Arm-Kerne 2023: Cortex-X4, A720 und A520 bilden reine 64‑Bit-Plattform

Arm trennt sich endlich von allen 32-Bit-Altlasten, steigert abermals Leistung und Effizienz und bietet mehr Flexibilität bei der Zusammenstellung. Cortex-X4, Cortex-A720 und Cortex-A520 sind die neuen CPU-Kerne, die dieses und nächstes Jahr in neuen Prozessoren vor allem für Smartphones mit Android zum Einsatz kommen werden.
Die neuen CPU-Kerne sind ein Baustein der Total Compute Solutions 2023 (TCS23), die auch Bereiche wie das neue DSU-120-Cluster, in dem die CPU-Kerne in verschiedenen Konfigurationen untergebracht werden können, die Grafikeinheit und die verschiedenen Interconnects von Arm umfasst. Was Anwender für 2023 erwarten können, hatte Arm bereits letztes Jahr anhand einer Roadmap im Groben in Aussicht gestellt, wenngleich damals anstelle der exakten Produkt- noch Codenamen zum Einsatz kamen. Diese Roadmap hat Arm zur Ankündigung der neuen IP diesmal nicht erweitert, sodass ein Ausblick auf die TCS24 abermals das Ende der öffentlichen Roadmap bedeutet.
Arm TCS23 im Überblick
Aus den Codenamen der TCS23 im letzten Jahr sind mit der heutigen Ankündigung aus „CXC23“ der neue Big-Core Cortex-X4, aus „Hunter“ der neue Mid-Core Cortex-A720 und aus „Hayes“ der neue Little-Core Cortex-A520 geworden. Es handelt sich um die Nachfolger der bei zahlreichen SoCs aktueller Smartphones zum Einsatz kommenden CPU-Kerne Cortex-X3, Cortex-A715 und Cortex-A510 Refresh. Mit ersten Ankündigungen auf Basis der neuen Lösungen ist noch dieses Jahr zu rechnen, im größeren Umfang dürften entsprechend ausgestattete Smartphones, Tablets und Notebooks aber erst im nächsten Jahr auf den Markt kommen, wenn die Chips verfügbar sind. Zur Erinnerung: Arm entwickelt „lediglich“ die Designs, keine eigenen Chips, lizenzieren und implementieren müssen diese Anbieter wie Google, MediaTek, Qualcomm oder Samsung.

Vorschau auf die TCS24
Im kommenden Jahr soll innerhalb desselben DSU-120-Clusters ein neuer Big-Core namens „Blackhawk“ zum Einsatz kommen, während als Mid-Core der „Chaberton“ geplant ist. Beim Little-Core soll jedoch der Cortex-A520 fortgeführt werden. Die MMU-700 (Memory Management Unit) will Arm ebenfalls übernehmen, die beiden Interconnects CI-700 und NI-700 sollen mit „Tower“ zu einer Einheit verschmelzen. Und mit „Krake“ steht auch ein Nachfolger der neuen Immortalis-G720 als Grafikeinheit an.
Mehr Leistung und/oder Effizienz für alle Kerne
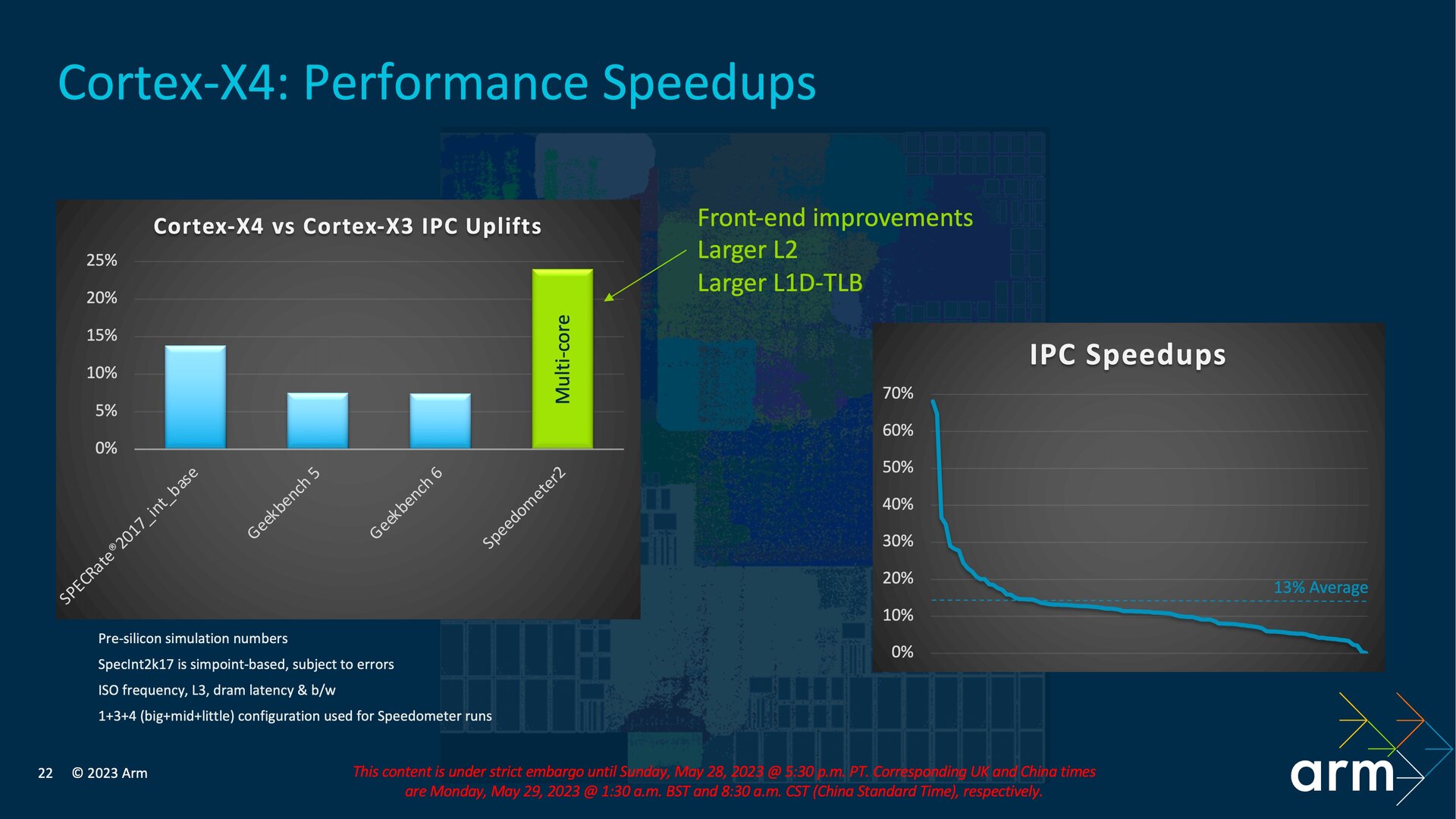
Bevor im weiteren Verlauf des Artikels Details der einzelnen Lösungen folgen, eine kurze Übersicht der von Arm beworbenen Verbesserungen aufseiten der CPU-Kerne. Im Vergleich zur TCS22 soll der Cortex-X4 15 Prozent mehr Leistung liefern oder bei gleicher Leistung den Verbrauch um 40 Prozent reduzieren. SoC-Anbieter können sich aussuchen, wie sie die Optimierungen bei ihren Implementierungen umsetzen. Für den Cortex-A720 gibt Arm eine um 20 Prozent verbesserte Energieeffizienz bei gleicher Leistung an und für den Cortex-A520 liege das Plus bei 22 Prozent bei gleicher Leistung.
-
 Übersicht der Verbesserungen (Bild: Arm)
Übersicht der Verbesserungen (Bild: Arm)

Tape-out für den Cortex-X4 bei TSMC in N3E
In die Designs von Arm fließen auch Optimierungen für die Fertigung unter Verwendung modernster Nodes ein. Speziell für die TCS23 hat das Unternehmen mit TSMC zusammengearbeitet und vermeldet heute den industrieweit ersten Tape-out in N3E speziell für den Cortex-X4. Prozentuale Angaben zur Verbesserungen der eigenen Lösungen sind bei Arm jedoch stets als „ISO“, also gleiche Werte in Bezug auf Fertigung, Caches oder Taktraten zu verstehen, sodass weitere Zugewinne aus diesen Bereichen als „icing on the cake“, also als zusätzlicher Bonus zum neuen Design, bedacht werden müssen.

Eine reine 64-Bit-Plattform mit Armv9.2
Die TCS23 ist elf Jahre nach dem ersten Schritt mit dem Cortex-A57 endlich eine reine 64-Bit-Plattform, da jetzt auch dem letzten Kern der Support von AArch32 entzogen wurde. Bis alle Kerne von Arm mit 64-Bit-Support verfügbar waren, hat es zwar nicht lange gedauert, bis alle Kerne jedoch vollständig und ohne die bis zuletzt noch mögliche optionale Konfiguration des Cortex-A510 ihren 32-Bit-Support verloren haben, hat bis zur aktuellen TCS23 gedauert. Vom Cortex-X1 zum Cortex-X2 flog AArch32 beim Big-Core raus und vom Cortex-A710 zum Cortex-A715 war dies später ebenso beim Mid-Core der Fall.

Der erste Cortex-A510 der TCS21 war ebenso auf AArch64 beschränkt, mit dem letztjährigen Cortex-A510 Refresh gab es aber wieder eine Option auf AArch32, weil dieser Support dem Mid-Core entzogen wurde und gewisse Märkte wie insbesondere China noch auf den 32-Bit-Support angewiesen waren, da dort im Gegensatz zum Google Play Store, der 64-Bit-Apps bereits seit längerem zur Pflicht macht, mit den verschiedenen Hersteller-Stores noch kein solch kohärenter 64-Bit-Markt anzutreffen war. Das habe sich laut Arm jedoch zwischenzeitlich geändert, sodass jetzt 95 Prozent der 3.000 beliebtesten Apps Chinas in 64-Bit-Versionen vorliegen würden. Die TCS23 trennt sich somit auf allen Kernen von jeglichen 32-Bit-Altlasten und ist damit (für Lizenznehmer respektive Consumer) die erste reine 64-Bit-Plattform von Arm.
