nForce 4 SLI (Intel Edition) im Test: Markteinstieg nach Maß
3/15Geschwindigkeit
Features sind die eine Seite der Medaille, die Geschwindigkeit bildet die andere. Um sich nicht nur in Sachen Ausstattung im High-End-Segment positionieren, sondern auch gegen Intels generell sehr schnell ausgelegte Chipsätze bestehen zu können, hat nVidia dem vollkommen neu und erstmals für Intel-CPUs ausgelegten Speichercontroller besondere Beachtung geschenkt. Neben der ausschließlichen Unterstützung von DDR2 bis in Taktregionen von 333 MHz (DDR2-667) sind es vor allem drei technologische Aspekte, die den nForce 4 SLI (Intel Edition) von seinen Konkurrenten abheben sollen:
- Efficient Bus Utilization
- Dynamic Adaptive Speculative Preprocessor (DASP) 3.0
- QuickSync Technology
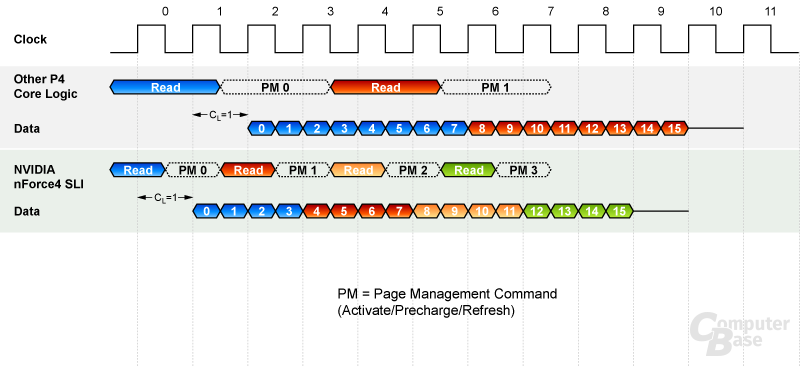
Unter „Efficient Bus Utilization“ versteht nVidia ein gegenüber Intel-Chipsätzen aggressiver ausgelegtes Speichermanagment, wobei hier sicherlich jeder Hersteller sein eigenes Verfahren als im Vorteil sieht. So greift der nForce 4 SLI (Intel Edition) mit einer Burst Length von vier und 1T-Adressierung auf den Arbeitsspeicher zu. Dies bedeutet, dass beispielsweise für den Read-Befehl nur ein Takt in Anspruch genommen wird und anschließend vier Takte lang die Daten aus dem Speicher gelesen werden. Bei einem 64-Bit-Speicherbus werden somit in einem Lesevorgang maximal 32 Byte Daten übertragen ( 64 Bit * 4 Takte / (8 Bit) = 32 Byte). Intel hingegen verwendet als Standard einen Speicherzugriff mit einer Burst Length von acht und 2T. An der Datenübertragung ändert sich zwar nichts. Allerdings kann der nForce 4 SLI (Intel Edition) theoretisch zwei weitere Speicherzugriffe (Activate/Precharge/Refresh) in derselben Zeit tätigen - vorausgesetzt, sie geschehen schnell genug.
Der „Dynamic Adaptive Speculativ Preprocessor (DASP) 3.0“ stellt die dritte Generation eines erstmals im nForce 1 eingeführten „Vor-Prozessors“ zur Sprungvorhersage dar. Um dessen Funktionsweise und Aufgabe zu verstehen, wollen wir kurz einen Abstecher zur Arbeitsweise der CPUs wagen.
