Nvidia Vera CPU im Detail: 88 Olympus-Kerne, SMT, FP8, 1,5 TB RAM und ein Benchmark

Vera ist Nvidias neue Datacenter-CPU für den Einsatz mit Rubin-GPU (als Vera Rubin) oder als eigenständige Lösung im Rack mit bis zu 256 Prozessoren. Im Rahmen der GTC 2026 hat Nvidia weitere technische Details zu Vera verraten: Vera hat mehr Kerne, unterstützt SMT, bietet größere Caches und nutzt schnelleren Speicher.
Nvidia Vera folgt auf die aktuelle Grace-CPU, die von Nvidia unter anderem als Single-Socket-Umsetzung Grace CPU C1, im Doppelpack als Grace CPU Superchip, oder im Zusammenspiel mit Blackwell-GPUs als Grace Blackwell (Ultra) angeboten wird.
Vera kommt auch im CPU-only-Rack
Vera soll im Laufe des zweiten Halbjahres 2026 an den Start gehen. Vorgesehen sind erneut unterschiedliche Konfigurationen, etwa in Kombination mit Rubin-GPUs, oder aber als reines CPU-Rack, das sich in Nvidias Referenz-Lösung mit bis zu 256 Prozessoren bestücken lässt. Partner wie HPE gehen sogar noch weiter und verbauen bis zu 640 Vera-CPUs in einem Server-Schrank.
88 Olympus-Kerne mit SMT
Vera macht einiges anders als Grace, wie eine technische Session zur GTC verdeutlichte. Zunächst einmal bietet Vera schlichtweg mehr Kerne als Grace: 88 statt 72. Es handelt es sich zudem nicht mehr um Neoverse-V2-Kerne von Arm, sondern um ein Custom-Design namens Olympus, dem die Architektur Arm v9.2 zugrunde liegt, auf der auch Neoverse-V3-Kerne basieren. Vera sei vollständig Arm-kompatibel, erklärt Nvidia.
| Nvidia Vera Architecture Overview | |
|---|---|
| Core Architecture | Nvidia-designed Arm v9.2 Compliant Core with 6 × 128b SVE2, FP8 and MPAM |
| Core Count | 88 Olympus Cores, 176 Threads with Spatial Multithreading (SMT) |
| Cache | 2 MB L2 per Core 162 MB System Level Cache (L3) |
| Fabric | 2nd Generation Nvidia SCF (3,4 TB/s) |
| Memory Technology | LPDDR5X SOCAMM |
| Raw Memory Bandwidth | Up to 1,2 TB/s |
| Memory Capacity | Up to 1,5 TB |
| NVLink C2C | 2nd Generation NVLink-C2C (1,8 TB/s) |
| PCI Express | 88 Lanes Gen6 with x16, x8, x4, x2 Bifurcation |
Es sind in Vera aber nicht nur 16 Kerne mehr verbaut, das Design bringt erstmals auch „Spatial Multi-Threading“ (SMT) ins Spiel, sodass 176 Threads verarbeitet werden können. Im Gegensatz zu anderen SMT-Verfahren wird aber nicht auf ein Time-Slicing gesetzt, sodass „A“ und „B“ im Wechsel ausgeführt werden, sondern Vera kann bei SMT tatsächlich zwei Threads parallel über die Pipelines des Kerns verteilen.

Single Thread Mode oder SMT Mode
Dabei lässt sich Vera in zwei Modi betreiben:
- Im Single Thread Mode gibt es maximal einen aktiven Thread pro Core. Dieser Thread kann auf alle Ressourcen des Cores zugreifen, zum Beispiel auf die sechs SVE2-Pipelines.
- Im SMT Mode können hingegen bis zu zwei Threads pro Core aktiv sein. Jeder Olympus-Kern wird gegenüber dem Betriebssystem als zwei virtuelle Kerne exponiert. Die Ressourcen des Cores werden in dieser Konfiguration physisch partitioniert und stehen beiden Threads in gleicher Anzahl zur Verfügung, also etwa drei SVE2-Pipelines pro Thread. Ist im SMT Mode allerdings nur ein Thread aktiv, kann dieser wieder auf alle Ressourcen zugreifen.
Olympus ist ein 10-wide Design mit FP8-Support
Der Olympus genannte Custom-Arm-Core von Nvidia ist ein „10-wide“ Decode-Design und ist damit deutlich breiter als Grace aufgebaut. Beim Decode werden die geladenen Maschinenbefehle in interne Steuer- und Mikrooperationen übersetzt, damit die Recheneinheiten verstehen, was konkret ausgeführt werden soll.