DSU-120: Erweiterung auf 14 Kerne
Alle Kerne in der DynamIQ Shared Unit (DSU) entsprechen jetzt der Armv9.2 ISA (Instruction Set Architecture) und können praktisch nicht mehr mit älteren Varianten gemischt werden. Die ISA ist der gemeinsame Nenner, den es von den Chip-Designern einzuhalten gilt. Apropos DSU: Dort sind mit der TCS23 bzw. der neuen DSU-120 neue Konfigurationen möglich, die über die Anzahl der bislang maximal unterstützten Kerne hinausgehen. Außerdem könnte es passieren, dass Chip-Entwickler von dem bislang für Smartphones üblichen Aufbau mit 1+3+4 Kernen (Big/Mid/Little) abweichen werden.
Die DSU-120 basiert auf der Mikroarchitektur der vorherigen DSU-110, die bei der TCS22 und TCS21 zum Einsatz kam, bringt aber eine Reihe von Optimierungen und Erweiterungen mit, die für mehr Flexibilität sorgen und die Energieeffizienz steigern. Eine der offensichtlichen Veränderungen ist die Erhöhung der maximal unterstützten CPU-Kerne pro DSU von 12 auf 14. Möglich werden dadurch neue SoC-Designs, die vor allem Formfaktoren wie Notebooks betreffen, wo es künftig einen Aufbau wie 10+4+0 geben könnte. An dieser Stelle muss man allerdings einwerfen, dass schon die früheren Core-Erweiterungen der DSU nicht zu entsprechenden Produkten geführt haben. Mit dem Qualcomm Snapdragon 8cx Gen 3 gibt es lediglich ein 4+4+0-Design, das aber noch auf Cortex-X1 und Cortex-A78 setzt. Warum sich die SoC-Anbieter speziell im Segment der Notebooks so zögerlich beim Einsatz neuer und vor allem von mehr Kernen zeigen, darauf wollte Arm mit Verweis auf die involvierten Unternehmen nicht eingehen.
-
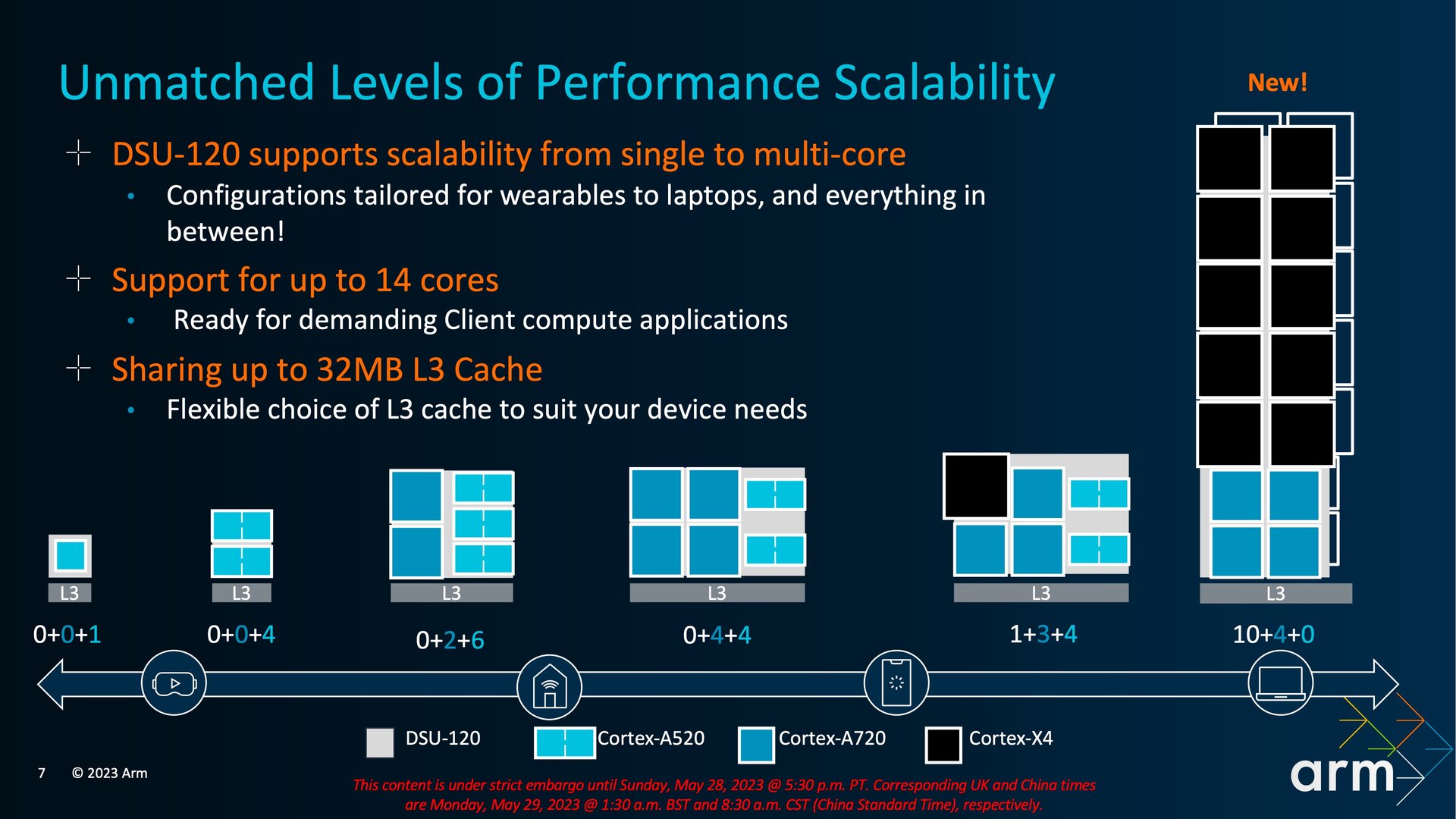 Neue Konfigurationen mit der DSU-120 (Bild: Arm)
Neue Konfigurationen mit der DSU-120 (Bild: Arm)

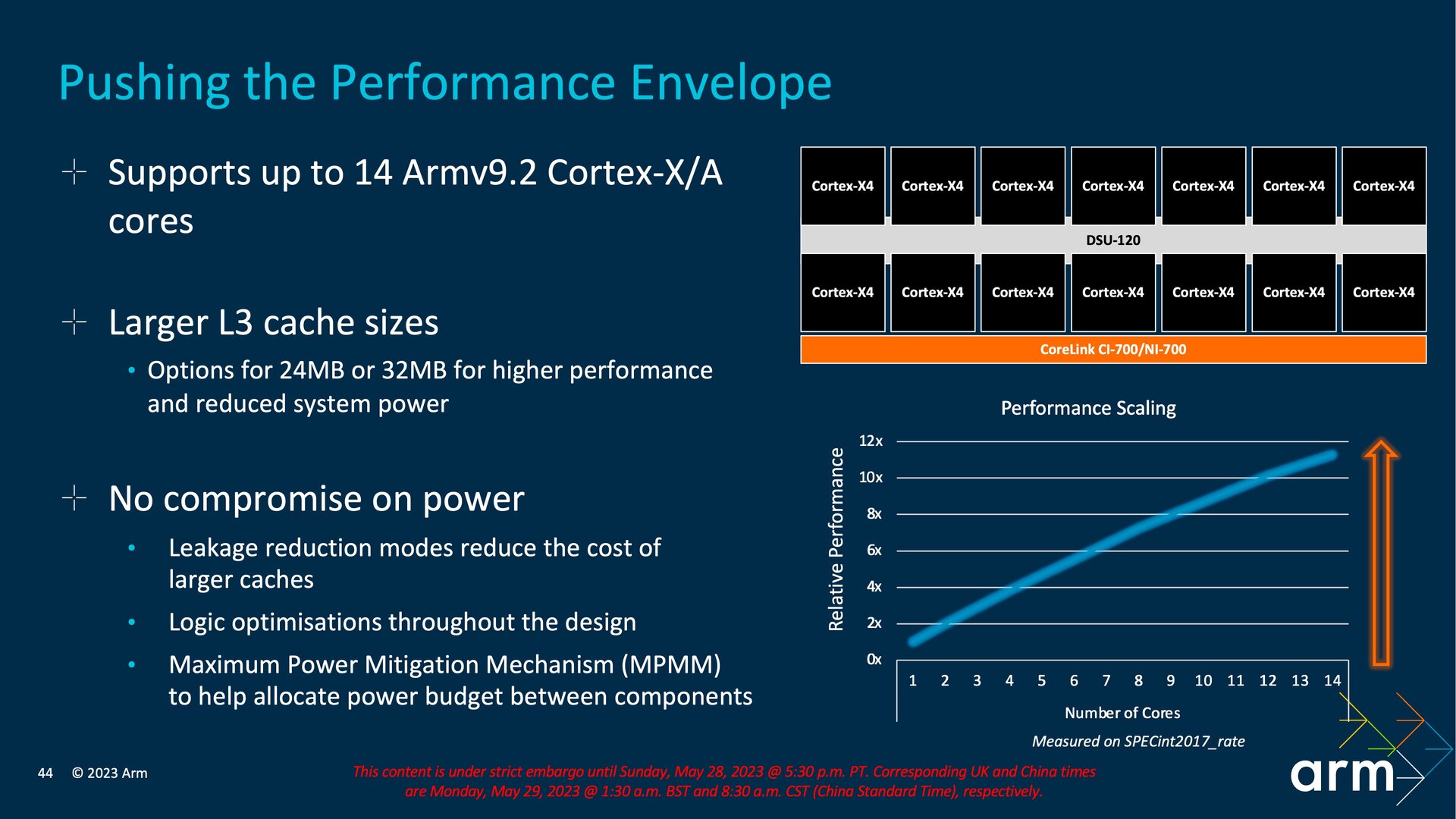
Arm nennt die DSU das Rückgrat des CPU-Clusters, weil dort alle Kerne zusammenkommen. Genau genommen ist das nicht ganz korrekt, da sich mehr als die beschriebenen 14 Kerne durch dein Einsatz multipler DSUs einsetzen lassen, sodass es auch mehrere Rückgrate geben kann. In der Praxis spielt ein solcher Aufbau bei Consumer-Produkten aber noch weniger eine Rolle als der ohnehin schon nicht genutzte Vollausbau nur einer DSU. Keine einzige dieser Lösungen gibt es bislang.
