Grafikkarten-Generationen im Test: Testergebnisse und Architekturunterschiede
2/4Leistungratings in 1.920 × 1.080 und 2.560 × 1.440
Wie im letzten Generationenvergleich wird es auch dieses Mal einen Deep Dive zu den einzelnen Architekturen geben. Um die Änderungen der einzelnen Generationen besser zu veranschaulichen und zu verstehen, ist der Blick auf die Leistungsunterschiede zwischen den Grafikkarten grundlegend.
Anders als beim Test der Radeon-Grafikkarten sind die Sprünge zwischen den Generationen bei Nvidia etwas umgedreht. Während der erste Sprung von der GTX 1070 zur RTX 2070 mit knapp 47 Prozent einem soliden Fortschritt zwischen zwei Generationen gleichkommt, legt die RTX 3070 mit knapp 67 Prozent besonders stark zu. Die RTX 4070 enttäuscht hingegen mit 25 Prozent eher.
Anders sieht es aus, wenn Raytracing in den Fokus rückt – und genau deswegen wurden drei der vier Grafikkarten in Cyberpunk 2077 mit maximierten RT-Einstellungen getestet. Auf Pathtracing wurde verzichtet. Während die RTX 4070 bei den normalen Benchmarks eher enttäuscht, kann sie bei Cyberpunk 2077 in RT auftrumpfen und legt bis zu 61 Prozent zu.
Pascal vs. Turing: radikaler Umbau
Während sich seit Tesla die grobe Struktur der GPU nicht mehr wirklich verändert hat, ist Nvidia bei Änderungen in den SMs deutlich mutiger und verändert die Struktur häufiger. Die Ausgangsbasis für diesen Vergleich ist Pascal – und doch ist letzteres nicht ganz neu und hat viele Ähnlichkeiten mit Maxwell 2.0. Entsprechend ist eine Überschrift im Test zur GTX 1080 „Pascal ist Maxwell für FinFET […]“. Vier Tiles mit 32 Shadern, acht TMUs in zwei Vierergruppen mit eigenem L1-Cache.

Im Generationenvergleich der Radeons wird bereits auf die Wave-64- und Wave-32-Befehle eingegangen und dass Nvidia sie Warp nennt. Am Design von Maxwell und auch Pascal ist zu erkennen, dass Nvidia Warp 32 präferiert. Gleichzeitig ist der Hersteller ein gutes Stück verschlossener als AMD, was Informationen zu seinen Treibern und zur Auslastung seiner Architekturen angeht.
Turing baute die SMs ähnlich wie Maxwell noch mal radikal um. Es blieb bei vier Kacheln mit eigenem Register-File und ebenso bei 32 Shadern, nur wurden sie anders gruppiert. 16 Shader waren für FP32-Berechnungen vorgesehen, 16 Shader wurden für INT32-Berechnungen reserviert. Neu dazu kamen zwei Tensor-Kerne. Die TMUs wiederum wurden von acht auf vier reduziert. Komplementiert wurde alles durch den RT-Kern.
