ATi Radeon X1800, X1600 und X1300 im Test: Der High-End-Grafikchip R520 unter der Lupe
3/26Technik im Detail
Der R520-Chip verfügt mit 321 Millionen Transistoren über deutlich mehr Schalteinheiten, als man aufgrund der nur 16 Pixel-Pipelines vermuten könnte. Weiterhin verfügt er über insgesamt acht Vertex-Shader-Einheiten, 16 ROPs und ebensovielen Texture Mapping Units. Als erster Desktop-Grafikchip verwenden der R520 sowie die kleineren Derivate erstmals den 90-nm-Prozess von TSMC, der nicht nur höhere Taktraten, sondern auch einen niedrigeren Stromverbrauch ermöglichen soll. Jener wird darüber hinaus durch eine erhöhte Flexibilität des R5x0 erreicht: Bei jenem ist es kein Problem, nicht mehr nur einzelne Pixel-Pipelines zu deaktivieren, ebenso lassen sich die Vertex-Shader, TMUs, ROPs und weitere Einheiten problemlos abschalten, um so ein- und denselben Chip für langsamere Grafikchips zu verwenden. Zudem verfügt der Chip über die Fähigkeit, sich im 2D-Modus herunterzutakten und zudem den gesamten 3D-Part zu deaktivieren, womit der Stromverbrauch unter der Windows-Oberfläche und 2D-Anwendungen stark gesenkt werden soll.
Der RV530, der in der Radeon X1600-Serie verbaut wird, wurde von ATi deutlich abgespeckt, weswegen der Chip nur noch eine ungefähre Größe von 180 Millionen Transistoren besitzt. Erreicht wird dies unter anderem durch die Reduzierung auf 12 Pixel- und fünf Vertex-Pipelines, zudem verfügt der Pixelbeschleuniger insgesamt nur noch über vier Texture Mapping Units sowie vier ROPs. Die Radeon X1300-Reihe mit dem RV515-Chip setzt noch einen drauf und besitzt nur noch zirka 100 Millionen Transistoren. Zusätzlich wurden noch weitere Pixel-Quads entfernt, womit das Silizium nur noch vier Pixel-Pipelines besitzt. Die ROPs und TMUs sind immer noch vierfach vorhanden, allerdings kann der RV515 nur noch mit zwei Vertex-Pipelines umgehen. Ansonsten sind die drei Chips größtenteils identisch aufgebaut.



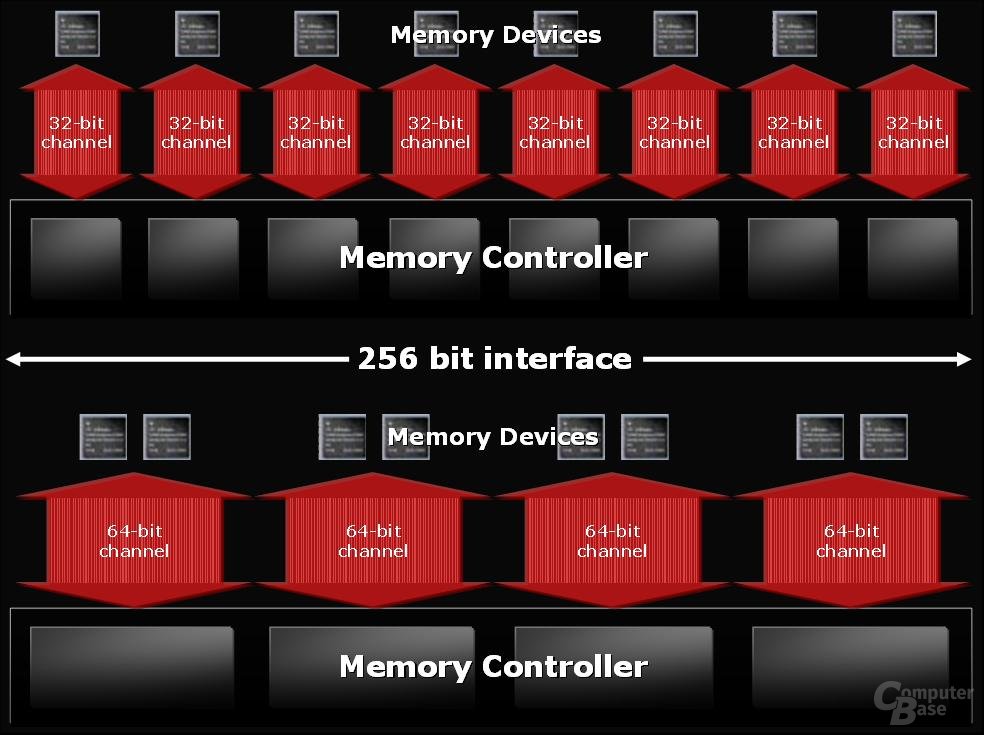
