ATi Radeon X800 Pro und X800 XT in der Vorschau: Goodbye, Ruby Tuesday
3/5Die Architektur
Architektur
Wie schon gesagt, besteht die Rendering-Einheit des X800 XT aus 16 Pixelpipelines, die von sechs Vertexeinheiten mit verarbeiteter Geometrie gefüttert werden. Die X800 Pro muss hier mit zwölf Pixelpipes vorlieb nehmen, bekommt aber ebenfalls sechs Vertexeinheiten.

Dass hier nicht auch eingespart wurde, erklärte Rene Froelecke von ATi damit, dass die Vertexeinheiten wesentlich weniger fehleranfällig seien als die Pixelshader, so dass hier nicht noch einmal separat selektiert würde.
Vertexshader

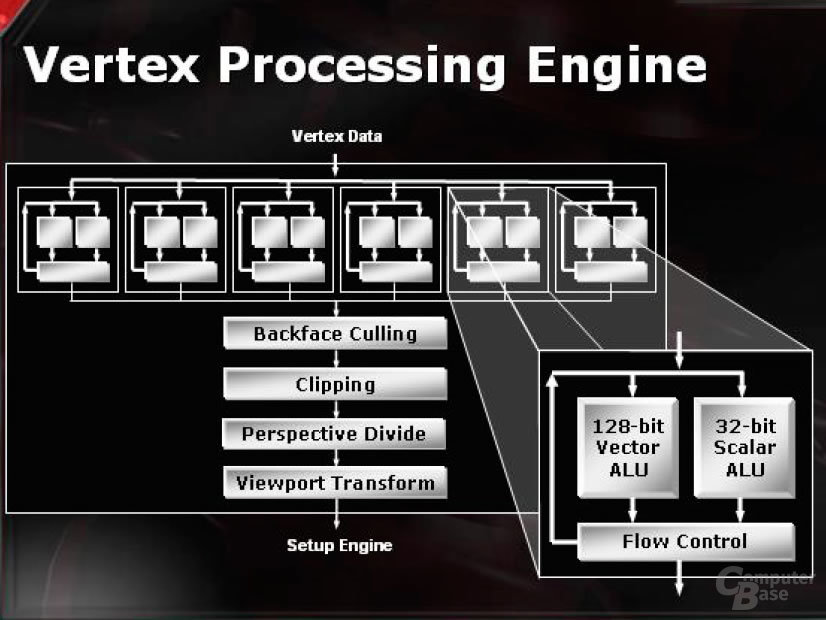
Die Vertexshader wurden gegenüber dem R360 und damit dem R300-Chip, der das Herz der Radeon 9700 Pro darstellt, kaum verändert. Nach wie vor beherrscht jede Pipeline eine Vector4 und eine Skalar-Operation simultan. Das einzig neue scheint die Abarbeitung der Sincos-Instruktion in nur einem Takt zu sein. Dies verschlang vormals bis zu acht Takte, lieferte aber immer auch Sinus und Cosinus zurück. Die Sincos-Funktion liefert als Resultat in einem Takt nur entweder den Sinus oder den Cosinus. Im direkten Vergleich braucht man für dieselbe Arbeit also zwei Takte und ist somit immer noch bis zu vier Mal schneller in diesem Spezialfall.
Die Verdoppelung des Dreiecksdurchsatzes erreicht man teils durch die zwei zusätzlichen Vertexpipelines gegenüber dem R360 auf der Radeon 9800 XT und zum anderen Teil rein durch den höheren Takt.
