webmark487
Newbie
- Registriert
- März 2024
- Beiträge
- 7
Hallo,
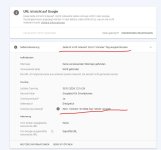
Die Webseite christian-ostermann.com wurde von mir vor ca. 1 Monat online geschalten, sie ist immer noch nicht indexiert.
GSC sagt "Seite ist nicht indexiert: Durch "noindex"-Tag ausgeschlossen".
Siehe attachment.
Ich habe schon alles (mir) Mögliche versucht, keine Ahnung, warum sie nicht indexiert wird.
Bitte um Hilfe, Danke im Voraus.
Freundliche Grüße
Markus
Die Webseite christian-ostermann.com wurde von mir vor ca. 1 Monat online geschalten, sie ist immer noch nicht indexiert.
GSC sagt "Seite ist nicht indexiert: Durch "noindex"-Tag ausgeschlossen".
Siehe attachment.
Ich habe schon alles (mir) Mögliche versucht, keine Ahnung, warum sie nicht indexiert wird.
Bitte um Hilfe, Danke im Voraus.
Freundliche Grüße
Markus