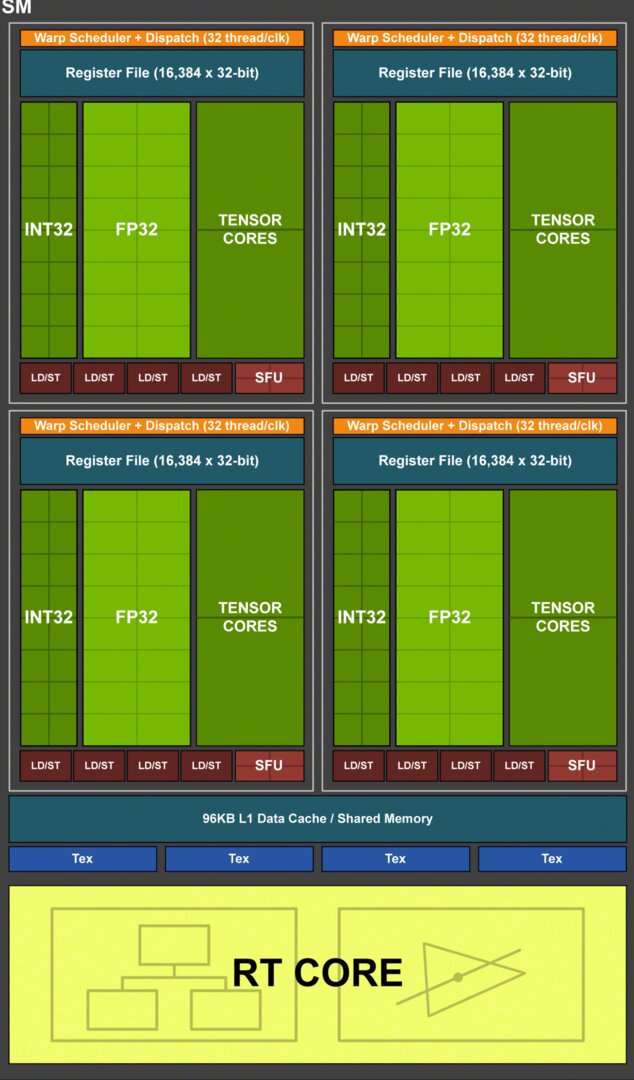
Eine SM-Kachel konnte damit pro Takt 16 INT32- und 16 FP32-Werte berechnen, der Warp-Scheduler lieferte 32 Werte. An dieser Stelle wurde aus Platz- und Komplexitätsgründen nicht auf die Unterschiede zwischen SIMD („Single-Instruction-Multiple-Data“) und SIMT („Single-Instruction-Multiple-Threads“) eingegangen. Entscheidend ist an dieser Stelle, dass pro Kachel nun zwei Warps ausgeführt wurden. Waren sie auf 32 Werte ausgelegt, benötigte jede Kachel zwei Takte für ein Warp 32.
Bei den reinen Shadern legte die RTX 2070 mit nur knapp 20 Prozent zu, der Takt ging sogar leicht zurück. Am Ende kann sich die RTX 2070 im Mittel dennoch um fast 47 Prozent absetzen, was sogar 16 Prozent mehr sind als beim Test 2018 – damals lag der Vorsprung bei ca. 31 Prozent.
Einer der Gründe sind die inzwischen vorhandenen speziellen INT-Shader. AMD hat bei GCN relativ früh versucht, einen „taktlosen“ Context-Switch einzuführen, wodurch es möglich wurde, zwischen verschiedenen Berechnungen ohne Wartezeit zu wechseln. Bei Nvidia war das nicht so einfach möglich. Jetzt können allerdings zwei Warps mit unterschiedlichen Datentypen in der Kachel ausgeführt werden und Wartezeiten werden effektiv vermindert und damit auch der Leerlauf reduziert. Gerade moderne Spiele profitieren stärker davon, ältere Titel weniger. Anno 1800, Overwatch 2 und Final Fantasy XIV legen um 20 bis 40 Prozent zu, je nach Auflösung. Modernere Games wie Cyberpunk 2077 oder Call of Duty: Modern Warfare III zeigen 50 bis 60 Prozent Zuwachs.
Turing vs. Ampere: mehr FP-Leistung
Die Änderungen bei Ampere halten sich gegenüber den Änderungen von Pascal zu Turing in Grenzen. Es blieb bei den beiden Blöcken aus 16 Shadern, nur dass der bisher explizit für INT-Berechnungen reservierte Block nun auch FP-Berechnungen ausführen konnte. Die zweite große Änderung fand sich bei den Tensor-Kernen, denn anstelle von zwei gab es nur noch einen – jedoch wesentlich mächtiger.