Pixelshader
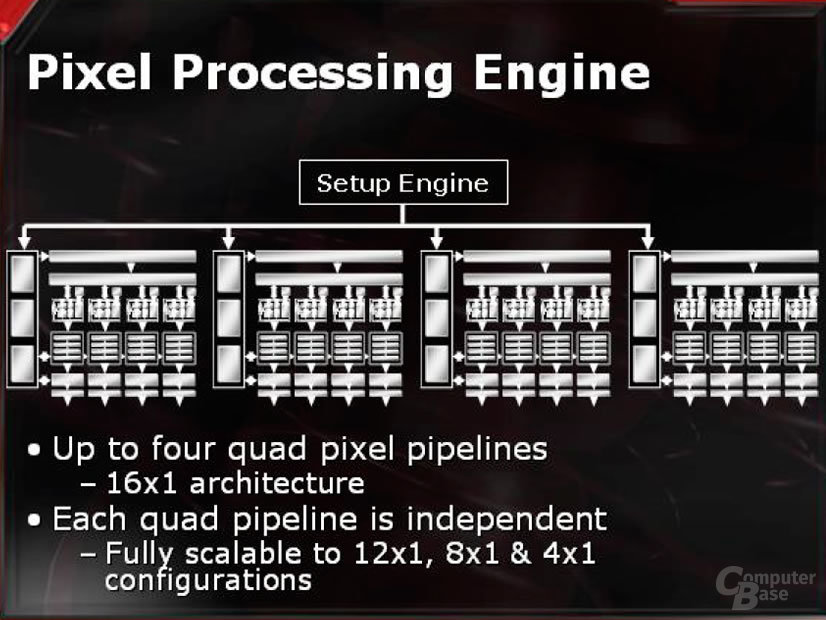
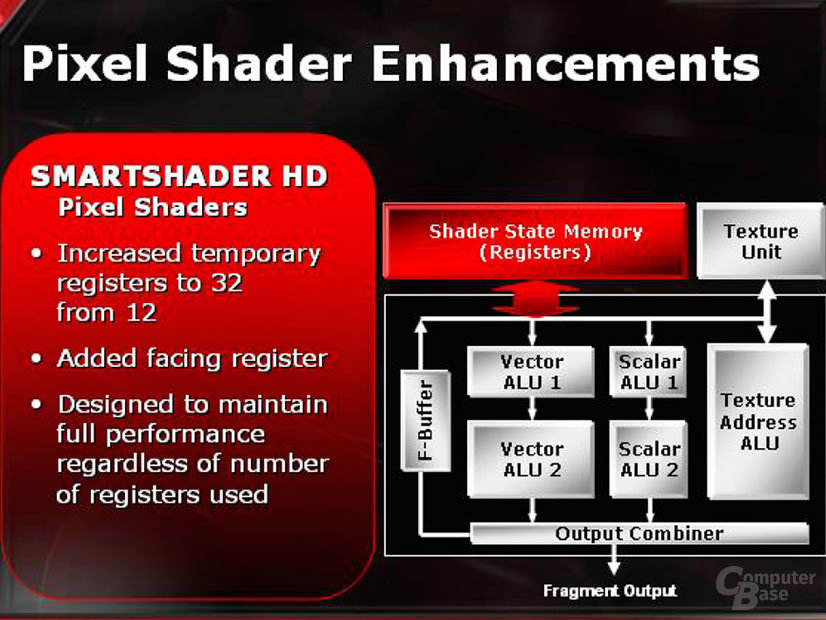
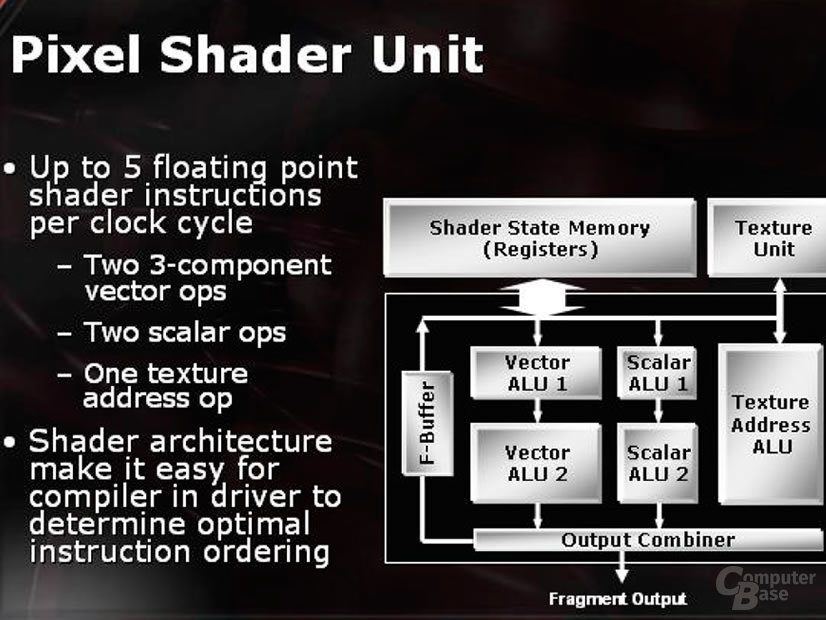
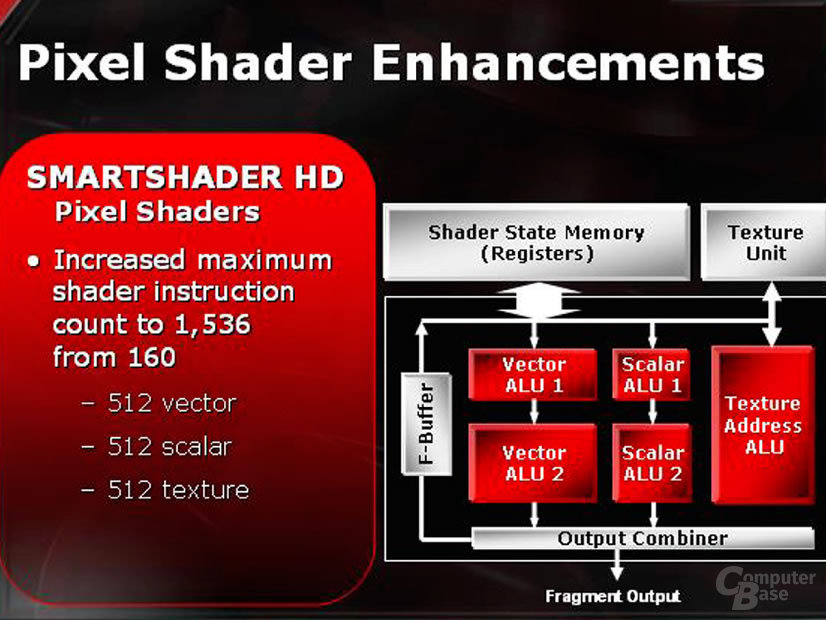


Das komplette Design des Chips ist von den Pixeleinheiten her modular ausgelegt, so dass theoretisch auch eine X800 mit nur vier aktiven Pixelpipelines vorstellbar wäre - einem Teil dieser Modularität verdankt die Radeon X800 Pro ihre Existenz, denn bei ihr wurde eines der vier „Quads“ bereits deaktiviert.
Gehen wir die Bilder von links nach rechts durch, so ist zu bemerken, dass viele Dinge bereits im R360- und R300-Chip vorhanden waren. Die vormals 12 und nun 32 „Temporary-Registers“ sind eine Sache, so stehen jetzt für jede Pipeline quasi zwei Temporäre Register zur Verfügung.
Die erhöhte Instruktionsanzahl ist ein wenig Augenwischerei, denn hier werden schlicht die Instruktionen, die die einzelnen Einheiten im Pixelshader separat ausführen können, zusammengezählt. Diese Trennung ist aber so eigentlich nicht vorgesehen, da eine Instruktion eine beliebige Ausführungseinheit ansprechen können muss. Ausserdem sind Vector- und Skalar-ALU Nummer eins und zwei nicht gleichberechtigt, bzw. befähigt. Wer sich die Relationen einmal genauer anschaut, wird erkennen, daß auch die Größen im Bild ein wenig unterschiedlich sind. Hier hat man einfach die vormaligen „Mini-ALUs“, welche schon im R300 vorhanden war, zu vollwertigen ALUs befördert - nichts anderes tat nVidia im NV40.
