V
VikingGe
Gast
Guten Morgen,
nachdem ich mal beim Programmieren ein paar threadsichere Datenstrukturen gebenchmarkt habe und dabei teils überraschende Ergebnisse herauskamen, würde mich doch mal interessieren, wie genau sich verschiedene CPUs beim Datentransfer zwischen mehreren Kernen verhalten. Dazu habe ich mal einen kleinen Benchmark geschrieben:
Compilieren mit:
oder mit irgendeinem anderen Compiler, der sowohl C++11 als auch ein paar Optimierungen beherrscht.
Jetzt suche ich Leute, die das Ding mal testweise ausführen. Das Programm macht nichts weiter, als einen Zähler 100 Millionen mal herunterzuzählen, wobei ein Thread die geraden Zahlen übernimmt und ein anderer die ungeraden, sodass jeder Zählschritt abwechselnd im jeweils anderen Thread stattfindet. Das ganze dauert einige Sekunden.
Ein paar Anmerkungen für die Leute, die sich auskennen:
- Ein Delay von einigen Takten zwischen den Loads, um die CPU zu entlasten, bringt hier scheinbar überhaupt nichts.
- Ich habe ganz bewusst auf atomare Operationen verzichtet. Die sind hier einerseits nicht nötig, andererseits auch eine völlig andere Baustelle - ich will hier lediglich ermitteln, wie lang es dauert, bis ein Kern einen Store eines anderen Kerns "sieht", ohne, dass sonst viel passiert.
- Ich weiß selbst, dass der Test nicht genug Aussagekraft hat, um damit die ganze Welt zu erklären.
Ergebnisse, die ich bereits habe:
Um bei AMD-CPUs zu verhindern, dass die beiden Threads des Programms auf demselben Modul laufen:
Um zu erzwingen, dass nur ein Modul genutzt wird:
Wie bei Intel+SMT die Aufteilung ist, weiß ich nicht, da muss man aber auch darauf achten.
Mich würden vor allem Ergebnisse von aktuellen Intel-CPUs und von FX-Chips mit ggf. NB-OC interessieren, prinzipiell ist aber alles gern gesehen. Schreibt aber auch bitte dabei, mit welchem Takt eure CPU läuft, und ggf. auch RAM-Takt und -Timings. Wäre nett, wenn sich jemand beteiligen würde")
nachdem ich mal beim Programmieren ein paar threadsichere Datenstrukturen gebenchmarkt habe und dabei teils überraschende Ergebnisse herauskamen, würde mich doch mal interessieren, wie genau sich verschiedene CPUs beim Datentransfer zwischen mehreren Kernen verhalten. Dazu habe ich mal einen kleinen Benchmark geschrieben:
Code:
#include <chrono>
#include <iostream>
#include <thread>
#include <cstddef>
#include <cstdint>
void count_down(volatile int64_t& counter, int64_t divisor) {
int64_t current = counter;
while (current > 0) {
while ((current & 1l) != divisor)
current = counter;
counter = --current;
}
}
template<typename Fn>
std::chrono::milliseconds timed_run(const Fn& function) {
auto start = std::chrono::high_resolution_clock::now();
function();
return std::chrono::duration_cast<std::chrono::milliseconds>(
std::chrono::high_resolution_clock::now() - start);
}
int main(int argc, char** argv) {
constexpr int64_t loop_count = 100000000l;
constexpr int64_t loop_factor = 1000000000l / loop_count;
auto ms = timed_run([] {
volatile int64_t counter(loop_count);
std::thread t1([&counter] { count_down(counter, 0l); });
std::thread t2([&counter] { count_down(counter, 1l); });
t1.join();
t2.join();
});
const double latency = static_cast<double>(loop_factor * ms.count()) / 1000.0;
std::cout << latency << " ns" << std::endl;
}Compilieren mit:
Code:
g++ -std=c++11 -O3 -pthread -o bench bench.cppJetzt suche ich Leute, die das Ding mal testweise ausführen. Das Programm macht nichts weiter, als einen Zähler 100 Millionen mal herunterzuzählen, wobei ein Thread die geraden Zahlen übernimmt und ein anderer die ungeraden, sodass jeder Zählschritt abwechselnd im jeweils anderen Thread stattfindet. Das ganze dauert einige Sekunden.
Ein paar Anmerkungen für die Leute, die sich auskennen:
- Ein Delay von einigen Takten zwischen den Loads, um die CPU zu entlasten, bringt hier scheinbar überhaupt nichts.
- Ich habe ganz bewusst auf atomare Operationen verzichtet. Die sind hier einerseits nicht nötig, andererseits auch eine völlig andere Baustelle - ich will hier lediglich ermitteln, wie lang es dauert, bis ein Kern einen Store eines anderen Kerns "sieht", ohne, dass sonst viel passiert.
- Ich weiß selbst, dass der Test nicht genug Aussagekraft hat, um damit die ganze Welt zu erklären.
Ergebnisse, die ich bereits habe:
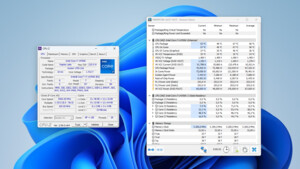
| i7-4770K @3.5, 1 Kern | 26.05 ns | Nai |
| A10-7350B @3.3, 1 Modul | 29.22 ns | |
| i5-2500 @3.3 | 42.42 ns | |
| i5-4670 @3.4 | 53.07 ns | strex |
| i7-4720HQ | 53.80 ns | R4Z3R |
| i7-4770K @3.5 | 54.13 ns | Nai |
| i5-6600K @3.5 | 58.24 ns | Mr.Seymour Buds |
| Athlon 5350 @2.1 | 61.65 ns | |
| i5-2500 @1.7 | 62.56 ns | titanskin |
| Phenom II X6 @4.1/3.0 | 77.94 ns | |
| A10-7350B @2.8 | 217.94 ns | |
| 2x Xeon E5345 @2.33, 1 CPU | 1905.95 ns | |
| 2x Xeon E5345 @2.33, 2 CPUs | 1981.54 ns |
Um bei AMD-CPUs zu verhindern, dass die beiden Threads des Programms auf demselben Modul laufen:
Code:
taskset -c 0,2 ./bench
Code:
taskset -c 0,1 ./benchWie bei Intel+SMT die Aufteilung ist, weiß ich nicht, da muss man aber auch darauf achten.
Mich würden vor allem Ergebnisse von aktuellen Intel-CPUs und von FX-Chips mit ggf. NB-OC interessieren, prinzipiell ist aber alles gern gesehen. Schreibt aber auch bitte dabei, mit welchem Takt eure CPU läuft, und ggf. auch RAM-Takt und -Timings. Wäre nett, wenn sich jemand beteiligen würde
Zuletzt bearbeitet: