Arm-Datacenter-CPU-Roadmap: Schnellere Neoverse-Kerne, aber keine neue „dicke CPU“
Arms Refresh im Datacenter bringt mehr Performance. Weil bisherige Problemstellen beseitigt wurden, legt Neoverse V3 bei der Leistung um 20 Prozent zu – bei AI mitunter noch mehr. Echte Neuheiten halten sich wiederum überraschend in Grenzen. Auch traut sich Arm nicht höher hinaus, das wird Partnern überlassen.
Arm priorisiert die GPU
Vor Jahren schlug Arm der x86-Gemeinde ein Schnippchen: Bei Arm gab es plötzlich viel mehr Kerne für die gleiche Zielgruppe, die x86-Hersteller waren davon weit entfernt.
Diesen Vorteil verspielt Arm mit eigenen Chips vorerst. AMD hat mit den Bergamo-CPUs nicht nur bereits eigene Lösungen mit 128 Kernen im Markt, demnächst kommen x86-CPUs mit noch viel mehr. An der Spitze steht in Kürze erst einmal Intel Sierra Forest mit bis zu 288 Kernen. Mit diesen Plattformen wollen auch AMD und Intel viele Kerne auf möglichst kleinem Raum bieten und Arm etwas entgegensetzen.
Arm sucht im Marketing derweil die Nähe zu GPUs, AI-Beschleuniger sind aktuell natürlich in aller Munde. Das Schaubild für den neuen Arm Neoverse V3 mit angeflanschter GPU ähnelt deshalb einem denkbaren Nachfolger respektive Mitbewerber von Nvidia Grace Hopper GH200. Bei diesem SoC wurde ein solches Design nämlich das erste Mal umgesetzt, aktuell feiert es große Erfolge in hocheffizienten Supercomputern – unter anderem im deutschen Jupiter.
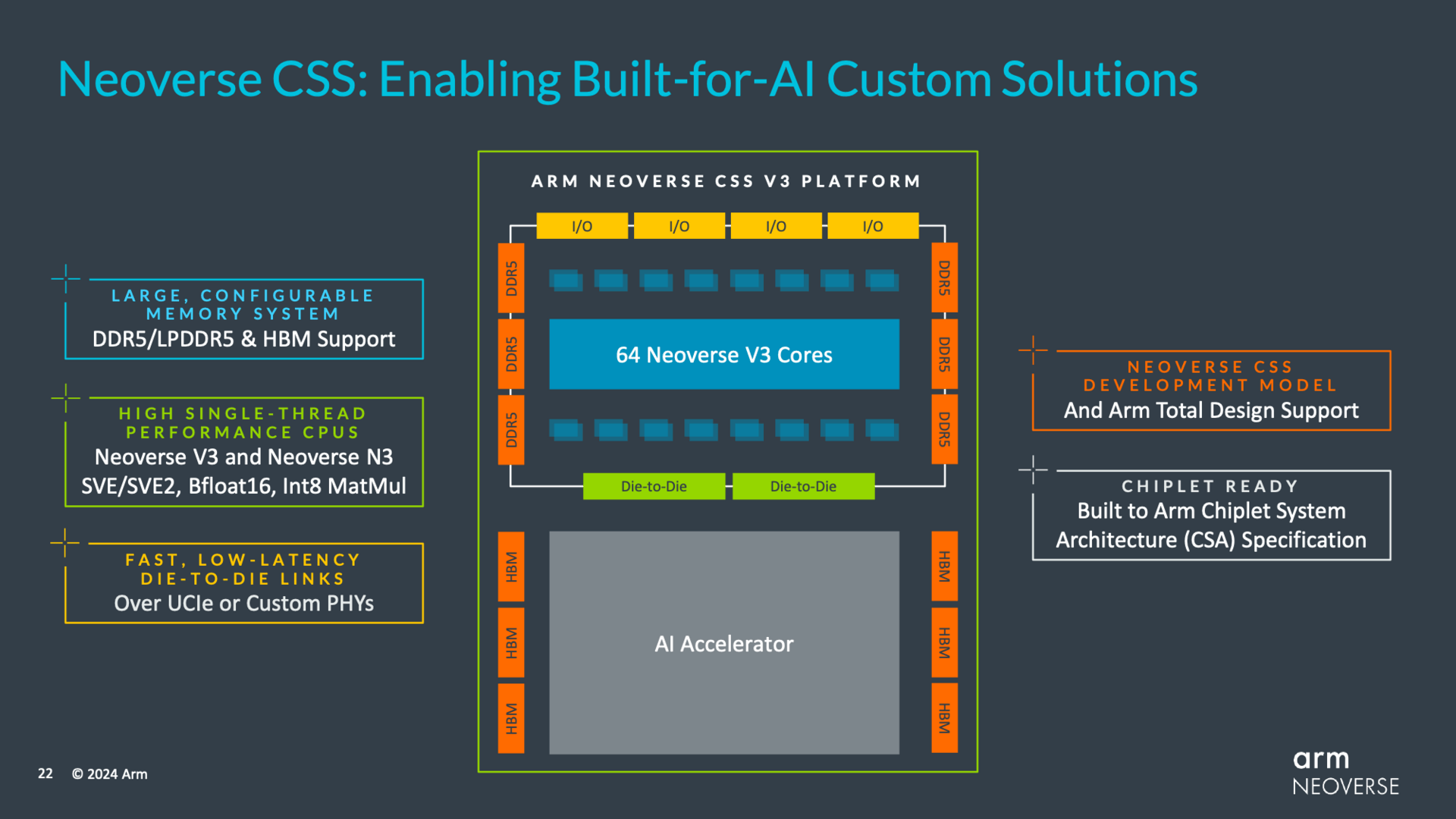
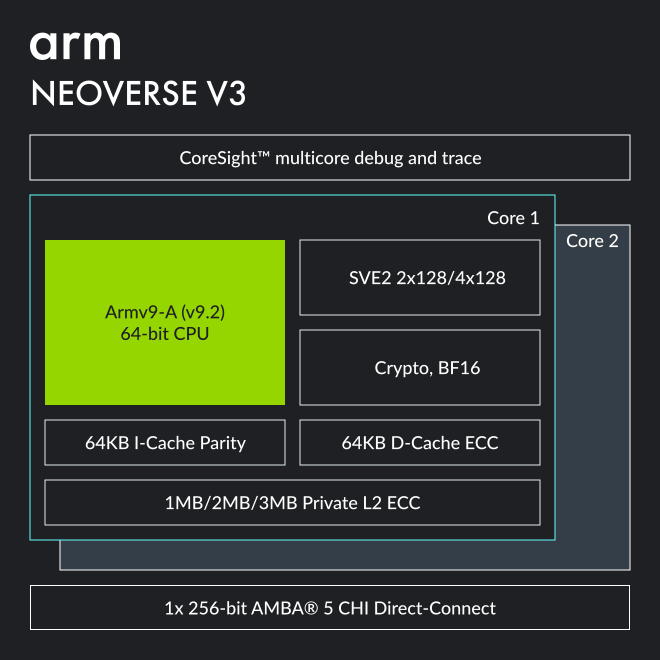
Arm Neoverse V3 für das High-End-Geschäft