Um Berechnungen durchzuführen, benötigt jeder Prozessor Daten und je schneller er rechnet, desto zügiger sollten ihm die benötigten Bits und Bytes zur Verfügung gestellt werden. Doch schneller Speicher ist schwer zu fertigen und somit teuer - sehr teuer. Aus diesem Grund rufen Prozessoren ihre Daten seit Generationen aus einer Speicher-Hierarchie ab, an deren Anfang der (heutzutage) mit dem Prozessortakt laufende Level-1-Cache (L1) und an dessen Ende der Arbeitsspeicher (oder im schlimmsten Fall die Festplatte) steht. Auch Software-Entwickler versuchen, durch die wiederholte Nutzung (temporal locality) des identischen Codes oder die Ablage dringend benötigter Daten in den höchsten Stufen der Cache-Hierarchie (spatial locality), der CPU den Zugriff auf die Daten so schnell wie nur geht zu ermöglichen.
Doch bedingt durch den immer noch nur wenige Kilobyte großen L1-Cache, einen nur unwesentlich größeren L2-Cache und den im Vergleich archiaisch anmutenden Arbeitsspeicher, würde es zwangsläufig zu unzähligen cache misses (die Daten, die die CPU benötigt, liegen nicht vor) und langen Wartepausen kommen, hätte man dem Prozessor nicht schon vor Ewigkeiten eine so genannte prefetch unit (pre = vor, to fetch = holen; frei übersetzt in „Vorhersageeinheit“) spendiert, die versucht, die Datenanforderungen der CPU zu antizipieren und somit Daten zu laden, bevor sie benötigt werden. Laut nVidia resultieren dann auch ca. 90 % der Speicherzugriffe der CPU über den Chipsatz aus genau diesen prefetch requests. Was im Umkehrschluss jedoch bedeutet, dass rund 10 % der Daten eben nicht rechtzeitig von der CPU angefordert (da vorhergesagt) wurden oder die Vorhersage falsch war und nun neue Informationen aus dem Hauptspeicher heran geschafft werden müssen.
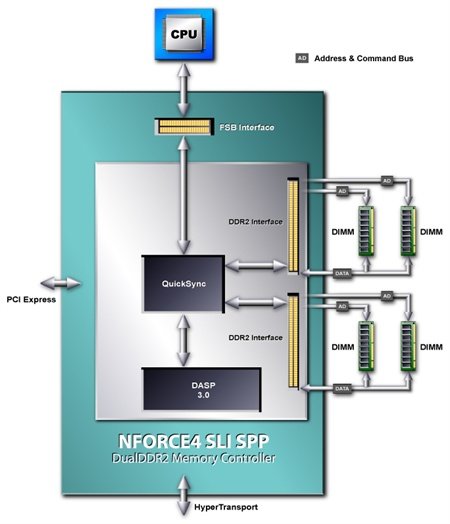
nVidias DASP 3.0 versucht nun, die Vorhersage der CPU-internen Vorhersageeinheit vorherzusagen. Klingt unglaublich, funktioniert aber genau so. Zu diesem Zweck wurden gleich eine Reihe an Pre-Prozessoren durch aufwendige (statistische) Verfahren auf die Funktionsweise der aktuellsten Prozessoren geeicht und mit möglichst effizienten Algorithmen zur Sprungvorhersage versehen. Die Pre-Prozessoren, die alle an einen so genannten „Arbiter“ angeschlossen sind, sollen in der Lage sein, jeden Thread auf jedem CPU-Core (hier nimmt nVidia die Unterstützung Intels kommender Dual-Core-CPUs also erstmals direkt in den Mund) zu analysieren, den bestmöglichen Algorithmus zur Auswahl der Daten anzuwenden und diesen über eine gewisse Lernfähigkeit, wird der Thread dann letztendlich ausgeführt, noch optimieren zu können.