Den F-Buffer gibt es nun schon zum zweiten Mal als neues Feature, diesesmal sogar in Hardware. Er wird weiterhin eher ein Feature für Developer und Offline-Renderer bleiben, da die meisten Shader in aktuellen Spielen nicht einmal am Instruktionslimit von 96 der DirectX9 Spezifikation kratzen. Der Vorteil hier ist allerdings, daß der F-Buffer nun dynamisch seinen Speicher selbst allozieren kann und ihn nicht mehr im Vorfeld manuell zugeteilt bekommen muss.
Auf das letzte Feature, im rechten Bild zu sehen, namens „3dc“, gehen wir in einem separaten Abschnitt noch ein.
HyperZ HD

Im Unterschied zu den teildeaktivierten R300-Chips, die als Radeon 9500 verkauft wurden, wird in der X800--Reihe das HyperZ-Feature vollständig funktional bleiben, wenn Quads deaktiviert werden. Außerdem wurde der Buffer vergrößert, so dass nun auch Auflösungen größer als 1600x1200 von HyperZ profitieren können, so z.B. die größere der beiden HDTV-Auflösungen „1080i“.
ATi behauptet, durch ihren Z-/Stencilcache und weitere Optimierungen, bis zu 32 Z-Werte pro Takt testen zu können und damit quasi auch die Möglichkeit zu haben, einen 32x0-Modus zu aktivieren, ähnlich wie nVidia. Wir glauben jedoch, dass man hier schlicht Two-Side Stencil mit 16 Pixeln ausmultipliziert hat, womit man zwar auf 32 Z-/Stencil-Werte pro Takt käme, die aber nur auf 16 Werte im 3D-Raum eingeschränkt wären.
Speichercontroller
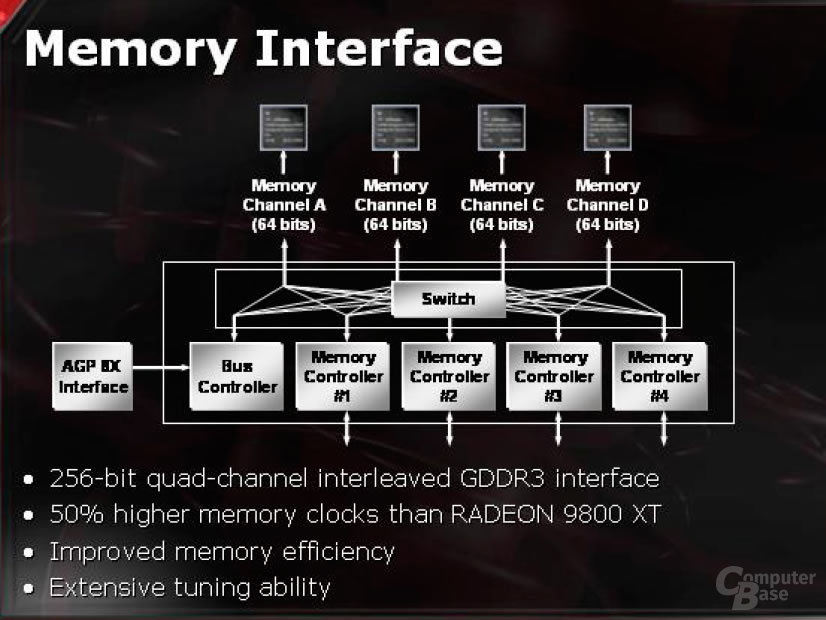
Auch die X800-Reihe wird, wie nahezu alle aktuellen Chips, über einen Cross-Bar-Speichercontroller verfügen. Dieser ist dafür zuständig, die einzelnen Read/Write-Requests der entsprechenden Ports möglichst effizient auf die vier 128 logische Bit breiten Kanäle zu verteilen.
Wenn nun aber eines oder zwei der Quads deaktiviert werden, gibt es ein Problem, wenn dieser Controller rigoros auf die Anforderungen von vier Quads zugeschnitten ist. Bei der X800-Reihe ist der Controller über den Treiber programmierbar, so dass auch die X800 Pro und eventuelle weitere Derivate optimal ausgelastet werden können.