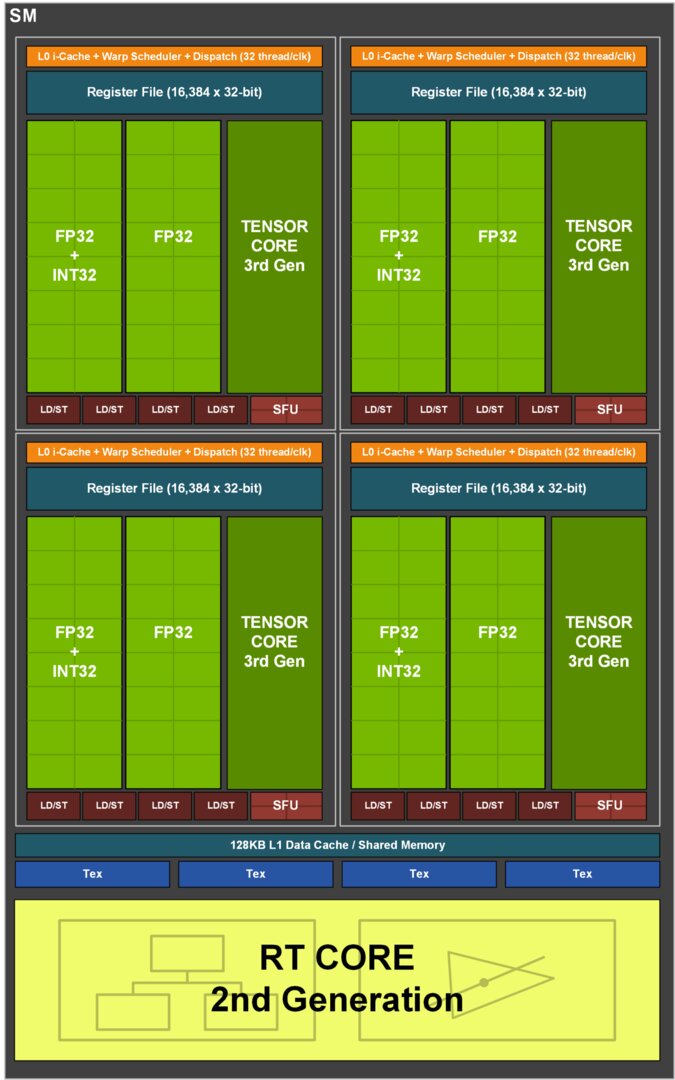
Die Anzahl der Shader für FP-Berechnungen wurde dadurch mehr als verdoppelt und statt 2.304 Shadern wurden 5.888 in die Waagschale geworfen, also ganze 156 Prozent mehr. Alleine durch diese Steigerung müsste die RTX 3070 deutlich schneller sein, es kommen jedoch im Mittel nur knapp 70 Prozent an. Ampere benötigt Auflösung für die Auslastung der Rechenwerke – und das zeigt sich auch in diesem Vergleich.
Ampere vs. Ada Lovelace: Ampere 2.0
Ada teilt sich sehr viel mit Ampere und wirkt dadurch ein wenig wie Pascal und Maxwell. Eine Evolution in bestimmten Punkten. Es blieb bei 32 Shadern in zwei 16er-Blöcken und bei einem Tensor-Kern pro Tile, sodass am Ende 128 Shader, 4 Tensor-Kerne, 4 TMUs und 1 RT-Kern in den SMs verblieben.

Da die Anzahl der Shader zwischen RTX 3070 und RTX 4070 gleich bleibt, ist in den meisten Fällen der Takt entscheidend – und der legt von 28 bis 43 Prozent zu. Am Ende reicht es im Mittel für knapp 25 Prozent Steigerung. Es zeigt sich erneut ein gewisses Auslastungsproblem der Shader.
Die große Änderung bei Ada fand in den RT-Kernen statt und hier muss „Shader Execution Reordering“ (SER) hervorgehoben werden. Die ausgehenden Strahlen treffen auf unterschiedliche Polygone und lösen damit verschiedene Shader-Programme aus. SER soll die Shader-Programme passend sortieren, sodass sie wieder besser bearbeitet werden und der Leerlauf der Shader minimiert wird.