Der Arbiter koordiniert die verschiedenen Pre-Prozessoren und sorgt darüber hinaus dafür, dass der GPU und den restlichen Systemkomponenten der Speicherzugriff nicht verwährt wird. Neben der Anpassung der Vorhersagealgorithmen in Hard- und Software haben insbesondere Intels Hyper-Threading-Technology und Multi-Core-CPUs die Entwicklung einer solchen Einheit erschwert. Die Größte Herausforderung dürfte somit die erfolgreiche Vorhersage der Vorhersage der Vorhersageeinheit der kommenden Extreme Editions mit zwei CPU-Kernen und HT-Technology gewesen sein. ;-)
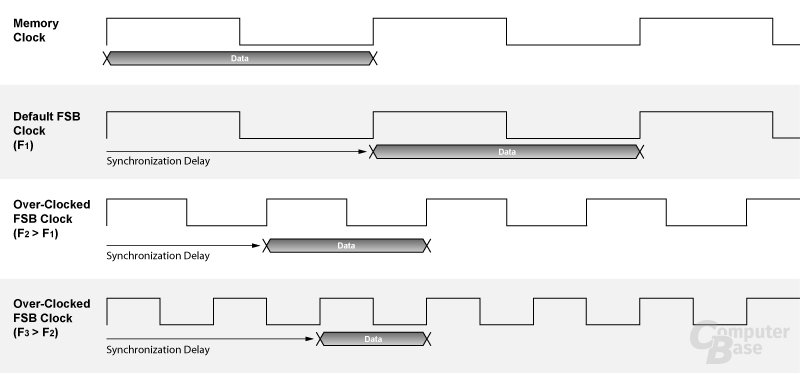
Unter der Bezeichnung „QuickSync Technology“ versteht nVidia die Optimierung der Chipsatz-Logik, die für die Synchronisation bzw. die Datenüberführung zwischen Frontside-Bus und Speicher-Bus verantwortlich ist. Neben unterschiedlichen Protokollen erschweren insbesondere voneinander abweichende Taktraten auf beiden Datenbahnen die Anpassung - ein Grund, warum auch wir in der Vergangenheit bei einer Vielzahl an Chipsätzen oftmals von einem asynchronen Betrieb, d.h. unterschiedlichen Taktraten auf FSB und Speicher, abgeraten haben.
Doch neben der Nutzung von DDR2-533/DDR2-667 auf einer FSB800-CPU (200 MHz FSB) hat nVidia auch das Übertakten als Einsatzgebiet für QuickSync im Visier. Durch die dynamische Beschleunigung des internen Datenpfades beim Übertakten von FSB und/oder Speichertakt soll sich der nForce 4 SLI (Intel Edition) auch in höheren Taktregionen nicht verschlucken und die Überführung der Datenpakete immer in der schnellstmöglichen Zeit vollführen. Das Phänomen, dass der Speichertransfer beim stetigen Übertakten urplötzlich einbricht (und das wir in nachfolgender Grafik noch einmal veranschaulicht dargestellt haben), will nVidia so aus der Welt geschaffen haben.
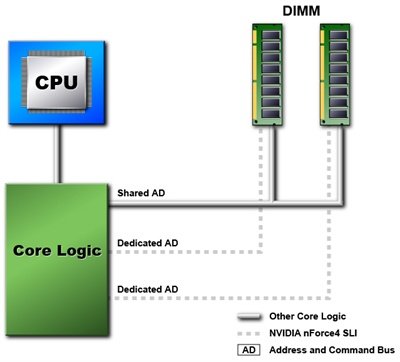
Darüber hinaus unterstützt der nForce 4 SLI (Intel Edition) den von nVidia mit dem nForce 1 ins Leben gerufenen Dual-Channel-Modus und dies auch bei einer Bestückung mit unterschiedlich großen Modulen. Die höchste Performance zeigt sich allerdings beim Einsatz gleich großer Module (finer-grain interleaving). Als letzten, komparativen Wettbewerbsvorteil gegenüber der Konkurrenz preist nVidia die Einführung eines „dedicated address bus“ an. Für die Adress-Kommunikation zwischen DIMMs und Chipsatz stehen beim nForce 4 (Intel Edition) jedem DIMM ein eigener Bus zur Verfügung, während in herkömmlichen Systemen alle Riegel über einen Bus kommunizieren. Selbst bei hohen Taktraten soll der Chipsatz auf diese Weise mit 1T-Adressierung arbeiten können.
Nach zwei Seiten Theorie wenden wir uns nun der Praxis zu.