Die Basis für Neoverse V3 ist die Armv9.2-A-Architektur. Pro Chip werden bis zu 64 Kerne geboten, die fortan jeweils bis zu 3 MByte L2-Cache auffahren. Das 12-Kanal-Speicherinterface unterstützt alle gängigen Speichertechnologien von DDR5 über LPDDR5 bis hin zu HBM. 64 PCIe-Lanes sind ebenfalls mit von der Partie, allerdings kein PCIe 6.0 wie einmal angestrebt, denn das ist schlichtweg noch nicht fertig. Die Leistung über mehr Kerne weiter skalieren sollen die Partner: Zwei Neoverse V3 lassen sich einfach in einem Sockel zusammenschalten, 128 Kerne sind dann gesetzt – so wie bisher auch.
Arm Neoverse N3 fürs effiziente Arbeiten
Die neuen Neoverse N3 setzt Arm auf die gleiche Architektur. Der L2-Cache pro Kern wurde auch hier angehoben, gegenüber dem Vorgänger geht es von 1 auf 2 MByte. 32 Kerne packt Arm in einen Chip, bei einer anvisierten TDP-Klasse von nur 40 Watt steht Effizienz im Fokus. Deshalb gibt es aber auch maximal ein 4-Kanal-Speicherinterface und 32 PCIe-Lanes.
Skalierbar soll auch der N3 sein: Hinab bis auf lediglich acht Kerne oder hinauf auf bis zu 192 Kerne, dann realisiert über mehrere Chips pro Sockel und weitere Sockel im System. Die Skalierbarkeit nach oben oder unten schließt explizit den L2-Cache ein, der beispielsweise auf bis zu 128 KByte pro Kern verringert werden kann, wenn das anvisierte Einsatzfeld diesen nicht benötigt.

Cherry-Picked-Benchmarks/Simulationen auch bei Arm
Beim Neoverse N3 spricht Arm von einem um 20 Prozent verbesserten Performance-zu-Watt-Verhältnis pro Kern gegenüber dem direkten Vorgänger. Angesichts dessen, dass beim N3 eine neue 3-nm-Fertigung von TSMC zum Einsatz kommt, die davon wohl vermutlich schon die Hälfte übernimmt, bleiben die Leistungssteigerungen sehr übersichtlich.

