Hallo zusammen,
Ich hab ein Problem beim bearbeiten einer Textdatei.
Die Datei (bei mir natürlich ohne Zeilenumbrüche vorliegend) enthält ip Felder, und sollen später in einer art Filter verwendet werden, wofür ich die datei etwas aufbereiten muss. Erstes etappenziel ist das entfernen von Kommentaren und Leerzeilen aller Art, sowie htaccess Befehle wie "deny from".
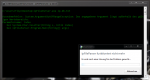
Zeile 3 löst eine ArgumentOutOfRangeException aus:
Zu der Ausnahme und StreamReadern hab ich bisher aber nix passendes gefunden.
Eigentlich soll das Programm alle Kommentare (bisauf mit $ gekennzeichnete) und frei Zeilen oder solche, die mit einem Buchstaben beginnen herausfiltern. Das richtige parsen und entfalten der IP-Felder in eine Liste muss erst noch im Kopf geplant werden.
Programmcode:
IDE ist VS 2013
Ich hab ein Problem beim bearbeiten einer Textdatei.
Die Datei (bei mir natürlich ohne Zeilenumbrüche vorliegend) enthält ip Felder, und sollen später in einer art Filter verwendet werden, wofür ich die datei etwas aufbereiten muss. Erstes etappenziel ist das entfernen von Kommentaren und Leerzeilen aller Art, sowie htaccess Befehle wie "deny from".
Zeile 3 löst eine ArgumentOutOfRangeException aus:
Code:
if (sReader.ReadLine().StartsWith("# ") ||
sReader.ReadLine().StartsWith(" ") ||
char.IsLetter(sReader.ReadLine(), 0))
{
continue;
}Zu der Ausnahme und StreamReadern hab ich bisher aber nix passendes gefunden.
Eigentlich soll das Programm alle Kommentare (bisauf mit $ gekennzeichnete) und frei Zeilen oder solche, die mit einem Buchstaben beginnen herausfiltern. Das richtige parsen und entfalten der IP-Felder in eine Liste muss erst noch im Kopf geplant werden.
Programmcode:
Code:
#region Using directives
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.IO;
using System.Threading.Tasks;
using System.Windows.Forms;
using System.Diagnostics;
#endregion
namespace ipFileParser
{
class Program
{
static void Main(string[] args)
{
if (args.Length == 0)
{
MessageBox.Show("Programm über Befehlszeile mit Eingabedatei als Parameter starten!\n Beispiel: ipFileParser ips.txt", "Fehler", MessageBoxButtons.OK, MessageBoxIcon.Error, MessageBoxDefaultButton.Button1);
}
else
{
if ( File.Exists(args[0]) )
{
List<String> input = new List<string>();
List<string> output = new List<string>();
using (StreamReader sReader = new StreamReader(args[0]))
{
#if DEBUG
int totLines = 0;
int numLines = 0;
string tmp;
#endif
string buf;
while ( sReader.Peek() >= 0) // still reading
{
#if DEBUG
totLines++;
#endif
if (sReader.ReadLine().StartsWith("# ") ||
sReader.ReadLine().StartsWith(" ") ||
char.IsLetter(sReader.ReadLine(), 0))
{
continue;
}
#if DEBUG
numLines++;
#endif
buf = sReader.ReadLine();
if (buf.StartsWith("deny from "))
{
buf.Substring(0, 10); // remove "deny from "
}
output.Add(buf);
}
File.WriteAllLines(Application.StartupPath + "\\output.txt", output.ToArray());
#if DEBUG
tmp = string.Format("{0} lines read, {1} lines skipped, {2} lines pushed to output", totLines, totLines - numLines, numLines);
Debug.WriteLine(tmp);
#endif
}
}
}
}
}
}IDE ist VS 2013