Nvidia hat zudem den L2-Cache verdoppelt, den L1D-Cache vergrößert, mehr Vector Pipelines integriert, FP8-Support hinzugefügt und das zuvor erläuterte SMT integriert. Die Vera-CPU ist die weltweit erste Arm-CPU, die FP8-Operationen unterstützt, also denselben Datentyp, wie ihn auch Nvidias GPUs unterstützen.
| Grace Core | Vera Core | |
|---|---|---|
| Core | Arm Neoverse V2 | Nvidia Olympus |
| Arm Architecture | Arm 9.0-A | Arm 9.2-A |
| L2 | 1 MB 8-way | 2 MB 8-way |
| L1D | 64 KB 4-way | 96 KB 6-way |
| L1I | 64 KB 4-way | |
| Instruction Decode | 6-way | 10-way |
| Vector Pipelines | 4 × 128b SVE2 | 6 × 128b SVE2 |
| FP8 Support | Nein | Ja |
| Threads per Core (SMT) | 1 | 2 |
Arm MPAM hält Einzug
Das Design führt zudem Arm MPAM ein. MPAM ist eine Hardware-Erweiterung in modernen Arm-Prozessoren, die eine feingranulare Kontrolle über gemeinsam genutzte Ressourcen wie Cache und Speicherbandbreite ermöglicht. Sie erlaubt es, diese Ressourcen bestimmten Anwendungen, Prozessen oder virtuellen Maschinen gezielt zuzuweisen, zu begrenzen oder zu priorisieren.
Gleichzeitig kann MPAM überwachen, wie stark einzelne Workloads diese Ressourcen tatsächlich nutzen. Das ist besonders wichtig in Systemen mit vielen parallel laufenden Aufgaben (z. B. Cloud, Server oder AI), da so verhindert wird, dass einzelne Anwendungen den Speicher „überlasten“ und andere ausbremsen. Insgesamt verbessert MPAM also Isolation, Vorhersagbarkeit und Quality of Service im System.
Darf es von allem deutlich mehr sein?
Vera ist auch über den Olympus-Kern hinaus ein mächtigerer Chip mit mehr und schnellerem Speicher. Dessen Maximum steigt von 480 GB LPDDR5X bei Grace auf jetzt 1,5 TB SOCAMM2-LPDDR5X. SOCAMM2 ist modular, sodass bei Speicher-Defekten nicht direkt ein Vera-Board ausgetauscht respektive aufwendig repariert werden muss. Auch bei der Speicherbandbreite, der NVLink-C2C-Bandbreite beim Einsatz von zwei CPUs, dem SLC sowie dem Scalable Coherency Fabric (SCF) und weiteren Aspekten legt Vera nach.
| Nvidia Grace | Nvidia Vera | |
|---|---|---|
| Cores | 72 Arm Neoverse V2 | 88 Nvidia Olympus |
| Threads | 72 | 176 |
| Memory | Bis zu 480 GB LPDDR5X | Bis zu 1,5 TB SOCAMM2-LPDDR5X |
| Memory Bandwidth | Bis zu 512 GB/s | Bis zu 1,2 TB/s |
| SLC (L3) | 114 MB | 162 MB |
| Fabric | 1st Gen Nvidia SCF (3,2 TB/s) | 2nd Gen Nvidia SCF (3,4 TB/s) |
| Core Fabric Bandwidth | Bis zu 60 GB/s | Bis zu 100 GB/s |
Fabric verbindet Nodes mit Cores, Caches und mehr
Über das Scalable Coherency Fabric werden die Cores, der SLC, der Speicher, NVLink und I/O mit 3,4 TB/s Bisektionsbandbreite angebunden. Das Fabric gliedert sich in die Cache Switch Nodes (CSN), von denen jeder Node mit bis zu vier weitere Nodes verbunden ist. Jeder CSN verbindet bis zu zwei Olympus-Kerne und zwei Slices des SLC mit dem Mesh. Angebunden wird an den CSN auch jeweils ein Memory Switch Node (MSN), der wiederum die Verbindung zum LPDDR5X-Speichersubsystem herstellt.

Über Brücken am Nord- und Südende des Chips erfolgt die Verbindung einerseits zum NVLink-C2C (Norden), um eine Vera-CPU mit einer weiteren zu verbinden. Zum anderen wird darüber die Verbindung zum I/O-Subsystem für PCIe (Süden) hergestellt.