L3-Cache wächst von 24 MB auf 32 MB
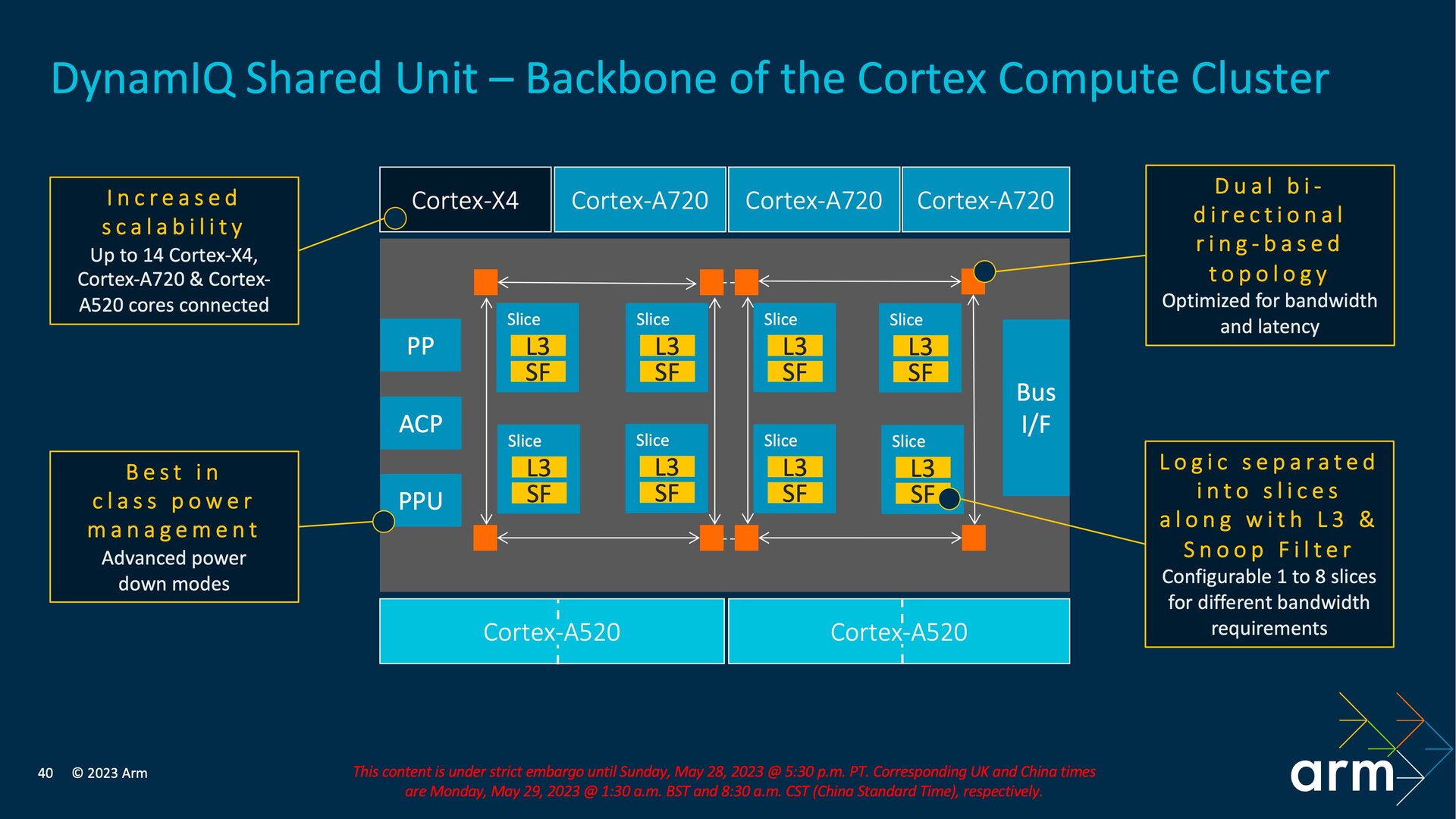
Über die DSU wird den CPU-Kernen auch der L3-Cache zur Verfügung gestellt, der mit der aktuellen Generation von – je nach Konfiguration – bis zu 24 MB auf bis zu 32 MB wächst. Innerhalb der DSU wird der L3-Cache auf bis zu acht Slices verteilt, die über ein bidirektionales Ringbussystem untereinander sowie mit den CPU-Kernen verbunden sind und die auch die Snoop Filter der Caches aufnehmen.
Low-Power-Modi für L3, Snoop Filter und Slices
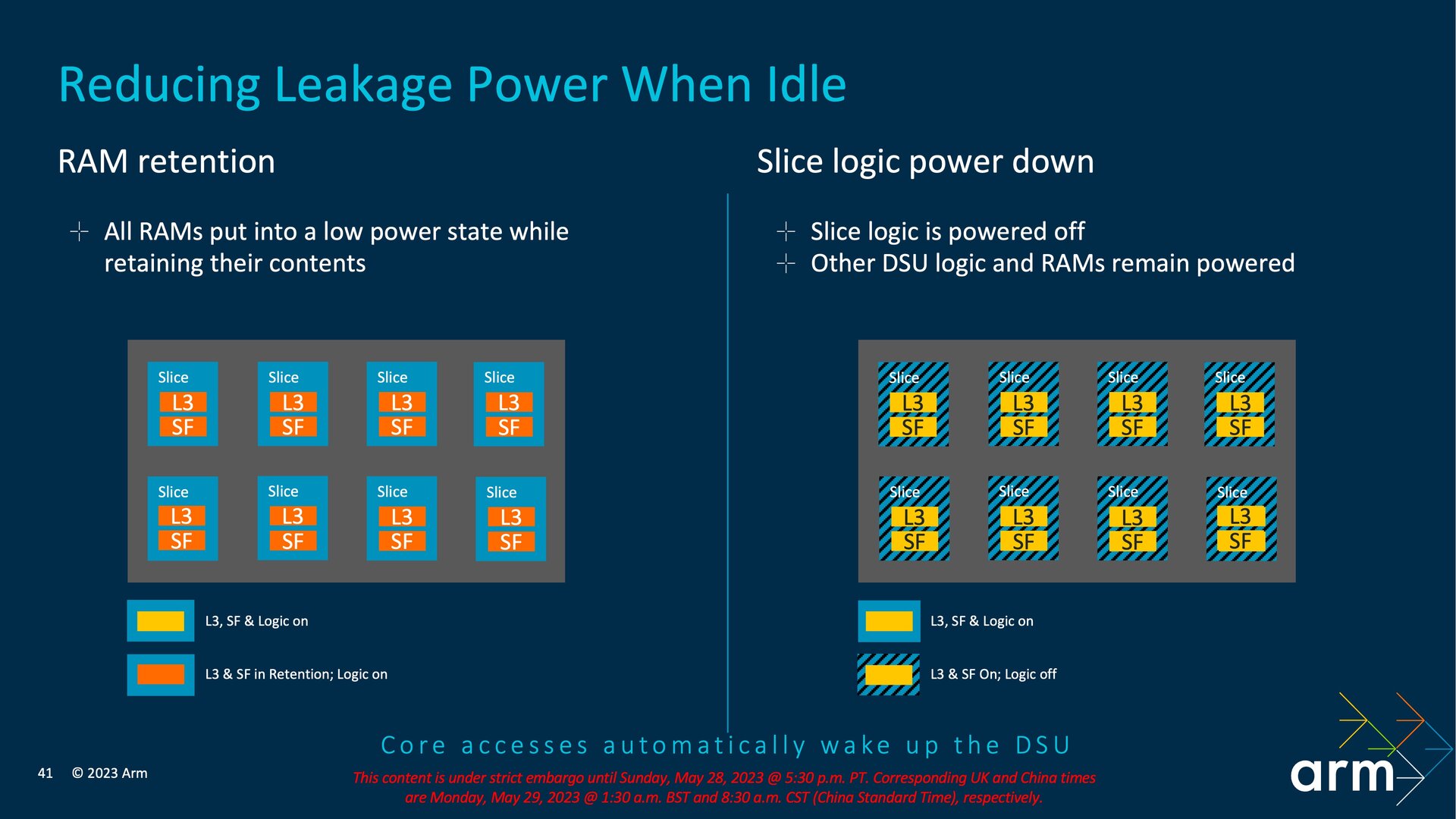
Der für die DSU-120 neue Aufbau mit den Slices ermöglicht es Arm, Leckströme zu reduzieren, während sich das System in einer Idle-Phase befindet. Im ersten Schritt können dafür während einer Idle-Phase jetzt alle RAMs und Snoop Filter in einen Low-Power-Modus mit Beibehaltung des jeweiligen Inhalts im L3-Cache versetzt werden. Darüber hinaus ist es bei der DSU-120 möglich, die Logikschaltungen des den L3 und die Snoop Filter umgebenden Slices zu deaktivieren, dabei jedoch in dem Slice den L3, Snoop Filter und weitere Bereiche der DSU aktiv zu lassen.