Komplett neu bei allen drei Versionen der R520-Generation ist der sogenannte „Ring-Bus“, welcher ein neuartiges Speicherinterface bezeichnet. Während beim R420 das 256-bitige Memoryinterface mit Hilfe von vier 64 Bit breiten Kanälen arbeitete, gibt es beim Ring-Bus eine Aufteilung in acht Kanäle, die jeweils 32 Bit groß sind. Da jeder diese Kanäle gleichzeitig eine Lese- oder Schreibanfrage bearbeiten kann, kann der neue Ring-Bus innerhalb kürzerer Zeit die selben Daten verarbeiten wie ATis bisheriges Speicherinterface. Somit verringert sich die Latenz, sprich die Performance erhöht sich. Darüber hinaus ist der neue Ring-Bus fähig, jeglichen zur Zeit auf dem Markt befindlichen DDR-Speicher anzusteuern und ebenso den in der Zukunft erscheinenden GDDR4-Speicher.
Um die Effizienz des Memoryinterfaces zu erhöhen, setzen die Entwickler der R5x0-Generation auf mehrere Memory-Clients, welche die ankommenden Speicheranfragen bearbeiten und wieder losschicken können. Damit jene nicht auf eine komplexe Anbindung angewiesen sind, die die Komplexität, Hitze und Latenz extrem steigern würden, wird der so genannte Ring-Bus eingesetzt, der Namensgeber des neuen Interfaces. Dieser Bus umschließt alle Memory-Klienten ringförmig, um so den zurückzulegenden Weg gering zu halten. Dabei bestehen diese Ringe aus zwei 256 Bit breiten Datenleitungen – daher auch die Bezeichnung 512-Bit-Bus –, die jeweils in die entgegengesetzte Richtung kommunizieren, um so die Latenz ein weiteres Stück zu minimieren. Wenn die Daten über den Ring-Bus transportiert werden, können sie insgesamt an vier „Ring Stop“-Leitungen die Daten „abliefern“ und diese schicken die Informationen weiter an den Speicher.

Ebenfalls neu ist die Verbesserung der hauseigenen Texturkompression 3Dc, wobei der Nachfolger auf den simplen Namen „3Dc+“ hört. 3Dc+ ist nun auch in der Lage, acht Bit Integer Texturen mit einer Kompressionsrate von 2:1 zu verkleinern. Ebenso wurden die von ATi implementierten HyperZ-Funktionen zur Entfernung von Pixeln, die in einem nicht sichtbaren Bereich liegen und somit unnötig Bandbreite verschwenden, weiter verbessert. So soll bei der Radeon-X1800-Serie unter anderem die HierarchicalZ-Berechnungen um bis zu 50 Prozent beschleunigt worden sein. HierarchicalZ ist die erste Stufe der Berechnung von nicht sichtbaren Pixeln. Zuerst wird jeder Pixel in einen Block kleinerer Pixel unterteilt, die einzeln auf Sichtbarkeit untersucht werden. Während Blöcke, die komplett unsichtbar sind, direkt verworfen werden, werden komplett oder teils sichtbare Pixelblöcke weiter in die Pixel-Engine geleitet.
Wie es seit dem NV4x bereits jeder Grafikchip von nVidia ist, ist auch die R5x0-Familie fähig, Pixel- und Vertex-Shader Befehle der Version 3.0 zu verarbeiten. Ein Teil des Shader-Models 3.0 ist das sogenannte „Dynamic Branching“, welches laut ATi einer der wichtigsten Bestandteile der neuesten Shader-Version darstellt und auf dem R5x0 auch sehr schnell laufen soll. So ist es mit Dynamic Branching dem Spieleentwickler theoretisch möglich, einen langen, einzelnen Shader zu schreiben, der dank dem Feature dennoch schnell abgearbeitet werden kann. So entscheidet die Karte, ob der Shader-Code komplett ausgeführt werden muss oder nicht benötigte Codeteile einfach übersprungen werden können. Während der NV4x und G70 relativ viele Takte benötigen, um so einen Sprung zu vollführen, soll der R520 entsprechend wenige Zyklen benötigen, um dynamisch durch den Shader-Code springen zu können.
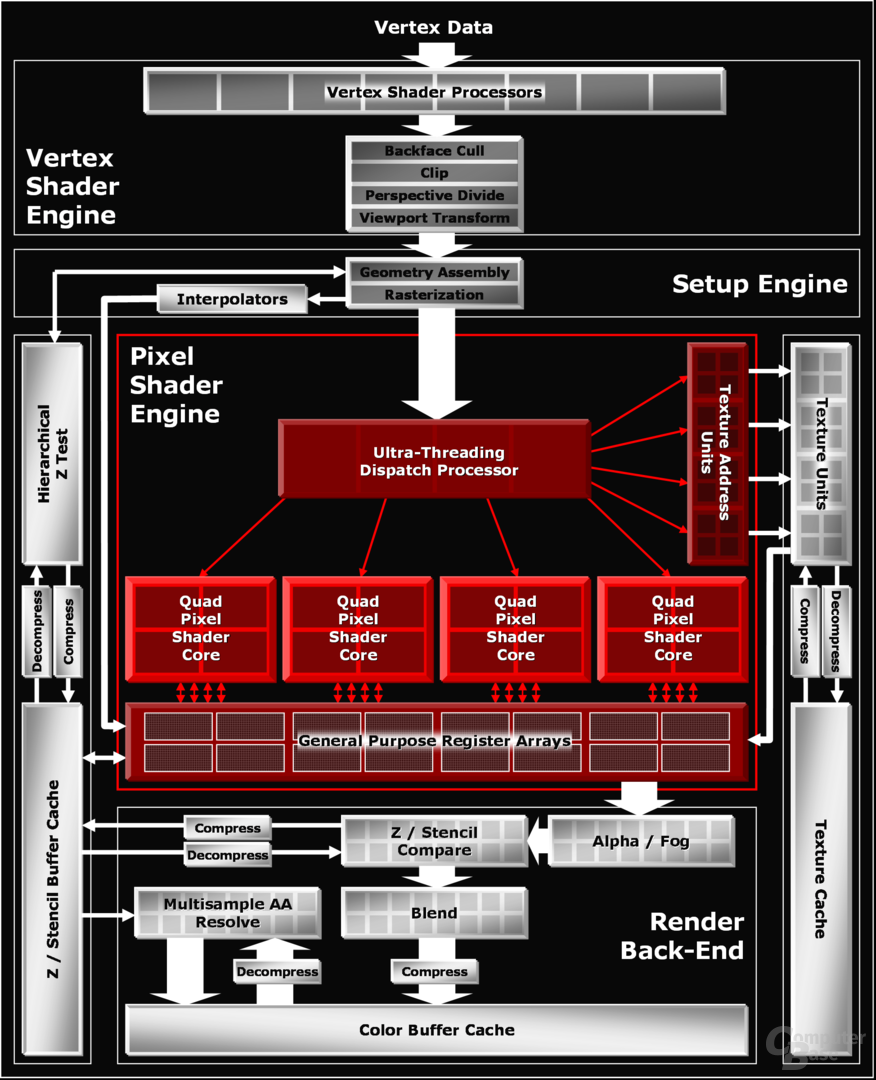
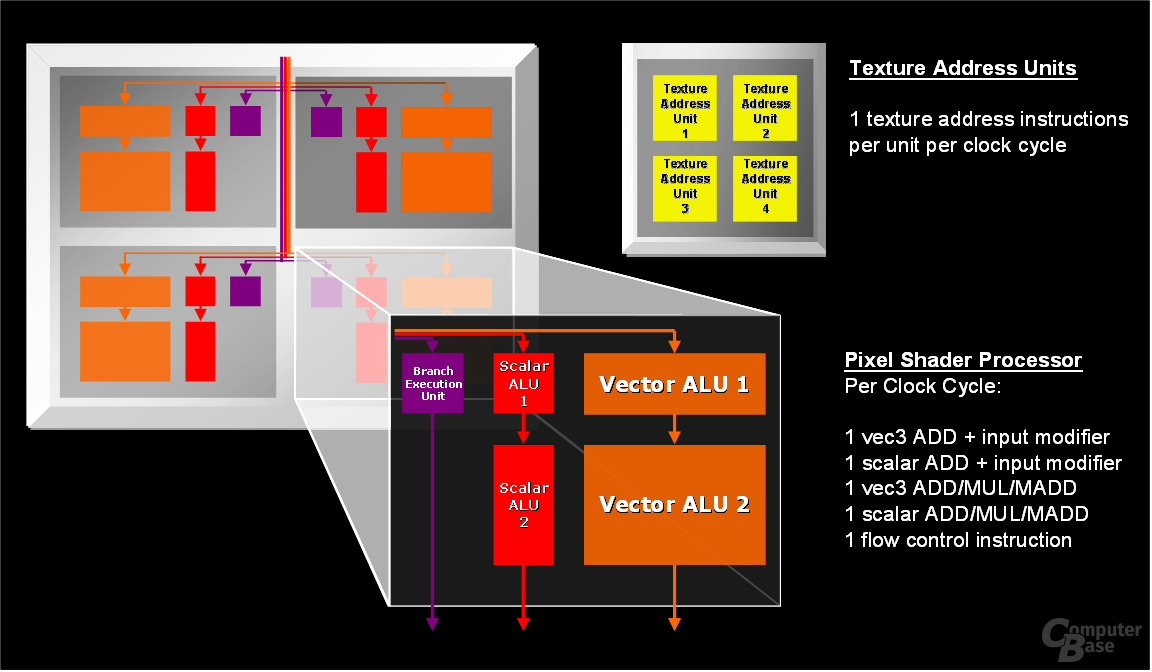
Weiterhin wurde die Pixel-Pipeline und ebenso der Vertex-Shader optimiert, so dass sich größtenteils die Latenz verringert, um ohne Wartezeiten Daten verarbeiten zu können. Alle