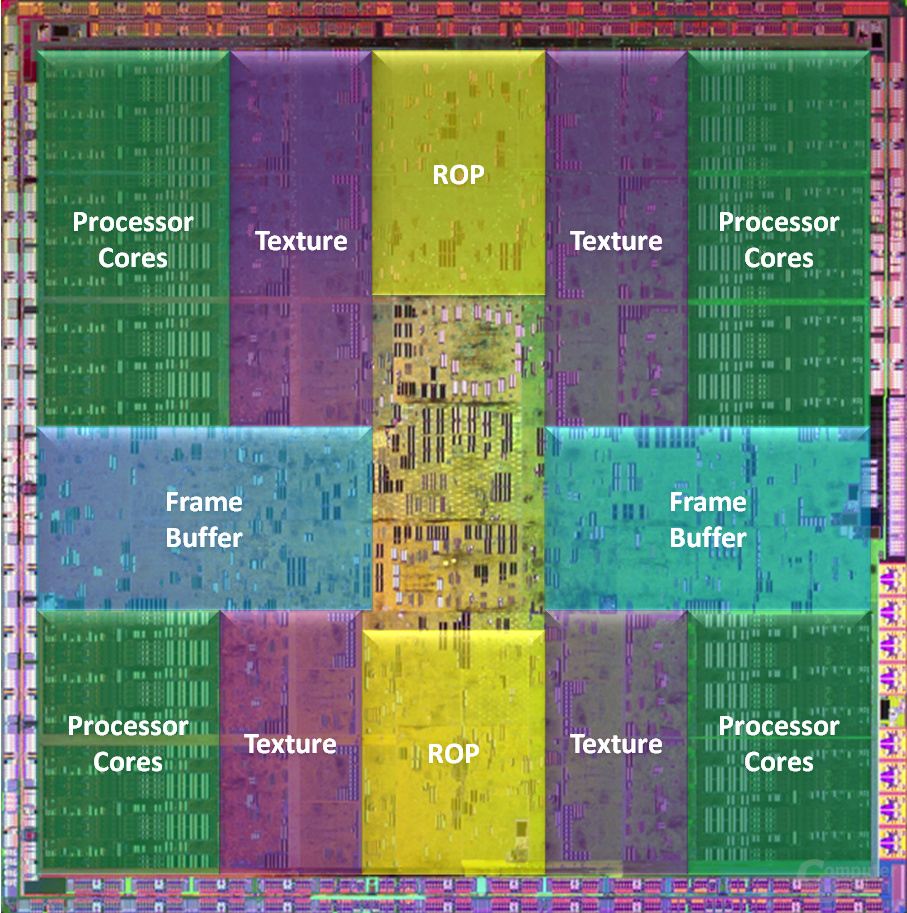
Der GT200 bietet erstmals zwei verschiedene Betrachtungsweisen der Architektur an, je nachdem was auf der Grafikkarte ausgeführt wird. Nvidia spricht deswegen gerne von zwei verschiedenen Betriebsmodi, in denen dieselben Einheiten auf teils unterschiedliche Namen hören. So gibt es den „Graphics Processing Mode“ (GPM), der in einer herkömmlichen 3D-Anwendung zum Einsatz kommt, sowie einen „Parallel Compute Mode“ (PCM) für GPU-Computing-Berechnungen mittels CUDA.
Streaming Multiprocessors (SM):
Der GT200 verfügt über 240 skalare Shadereinheiten, die Nvidia auf den Namen Streaming Processors (SP) getauft hat und die pro Takt einen Farbwert (Rot, Grün, Blau oder Alphawert) berechnen können. Dabei hat man aber nicht nur Stur die Anzahl der Einheiten beziehungsweise der Shadercluster erhöht, sondern zudem die interne Organisation etwas verändert. Ein Shadercluster auf dem G80 besteht aus insgesamt 16 einzelnen ALUs, die wiederum in zwei Achter-Blöcke aufgeteilt sind. Der GT200 baut nun immer noch auf dasselbe Konzept auf, wobei die Kalifornier aber zehn Shadercluster (TPC, Texture Processing Cluster im GPM; Thread Processing Cluster im PCM) verbauen.
Bei diesen wurde die Anzahl der „Streaming Multiprocessors (SM)“ von zwei auf drei erweitert – es gibt also nicht mehr zwei sondern drei ALU-Blöcke –, wobei die Menge der „Stream Processors (SP)“, sprich der einzelnen ALUs, gleich geblieben ist. Somit kommt man nun auf 240 Shadereinheiten, da jeder Shadercluster auf 24 einzelne ALUs zurückgreifen kann und es zehn Cluster gibt. Jeder Streaming Multiprocessor verwaltet insgesamt acht ALUs, die in zwei Vierer-Blöcke aufgeteilt sind.