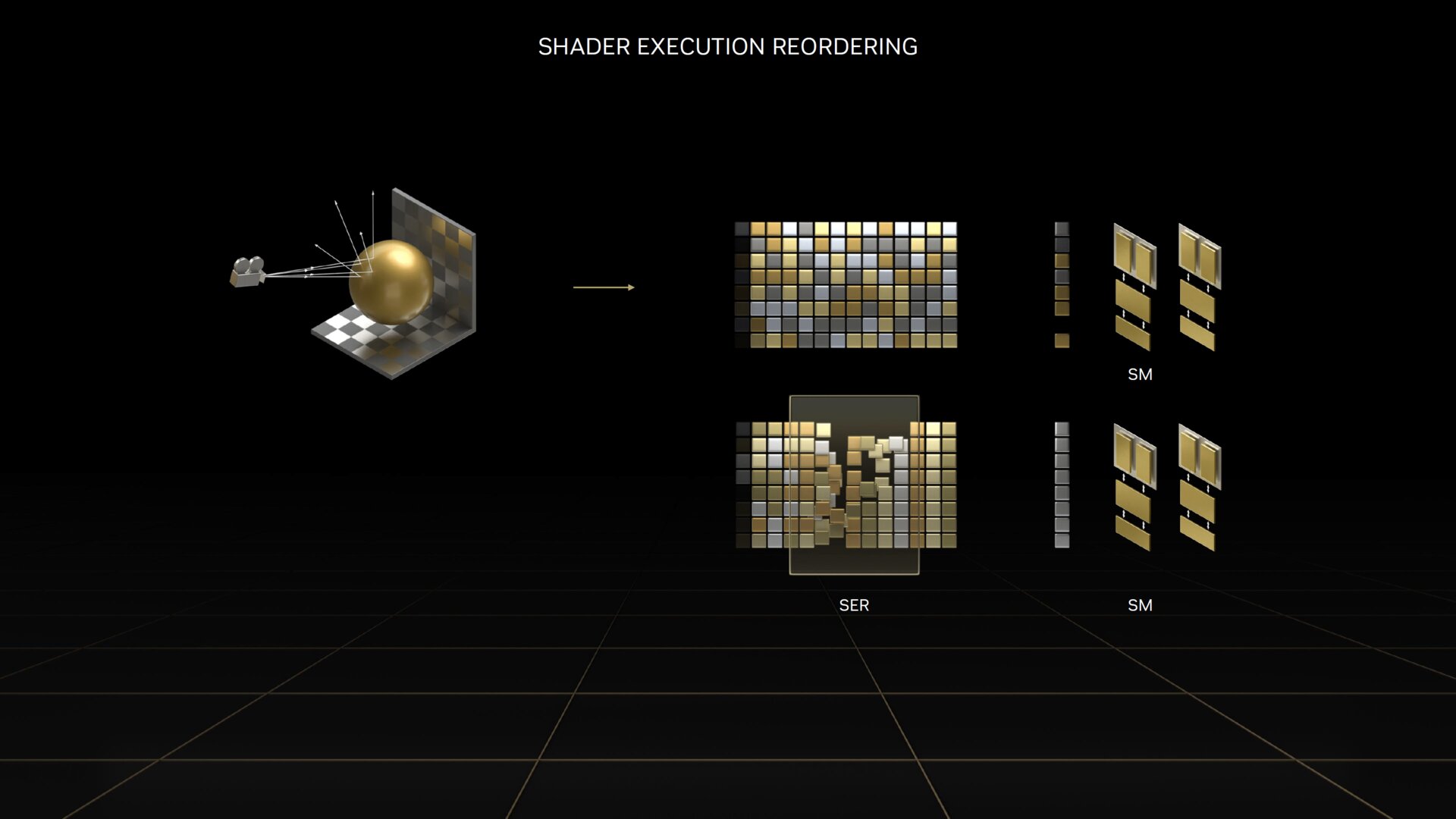
Manche Aspekte von SER funktionieren dabei on the fly, andere benötigen die Mithilfe der Entwickler und werden per NVAPI im Shader aufgerufen. So können die Speicherzugriffe optimiert werden (etwas, was auch AMD bei RDNA 3 umgesetzt hat) oder die Ausführung, um gleiche Shader zusammenzufassen.
Gerade in RT kann sich daher die RTX 4070, sofern die neuen Techniken in den Spielen verwendet werden, stärker von der RTX 3070 absetzen. Cyberpunk 2077 zeigt es deutlich.