Die Veränderungen betreffen jedoch nicht nur die Idle-Phasen, sondern haben auch einen reduzierten Energiebedarf bei leichten Workloads zum Ziel. Dafür gibt es eine neue RAM-Abschaltung, die sich pro Slice und dabei jeweils zu 50 Prozent oder 100 Prozent durchführen lässt, sodass nur noch der halbe L3-Cache im Slice aktiv ist oder der gesamte L3-Cache pro Slice deaktiviert wird. Laut Arm sei dies vor allem für Systeme mit großem L3-Cache eine gute Lösung, wenn nicht deren gesamte Kapazität benötigt wird. Das neue Maximum von 32 MB spielt hier unweigerlich auch eine Rolle. Für leichte Workloads auf einem CPU-Kern bietet sich die vollständige Slice-Abschaltung an, bei der minimal noch ein Slice mit L3-Cache und Snoop Filter aktiv bleibt. Cache Misses soll die DSU-120 um 18 Prozent reduzieren, während die Dynamik des L3-Cache dessen Verbrauch um 7 Prozent senken soll. Insgesamt weist die DSU-120 einen um 18 Prozent reduzierten Verbrauch bei gleicher Leistung auf.
-
 Veränderungen für die DSU-120 (Bild: Arm)
Veränderungen für die DSU-120 (Bild: Arm)

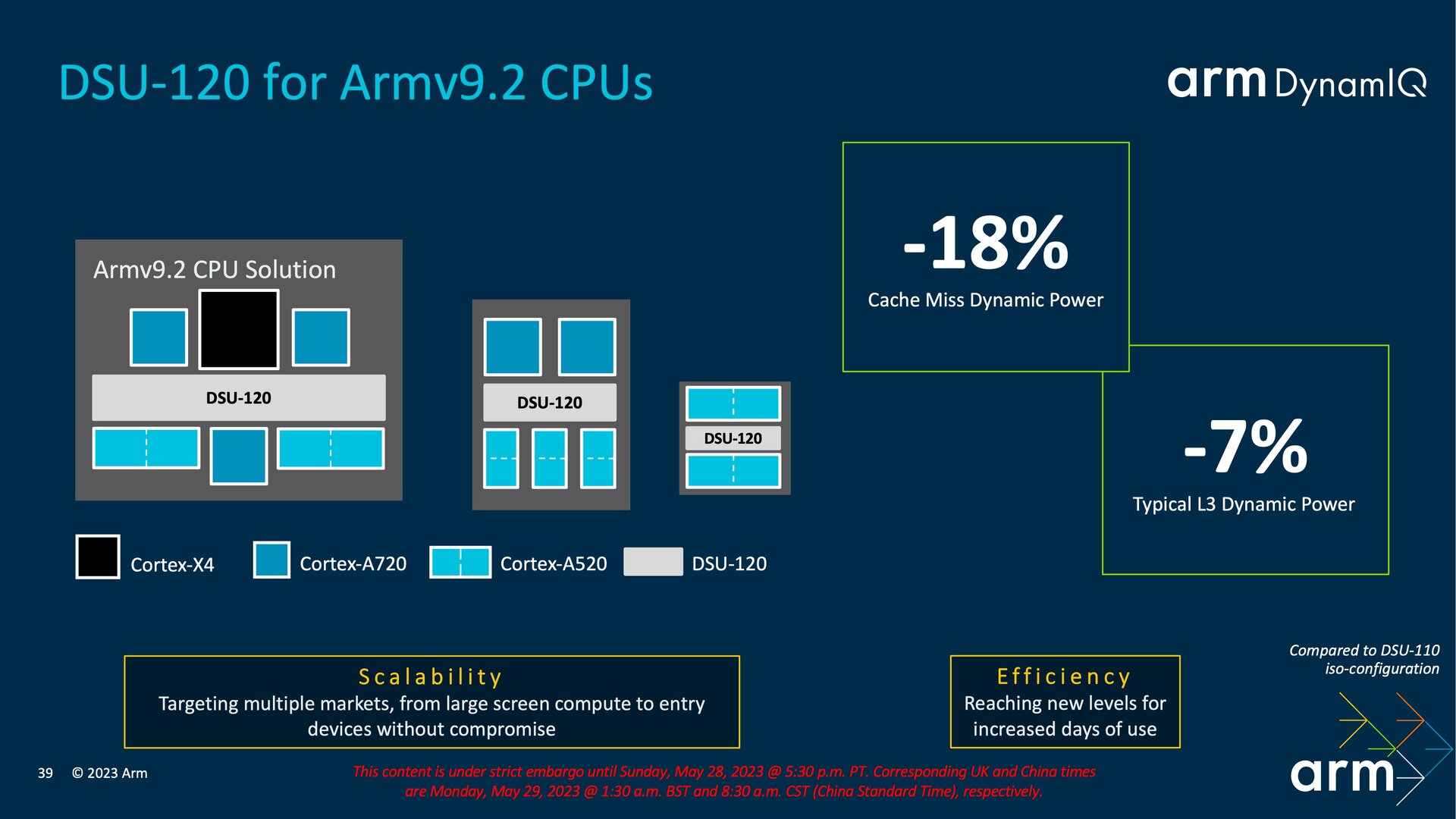
1+5+2-Aufbau wird praktikabel
Mit den Effizienzoptimierungen sind dieses Jahr neue Designs für Smartphone-Prozessoren zu erwarten, die vom bislang üblichen 1+3+4-Aufbau abweichen. Zwar kann Arm keine Ankündigungen von Partnern vorwegnehmen, mit den TCS23 sei es künftig aber durchaus praktikabel, bei der CPU auf einen 1+5+2-Aufbau zu setzen. Zum Einsatz würden dann ein Cortex-X4, fünf Cortex-A720 und zwei Cortex-A520 kommen. Die Cortex-A520 werden dabei – wie mit dem ersten Cortex-A510 eingeführt – wahlweise zu je zwei Kernen in einem Komplex betrieben, die sich den L2-Cache und mehr teilen.

Ob es tatsächlich zu solchen Konfigurationen kommen wird, bleibt abzuwarten und ist von Partnern wie Google, MediaTek, Qualcomm und Samsung abhängig. Letztes Jahr gab es etwa bei Qualcomm für den Snapdragon 8 Gen 2 einen 1+4+3-Aufbau, was jedoch vor allem damit begründet wurde, dass jeweils zwei Mid-Cores für 32- und 64-Bit-Anwendungen angeboten werden sollten, weshalb jeweils zwei Cortex-A710 (AArch32 und AArch64) und Cortex-A715 (nur AArch64) zum Einsatz kamen. Bei Google gab es für den Tensor G1 und G2 hingegen ein ungewöhnliches 2+2+4-Design, wobei der Einsatz von zwei Big-Cores zunächst fraglich erschien, Arm im Gespräch aber zu verstehen gab, dass zwei Cortex-X-Kerne durchaus Vorteile für den App-Launch mitbringen können.
Zusagen von MediaTek und Samsung
Wie die Designs auf Basis der TCS23 aussehen werden, hat noch kein Partner bekannt gegeben, allerdings gibt es zumindest von MediaTek bereits eine konkrete Zusage für die IP.
Arm's innovative 2023 IP, the Cortex-X4 and Cortex-A720, and Immortalis-G720 have provided an excellent foundation for our next-generation Dimensity flagship 5G smartphone chip, which will deliver impressive performance and efficiency through groundbreaking chip architecture and technical innovations.
[...]
Dr. JC Hsu, Corporate Senior Vice President and General Manager of Wireless Communications Business Unit, MediaTek
Samsung Electronics will die Zusammenarbeit mit Arm ebenso fortsetzen, erwähnt namentlich aber nur Armv9.2, was praktisch jedoch die neuen CPU-Kerne umfasst.
Cortex-X4 kommt auch in Intel 18A
Der Tape-out des Cortex-X4 bei TSMC in N3E wurde bereits erwähnt, andere Fertiger sind aber ebenso einsatzbereit. Nach der Ankündigung der Foundry-Partnerschaft zwischen Arm und Intel im April erklärt Intel heute, den Cortex-X4 in Intel 18A über die Foundry Services des Unternehmens fertigen zu können. Wer davon wiederum der Abnehmer sein wird, wurde zur Computex allerdings noch nicht angekündigt.
The combination of leading-edge Intel 18A technology with Arm's newest and most powerful CPU core, the Cortex-X4, will create opportunities for companies looking to design the next generation of innovative mobile SoCs. Arm is a critical partner as we work to build a comprehensive foundry ecosystem for our customers around the world.
Stuart Pann, Senior Vice President and General Manager, Intel Foundry Services (IFS)
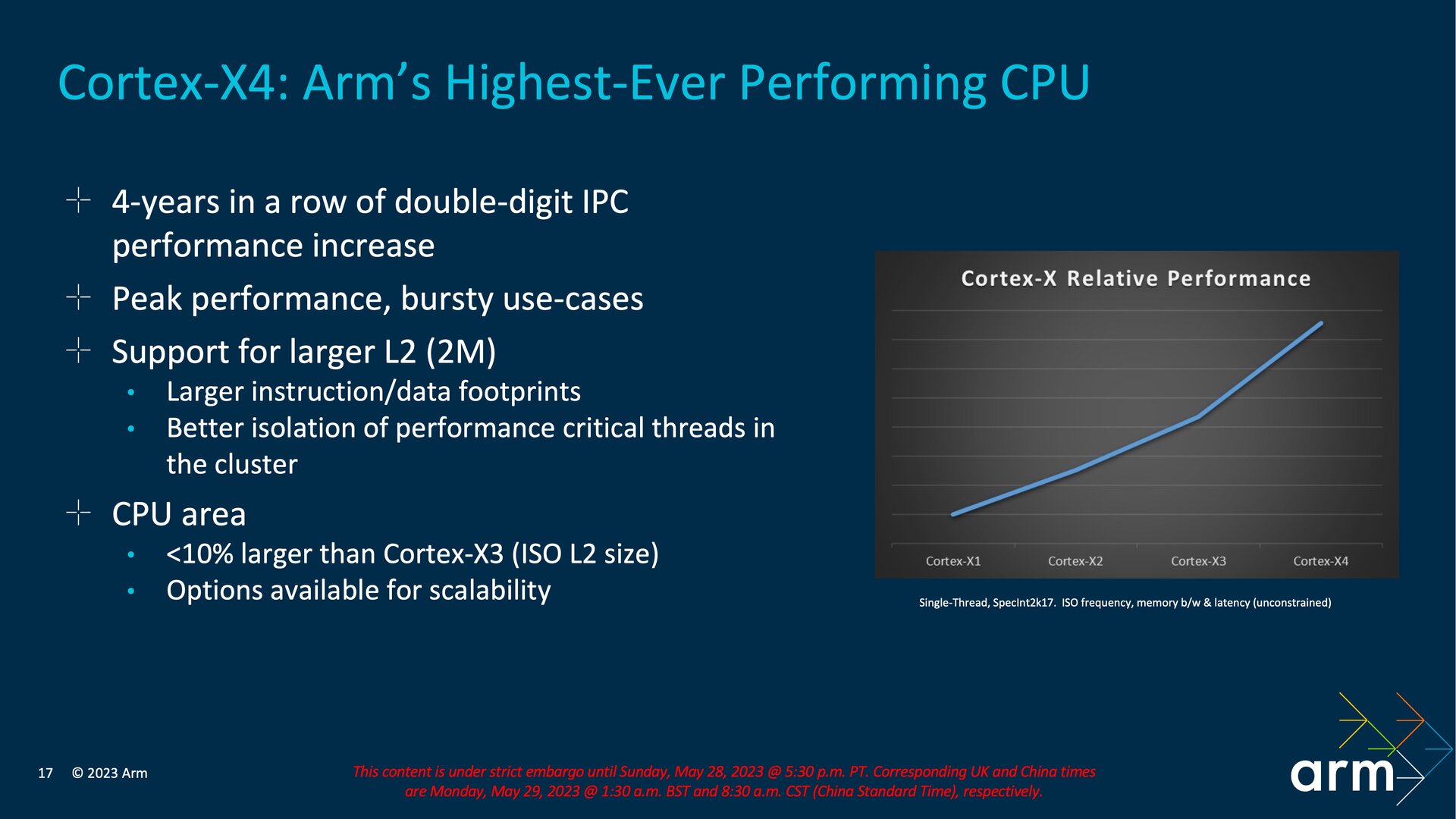
Cortex-X4: Der größte Kern wird noch größer
Innerhalb der DSU nimmt der neue Cortex-X4 die mit Abstand größte Fläche für einen einzelnen Kern ein. Frei nach dem Motto „Everything is bigger in Texas“, wo der Kern von Arm am Standort in Austin entwickelt wurde, legt dieser bei gleicher Fertigung knapp 10 Prozent in der Fläche im Vergleich zum Cortex-X3 zu. Arm bezieht sich dabei auf die Größe mit identischem L2-Cache von 1 MB, doch der Cortex-X4 bringt in diesem Punkt eine optionale Verdoppelung auf 2 MB mit, von der vor allem große Instruktionen profitieren sollen. Entscheidet sich ein SoC-Anbieter für den doppelt so großen L2-Cache, belegt der Cortex-X4 naturgemäß noch mehr Fläche auf dem Wafer.
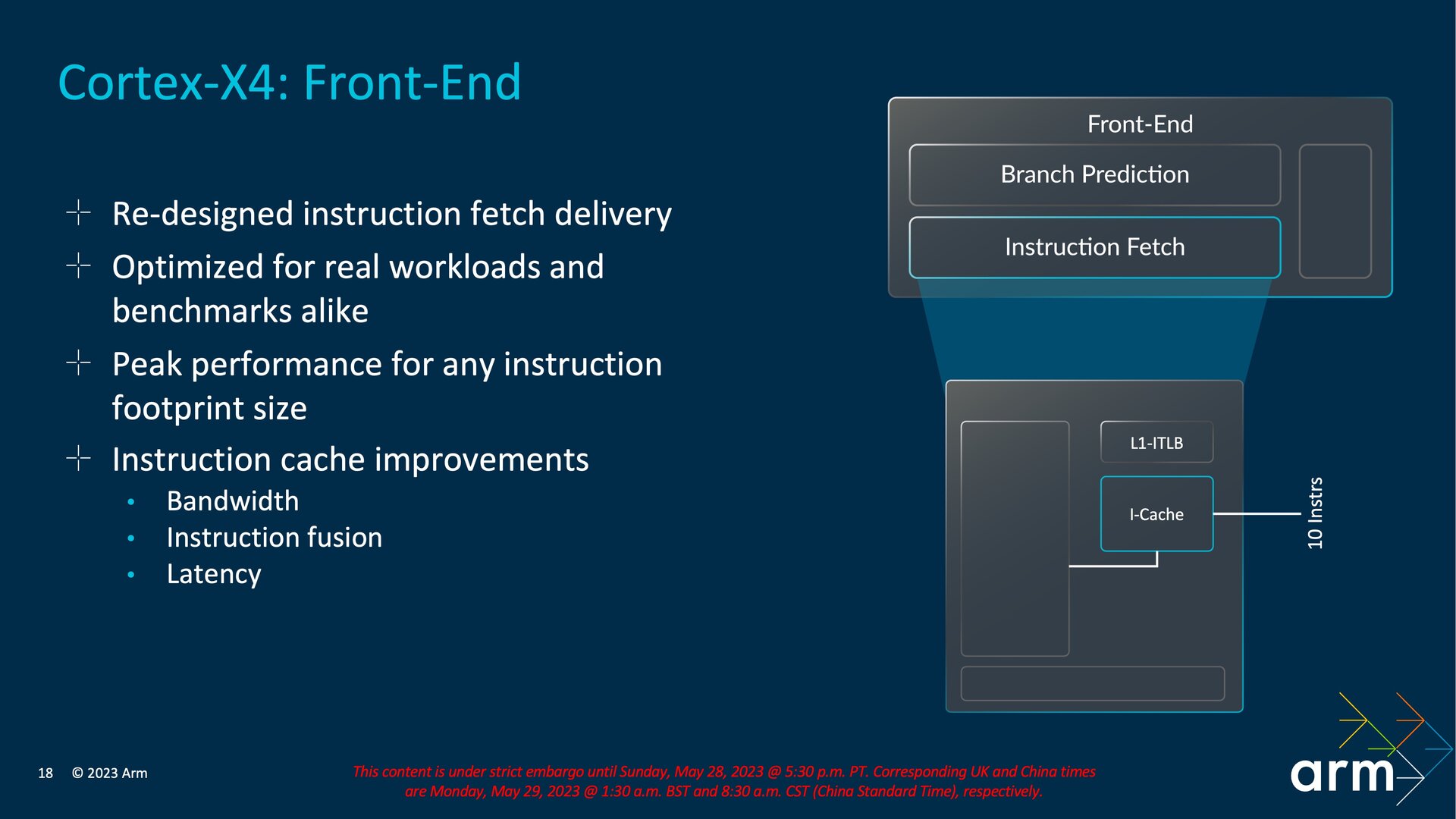
Neues 10-wide Design
Nachdem schon letztes Jahr beim Cortex-X3 das Front-End im Fokus der Entwicklung stand, gibt es dort abermals Veränderungen. Das Front-End ist bei einem Prozessor für die Sprungvorhersage, das Fetching aus dem Speicher und das Decoding zuständig. Im Front-End setzt Arm jetzt nicht mehr auf einen Instruction- und Mop-Cache, sondern nur noch auf einen I-Cache für zehn statt sechs Instruktionen, sodass es sich jetzt effektiv um ein „10-wide Design“ handelt. Schon beim Cortex-X3 hatte Arm die Anzahl der Einträge im Mop-Cache halbiert und dies mit Effizienz und Leistung begründet. Gegenüber dem Cortex-X3 wurde die Pipeline im Bereich des I-Cache-Fetchings um eine Stufe gekürzt, sodass sie jetzt bei zehn statt elf liegt. Die Strafe für falsche Sprungvorhersagen reduziert sich durch diese Neuauslegung, während sie für den ehemaligen Mop-Cache nicht mehr anfällt. Von dem neuen Aufbau sollen Bandbreite und Latenz profitieren, außerdem lassen sich Instruktionen zusammenführen.