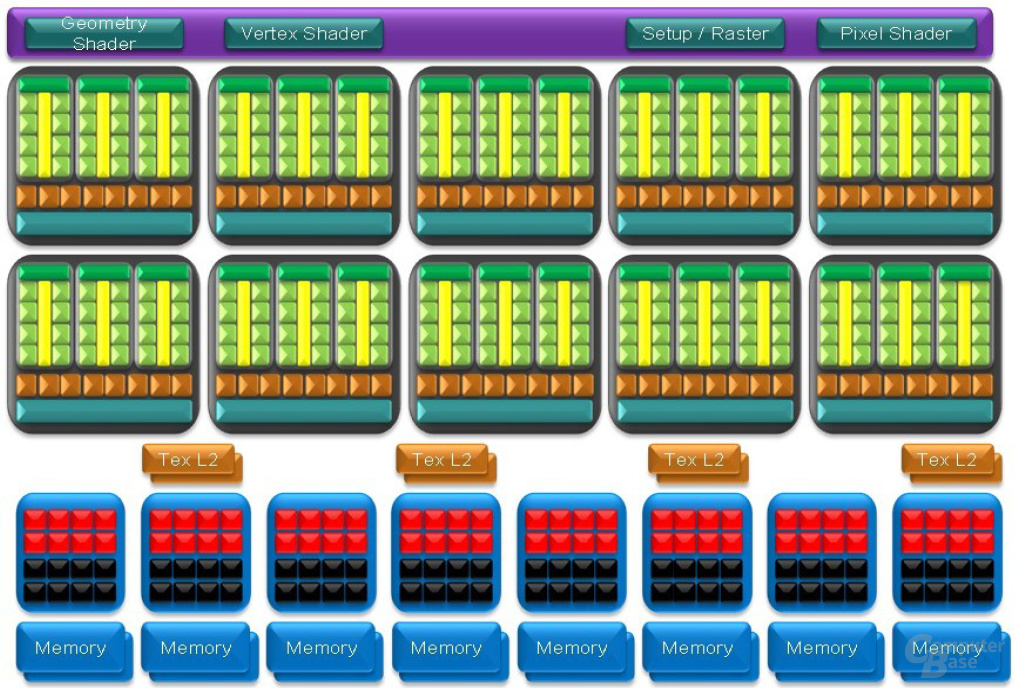
Eine Neuerung im GT200 ist ein 16k großer Local-Memory-Speicher, der genau zwischen den vier ALUs platziert ist und auf die die Recheneinheiten zugreifen können. Somit kann eine ALU die fertig berechneten Daten in dem Zwischenspeicher ablegen, auf die eine andere ALU dann zu einem späteren Zeitpunkt zurückgreifen kann und der GT200 so den langsameren Umweg über den externen Speicher spart. Vor allem bei GPU-Computing und bei der Physikbeschleunigung soll der Zwischenspeicher einen großen Performanceschub bringen.
Eine reine Erhöhung der Recheneinheiten nutzt aber nichts, wenn man diese nicht auslasten kann. Dazu hat Nvidia den Thread Scheduler verbessert, der die einzelnen Streaming Processors mit den Rohdaten füttert. Jeder Streaming Multiprocessor auf dem GT200 kann dazu Threads in Gruppen von 32 parallelen Threads („Warps“) erzeugen, verwalten und ausführen. Der G80 war dagegen auf 24 Warps beschränkt, womit die Zahl der ausführbaren Threads auf dem GT200 von 12.228 auf 30.720 gestiegen ist.
Die Kommunikation zwischen den einzelnen Shadercluster erfolgt mittels MIMD (Multiple Instruction, Multiple Data), es können also mehrere Berechnungen auf mehrere Daten angewendet werden. Unter den einzelnen Streaming Multiprocessors herrscht dagegen SIMT (Single Instruction, Multiple Threads), was stark an SIMD angelehnt ist (Single Instruction, Multiple Data). Gleichzeitig legt dies ein ganz interessantes Detail an die Oberfläche.