Beim V3 spricht Arm von bis zu 50 Prozent mehr Performance pro Sockel, nennt dafür aber keinen TDP-Vergleich. 50 Prozent Zuwachs gegenüber einer 400 MHz geringer getakteten N2-Plattform (und nicht V2) ist zudem ein ziemlich irreführender Vergleich, war N2 doch für einen ganz anderen Markt bestimmt und viel schwächer ausgerüstet (beispielsweise nur 1 MByte L2-Cache). Einmal mehr zeigt das, dass Herstellerbenchmarks mit extremer Vorsicht betrachtet werden müssen.

Am Ende obliegt es ohnehin dem Kunden von Arm, das Beste aus dieser neu zur Verfügung stehenden Grundlage für seinen Einsatzzweck zu bauen. Dabei haben einige große Unternehmen in den letzten Jahren viel Erfahrung gesammelt und waren auch immer mal wieder für die eine oder andere Überraschung gut.
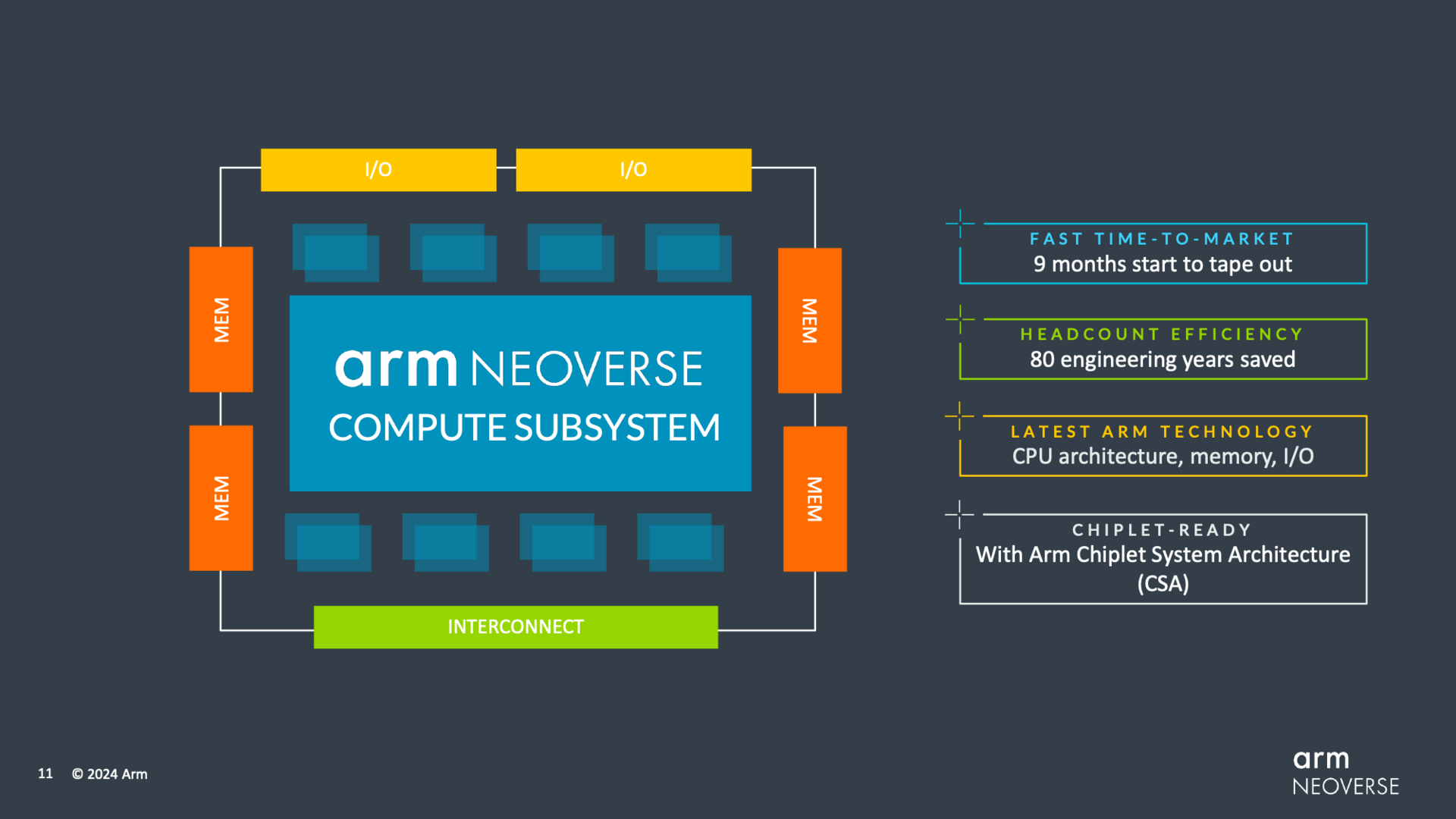
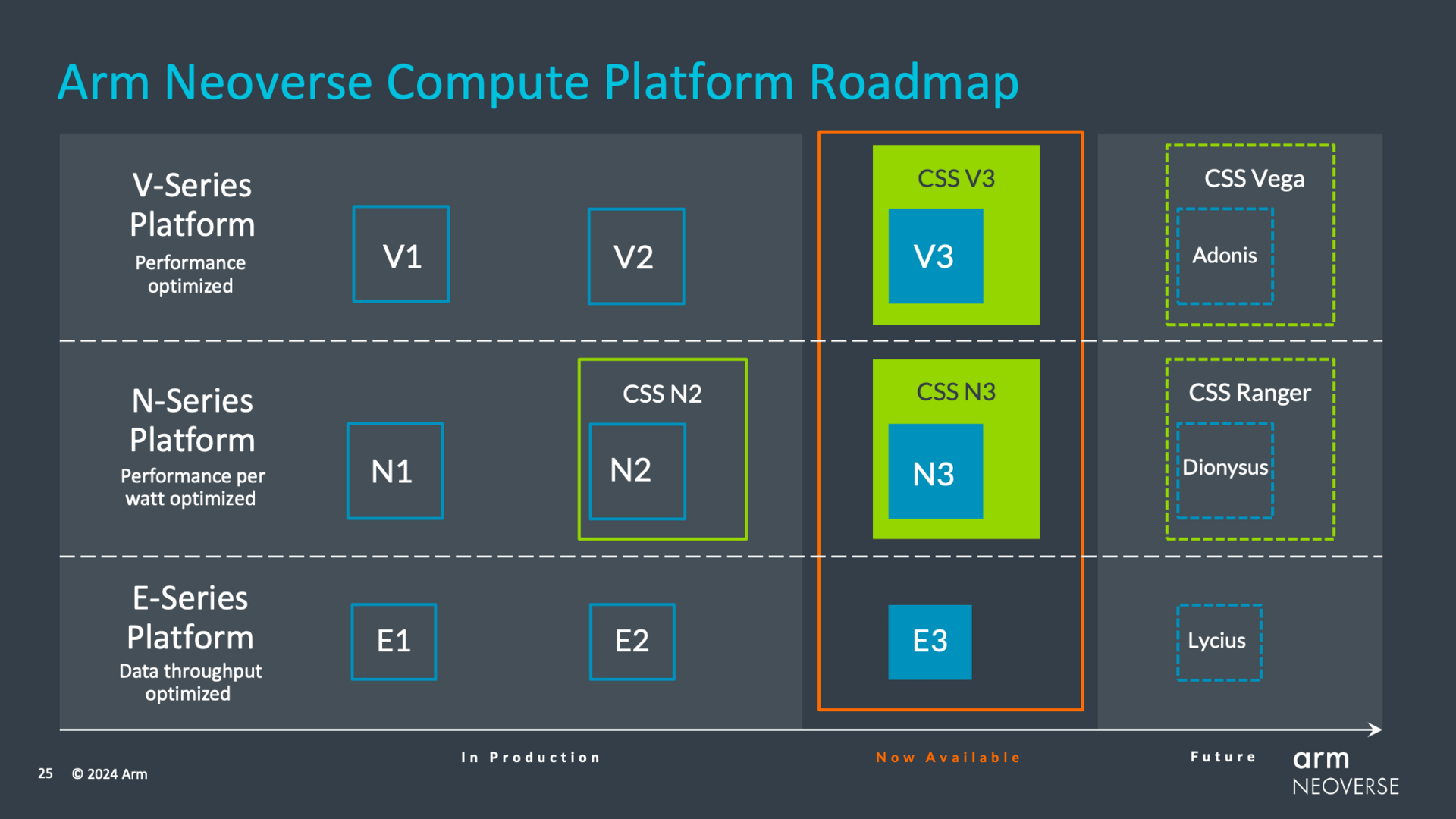
Amazon, Microsoft, Nvidia und Co. werden dabei auch weiterhin nur die Neoverse-IP statt fertige Chips einkaufen, Arm will aber auch das eigene Compute Subsystems (CSS) vermarkten: Kleinere Hersteller können hier alles aus einer Hand von Arm übernehmen und sollen so schneller und günstiger mit einem Produkt am Markt sein. Und das wird auch in Zukunft weiter gefördert, wie Arm mit einem entsprechenden Ausblick auf Neoverse V4, N4 und wohl auch E4 verdeutlicht.