-
 Veränderungen für den Cortex-X4 (Bild: Arm)
Veränderungen für den Cortex-X4 (Bild: Arm)
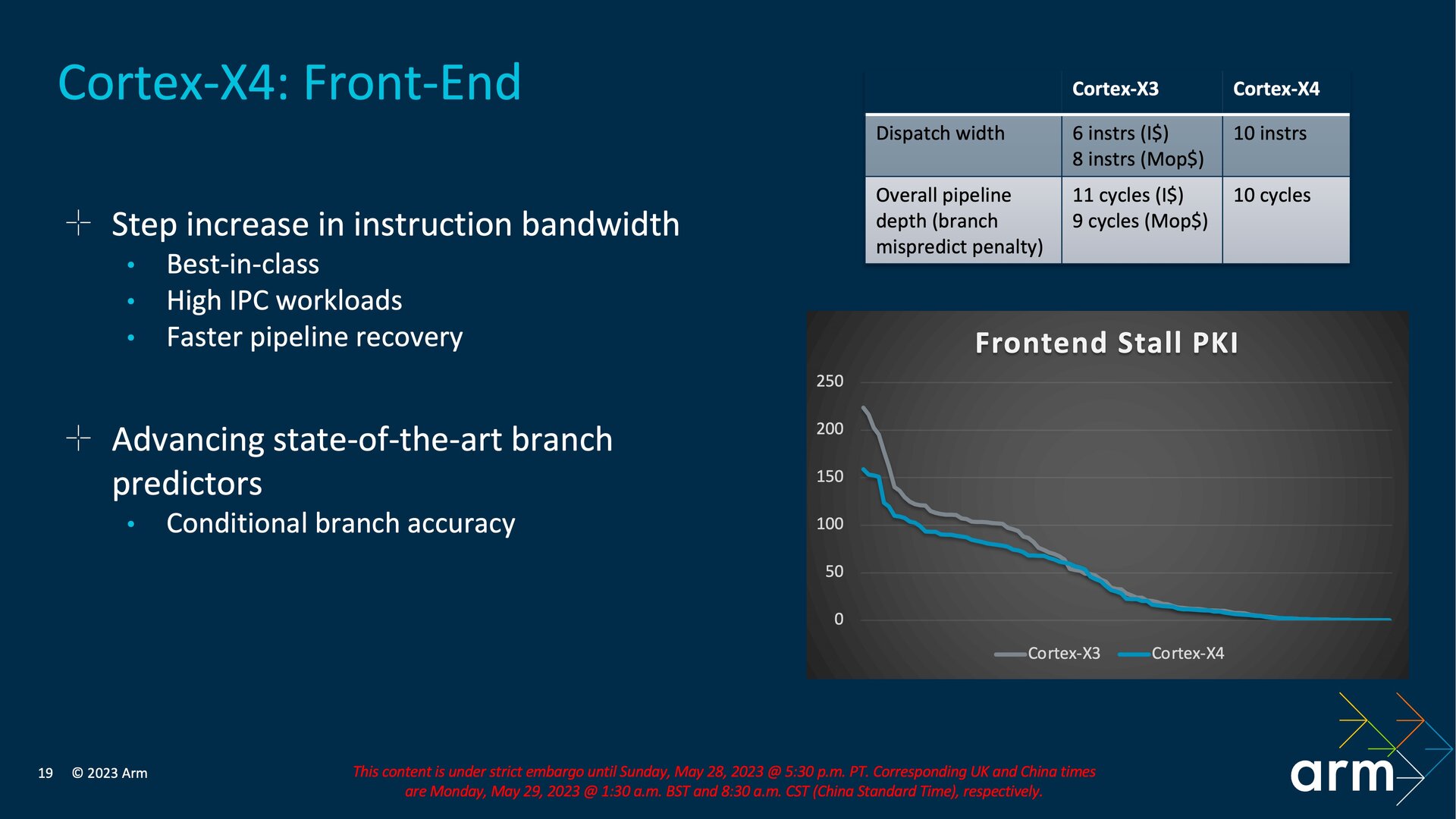
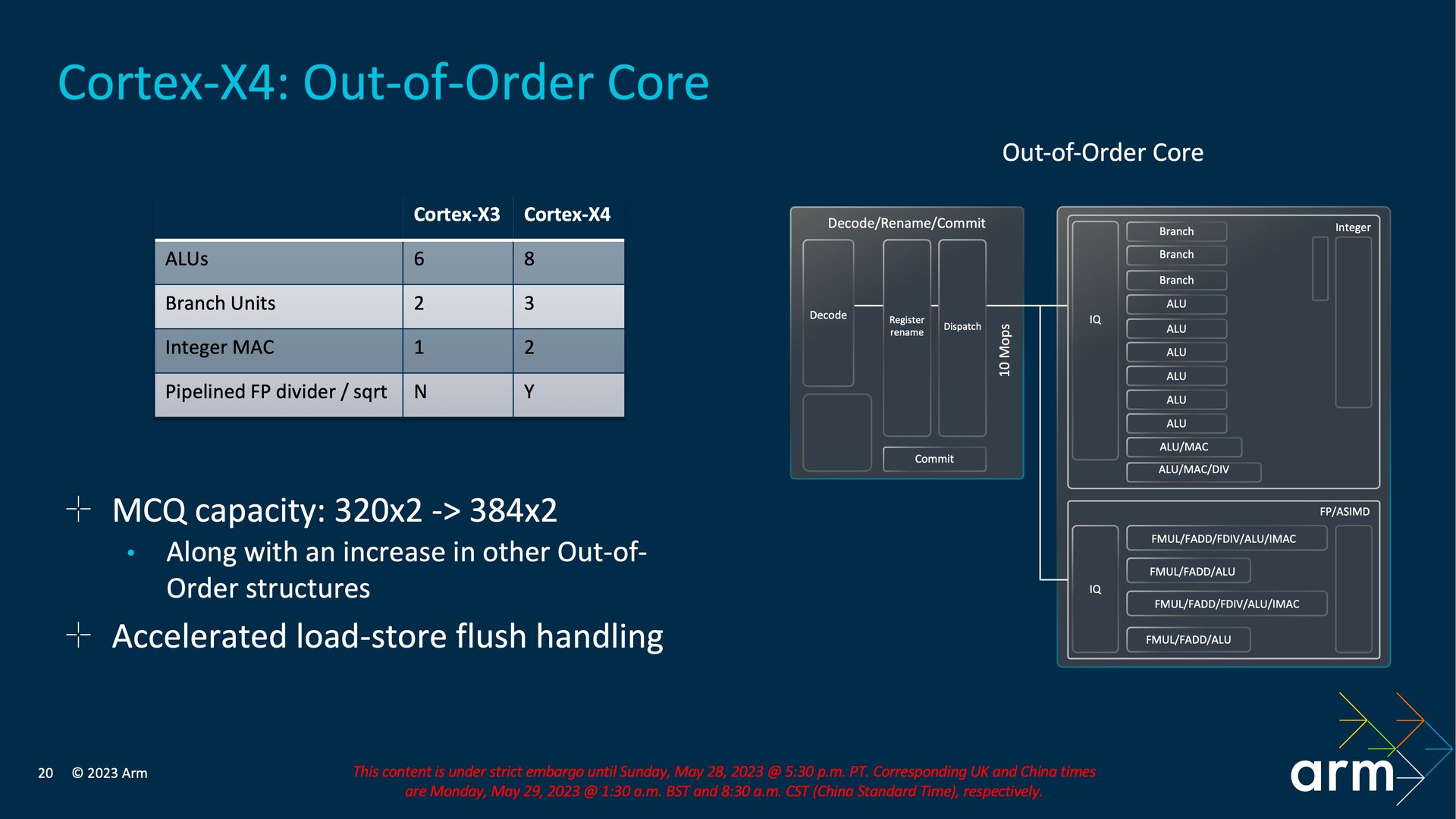
Ein Drittel mehr ALUs
Mit dem Out-of-Order-Execution-Core geht Arm abermals in die Breite und setzt auf acht anstelle von sechs ALUs (Arithmetic Logic Unit) sowie drei statt zwei Branch-Einheiten. Eine der ALUs ist dabei auch für Integer-MAC-Operationen (Integer Multiply-Accumulate) zuständig, sodass diese von Arm mit zwei statt einer gezählt wird. Die zweite sitzt in einer Einheit für ALU, MAC und DIV. Floating-Point-Operationen beim Teilen und für das Berechnen der Quadratwurzel sind nun ebenfalls Teil der Pipeline.