diese hier zu erklären würde allerdings den Artikel ins unendliche verlängern, weswegen wir nur die wichtigsten Folien abbilden werden. Weiter möchten wir aber noch zwei wichtige Änderungen gegenüber dem Vorgänger R4x0 erläutern: So rendert der R5x0 jeglichen Shadercode mit voller FP32-Genauigkeit und kann nicht, wie die nVidia-Pendants, auf halbe Präzision (FP16) zurückschalten, um so den Shadercode schneller ausführen zu können, jedoch je nach Shader auch an Bildqualität zu verlieren. Laut den ATi-Ingenieuren kann der R5x0 mit voller Präzision genauso schnell rendern wie mit Partial Precision, weswegen letzteres auf den ATi-Chips nicht zur Verfügung steht.
Zu guter Letzt verfügt die Radeon-X1k-Serie über ein wichtiges Feature, welches die Konkurrenz nicht bietet: So läuft auf entsprechenden Chips 64-bitiges FP-High-Dynamic-Range-Rendering inklusive Multi-Sampling-Anti-Aliasing. Zwar müssen die Spiele angepasst werden, laut den Crytek-Programmierern soll dies aber recht schnell möglich sein – so lief auf der Präsentation eine spezielle Version von Far Cry mit HDR sowie Anti-Aliasing einwandfrei und vor allem sehr flüssig.