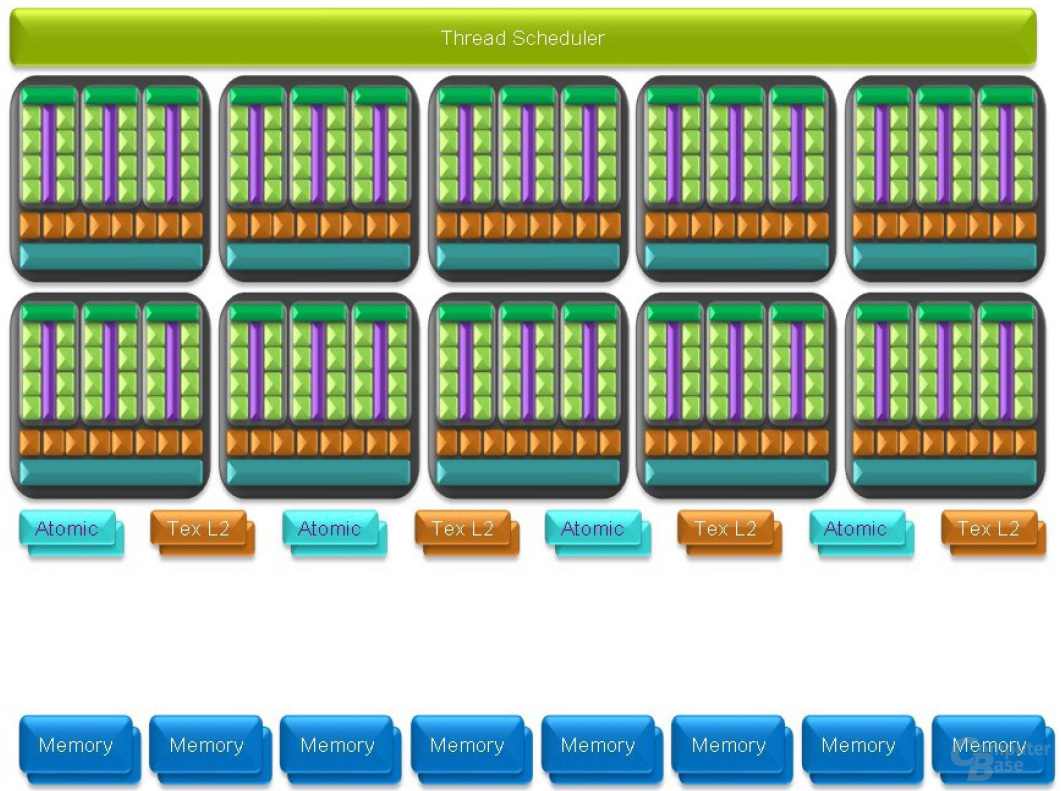
Die ALUs vom GT200 sind, wie bereits erwähnt, skalare Einheiten. Das heißt, dass jede ALU pro Rechentakt eine einzelne Komponente (Rot, Grün, Blau oder Alphawert) berechnen kann. Jeder einzelne Shadercluster kann auf dem GT200 pro Taktzyklus nun mit unterschiedlichen Komponenten versorgt werden, je nach dem welche gerade am dringendsten benötigt wird. Die Shadercluster an sich sind also völlig flexibel. Etwas starrer scheinen dagegen die Streaming Multiprocessors zu sein, die aufgrund von SIMT pro Takt auf sämtliche ALUs also nur ein und dieselbe Komponente berechnen können. Es ist somit nicht möglich, dass innerhalb eines Shadercluster in einem Takt verschiedene Komponenten berechnet werden können. Nach einem Takt können die skalaren ALUs dann aber wieder einen anderen Farbwert berechnen. Nichtsdestotrotz sollen die SM aufgrund des effizienten Thread Schedulings beinahe durch die Bank voll ausgelastet sein.
Jede einzelne ALU kann auf dem G80 pro Takt ein MADD (Multiplikation sowie Addition) sowie ein MUL (Multiplikation) berechnen. Das hat sich auf dem GT200 nicht geändert, jedoch konnte man die Auslastung massiv steigern. Während das MADD auf dem G80 komplett für „General Shading“ genutzt werden kann, hat das zweite MUL meistens andere Aufgaben und kümmert sich um die Perspektivenkorrektur oder arbeitet als Attributinterpolator oder Special-Function-Unit (SFU). Die MUL-Leistung für das General Shading beträgt auf dem G80 geringe 15 Prozent, was sich nur in seltenen Fällen bemerkbar macht.
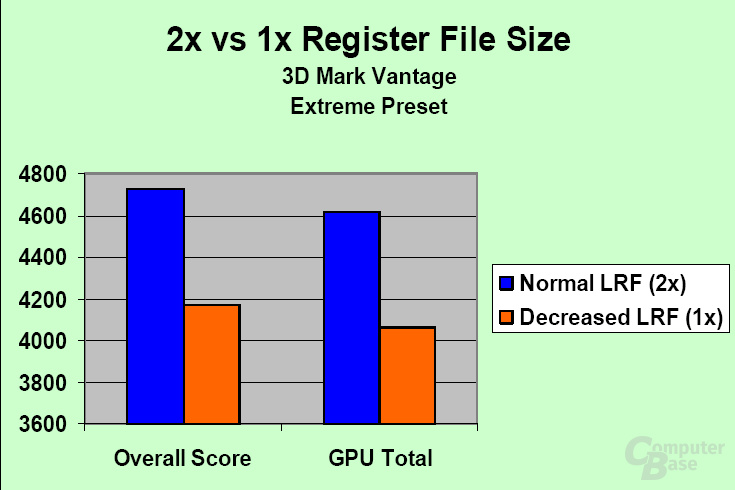
Der GT200 kann dagegen das MUL in etwa zu 93 Prozent bis 94 Prozent für General Shading benutzen, weswegen man die theoretischen GFLOPS-Angaben zwischen den beiden Architekturen nur bedingt miteinander vergleichen kann. Wie der GT200 nun die SFU-Aufgaben erledigt, ist aber noch unklar. Logischerweise entfallen die Aufgaben auf einem GT200 nicht. Zusätzlich hat Nvidia die Registergröße pro Streaming Multiprocessor auf einem GT200 verdoppelt. Bei langen sowie komplexen Shaderprogrammen soll es die GPU so vermeiden können, die Daten auf den Speicher zu „swappen“.
Zu guter Letzt wurde nach eigenen Angaben die Geometry-Shader- sowie die Stream-Out-Performance stark erhöht.