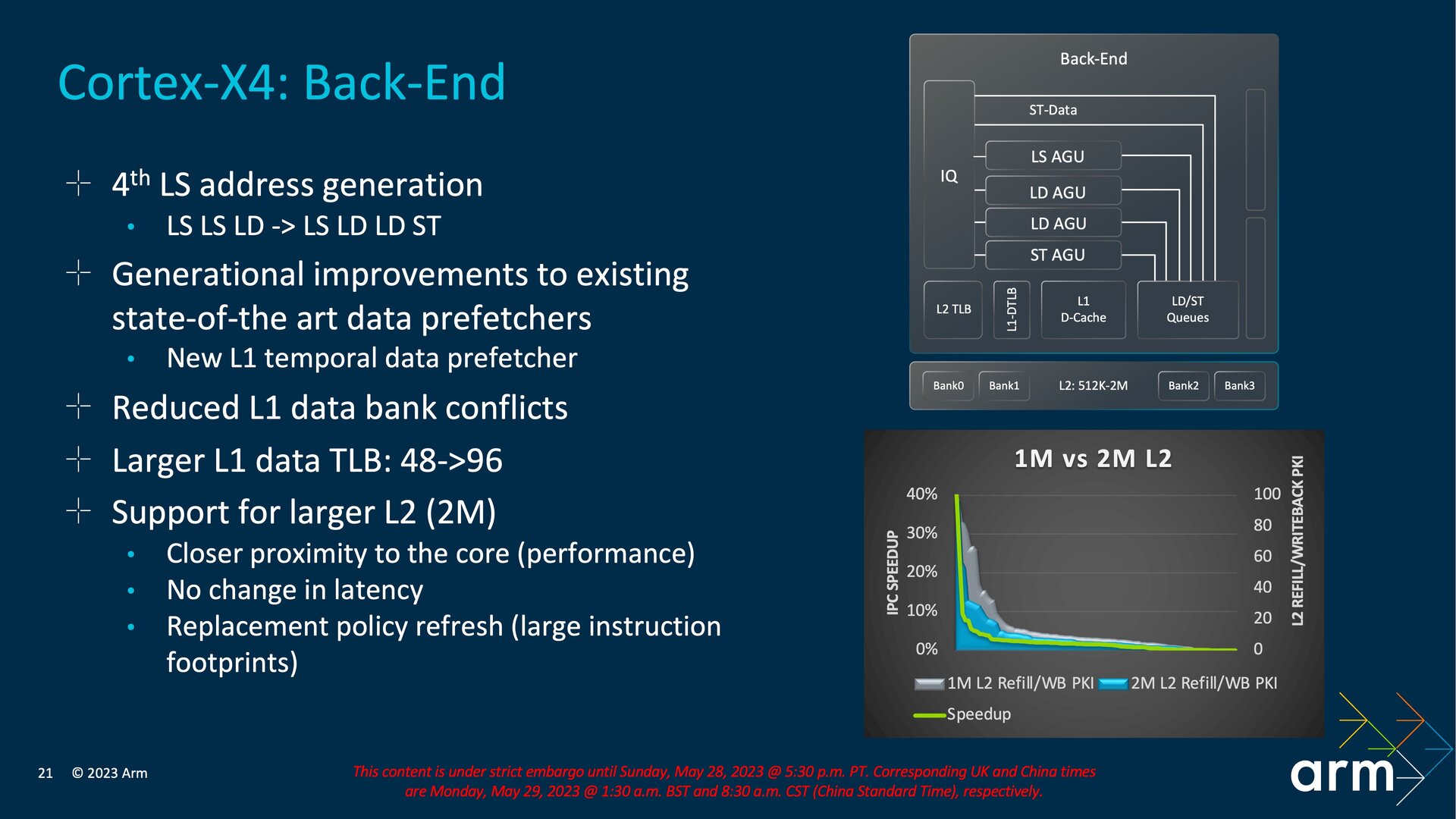
Eine vierte Address Generation Unit
Das Back-End erweitert Arm um eine vierte AGU (Address Generation Unit) für Load/Store-Befehle und verändert den bisherigen Aufbau dadurch zu mehr dedizierten Einheiten. Aus zwei AGUs für Load/Store- und einer AGU für Store-Befehle beim Back-End des Cortex-X3 werden jetzt eine AGU für Load/Store-, zwei AGUs nur für Load- und eine AGU nur für Store-Befehle. Den Translation Lookaside Buffer (TLB) des L1-Data-Cache erweitert Arm um 100 Prozent auf 96 Einträge, außerdem kann der L2-Cache wie zuvor erwähnt mit 2 MB nun doppelt so groß ausfallen. Dafür kommen weiterhin vier Bänke zum Einsatz und der vorherige Support von nur 1 MB oder 512 KB L2-Cache bleibt erhalten, sodass SoC-Anbieter lediglich nach oben hin eine neue Option erhalten haben. In Summe soll der Cortex-X4 im Vergleich zum Cortex-X3 15 Prozent mehr Leistung liefern oder bei gleicher Leistung den Verbrauch um 40 Prozent reduzieren.
-
 Veränderungen für den Cortex-X4 (Bild: Arm)
Veränderungen für den Cortex-X4 (Bild: Arm)
Cortex-A720: Effizienz und dauerhafte Leistung
Für den Mid-Core Cortex-A720 gibt es dieses Jahr keine signifikanten Anpassungen, jedoch eine Reihe von Optimierungen, um den Kern effizienter zu machen. Arm hat sich für den Cortex-A720 die beste dauerhaft verfügbare Leistung innerhalb der thermischen Limitierungen eines SoCs zum Ziel gesetzt. Die Leistung soll nur bei gleicher oder besserer Energieeffizienz durch kleinere Optimierungen der Mikroarchitektur sowie durch Vorteile aus den moderneren Nodes in der Fertigung gesteigert werden. Für Chip-Anbieter mit Fokus auf die Die-Size, die günstigere SoCs und potenziell ohne Cortex-X-Kern planen, ist vom Cortex-A720 zusätzlich eine Entry-Tier-Konfiguration mit der Fläche des alten Cortex-A78 bei dennoch rund 10 Prozent mehr Leistung vorgesehen.

Weniger DRAM-Zugriffe und Latenz
An der Breite oder Tiefe des Kerns gibt es somit keine Veränderungen, stattdessen seien vor allem die Zugriffe auf den DRAM signifikant reduziert worden, was Energie spart. Zudem wurde Latenz bei einer falschen Sprungvorhersage von zwölf auf elf Taktzyklen verringert. Außerdem hat Arm Sprungvorhersagen auf Basis von zwei zuvor genommenen Branches optimiert, was abermals der Effizienz zugutekommen soll.
Im Out-of-Order-Core des Cortex-A720 sind wie beim Cortex-X4 jetzt Floating-Point-Operationen beim Teilen und für das Berechnen der Quadratwurzel Teil der Pipeline, was für diese Aufgaben signifikant die Leistung steigern soll, ohne dass mehr Fläche benötigt wird. Schnellere Transfers von Floating Point, NEON und SVE2 zu Integer soll der Kern ebenfalls bieten. Für das Speichersystem des Kerns gibt es eine reduzierte Latenz für Zugriffe auf den L2-Cache, die jetzt bei nur noch neun statt zehn Taktzyklen liegt. Speicherintensive Workloads sollen davon profitieren, außerdem gebe es Vorteile für schwer vorhersagbare Branches mit einer Datenabhängigkeit.
-
 Veränderungen für den Cortex-A720 (Bild: Arm)
Veränderungen für den Cortex-A720 (Bild: Arm)


Cortex-A520: Verbrauch hat oberste Priorität
Für den Cortex-A520 als kleinsten Kern haben die beste Energieeffizienz und der geringste Verbrauch in Relation zur benötigten Fläche oberste Priorität. Der Core ist für Aufgaben mit geringer Intensität sowie für Workloads im Hintergrund ausgelegt, um die Akkulaufzeiten eines Smartphones positiv zu beeinflussen. Für den Cortex-A520 hatte Arm dennoch beides zum Ziel: mehr Leistung und eine höhere Energieeffizienz.
-
 Veränderungen für den Cortex-A520 (Bild: Arm)
Veränderungen für den Cortex-A520 (Bild: Arm)

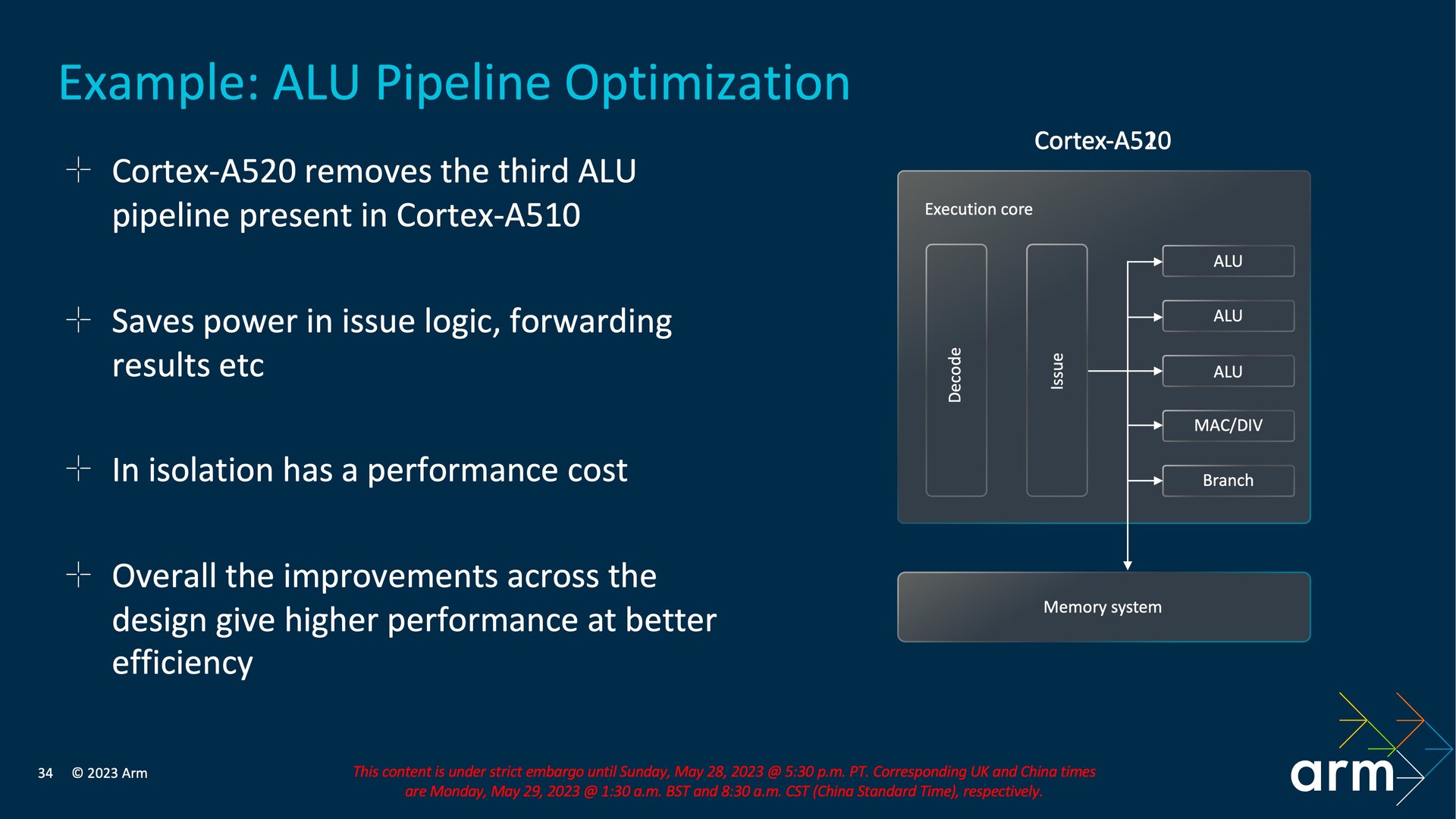
Eine ALU fliegt raus
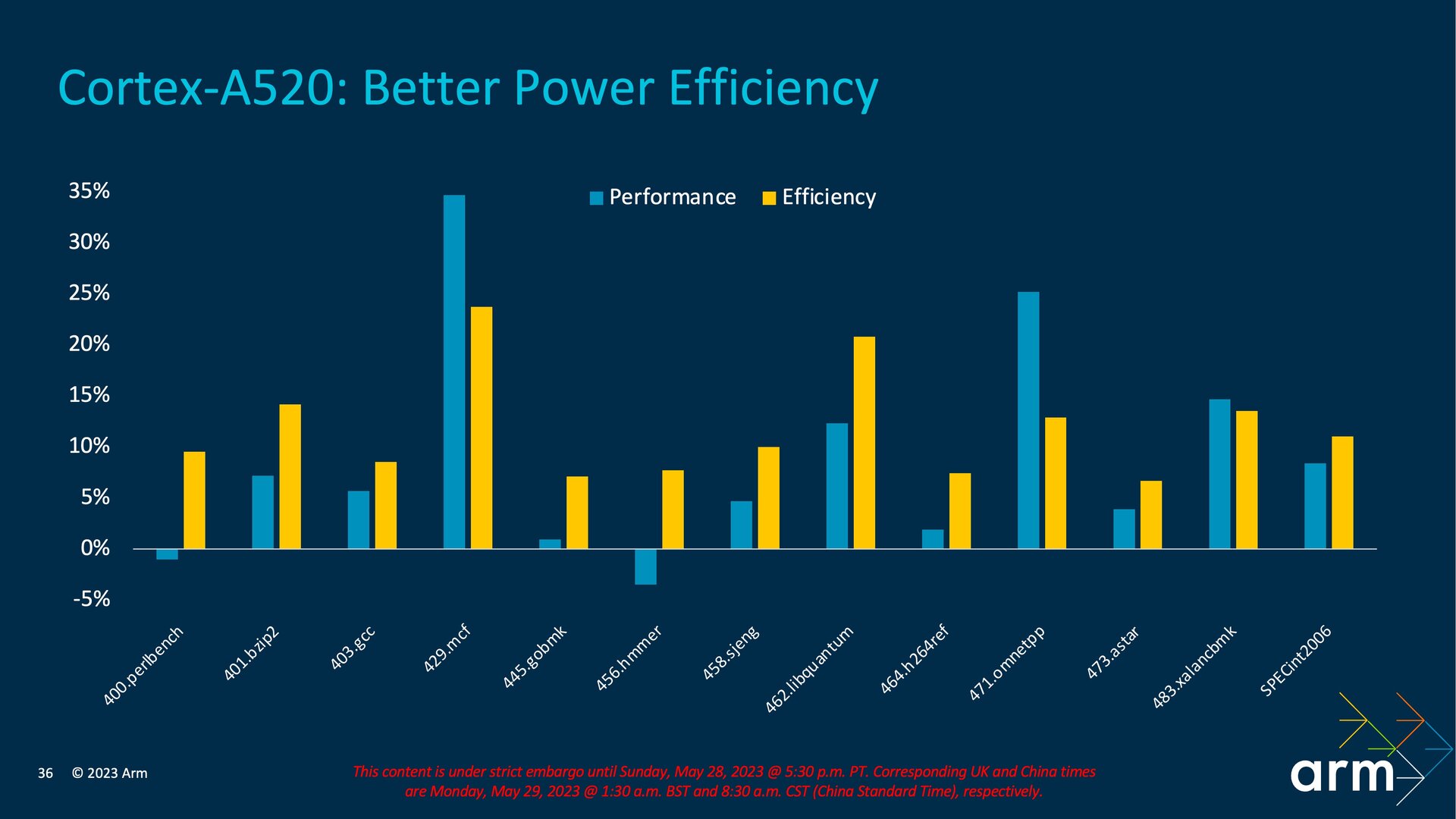
Arm geht zwar nicht auf Details ein, nennt aber Optimierungen beim Data-Prefetching und der Sprungvorhersage, wodurch die Leistung bei nur sehr geringen Einbußen des Verbrauchs gesteigert werden konnte. Aus dem Execution-Core des Cortex-A520 hat Arm eine der ehemals drei ALUs entfernt, sodass es davon jetzt noch zwei gibt. Isoliert betrachtet habe dies zwar negativen Einfluss auf die Leistung, mit den anderen Optimierungen könne dies aber bei gleichzeitig höherer Effizienz aufgefangen werden.
AArch32 ist Geschichte
Zu guter Letzt ist der Cortex-A520 auch ein effizienterer Kern, da er alle 32-Bit-Altlasten ablegt und jetzt ein reiner 64-Bit-Kern nur noch für AArch64 ist. Unterm Strich verbraucht der neue Little-Kern laut Arm 22 Prozent weniger bei gleicher Leistung oder bietet eine 8 Prozent höhere Leistung bei annähernd identischem Verbrauch.
-
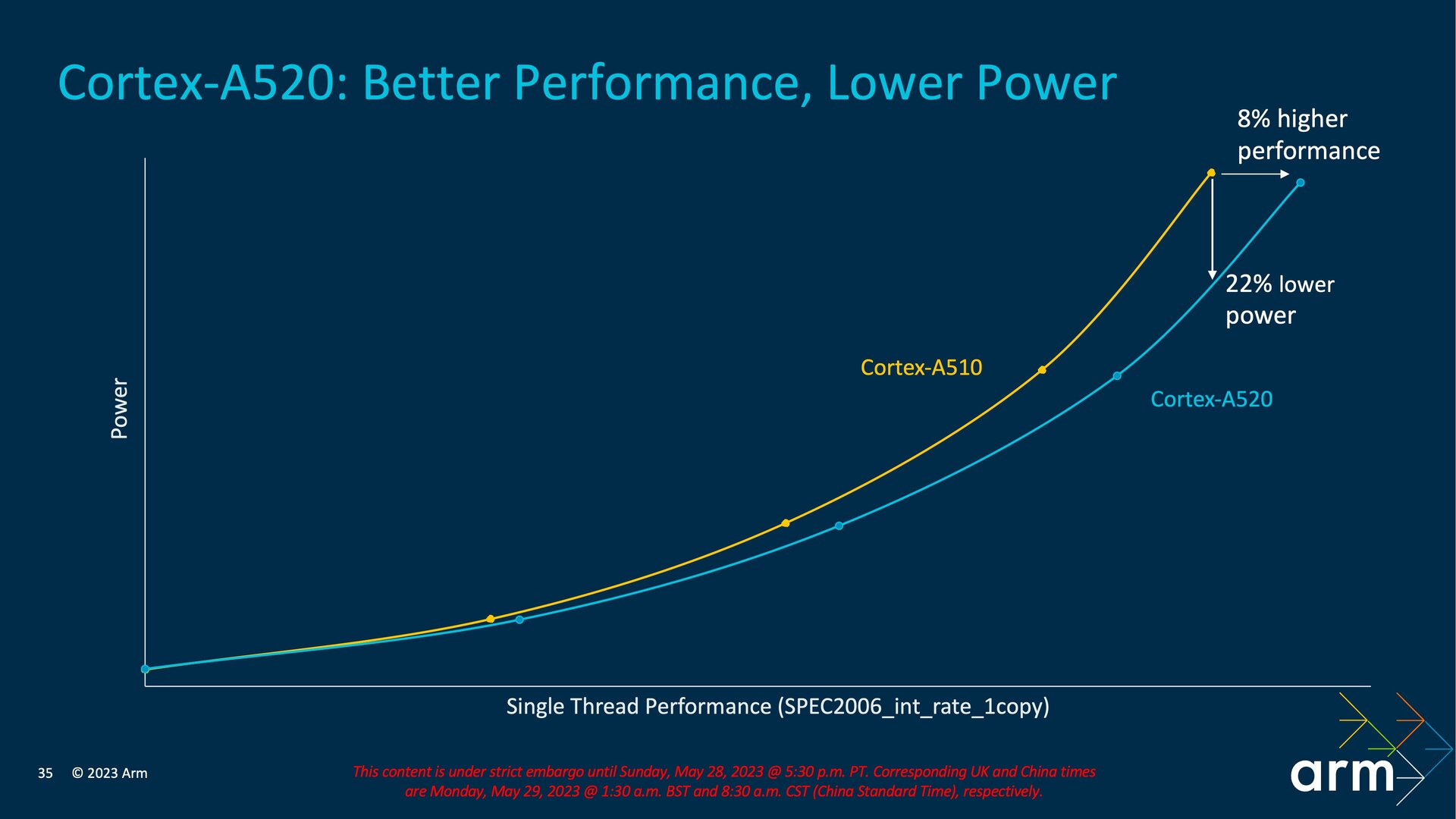 Veränderungen für den Cortex-A520 (Bild: Arm)
Veränderungen für den Cortex-A520 (Bild: Arm)
ComputerBase hat Informationen zu diesem Artikel von Arm im Rahmen einer Veranstaltung des Herstellers in Cambridge unter NDA erhalten. Die Kosten für Anreise, Abreise und Hotel wurden von dem Unternehmen getragen. Eine Einflussnahme des Herstellers oder eine Verpflichtung zur Berichterstattung bestand nicht. Die einzige Vorgabe war der frühestmögliche Veröffentlichungszeitpunkt.
Dieser Artikel war interessant, hilfreich oder beides? Die Redaktion freut sich über jede Unterstützung durch ComputerBase Pro und deaktivierte Werbeblocker. Mehr zum Thema Anzeigen auf ComputerBase.