Vera im Benchmark gegenüber Grace
Um die Leistung von Vera gegenüber Grace zu verdeutlichen, hat Nvidia die Leistung im DCPerf Benchmark von Meta demonstriert. Dabei erfolgt das SVT-AV1-Encoding auf Multi-Core-CPUs mittels FFmpeg. DCPerf ahmt die Encoding-Pipeline von Instagram, Reels, Facebook Short Videos etc. nach. Als Datensatz wird der Open-Source-Film El Fuente von Netflix verwendet.
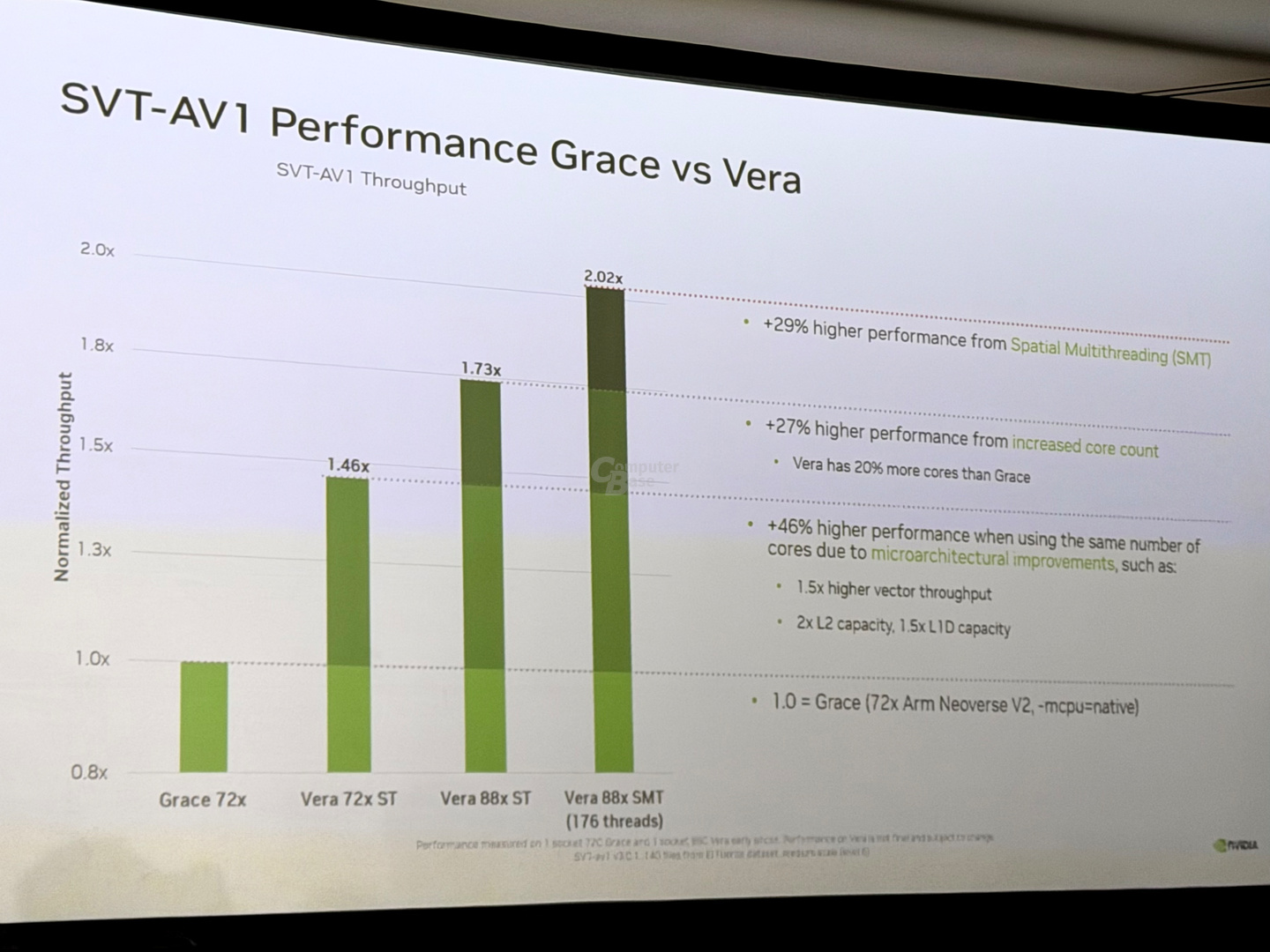
In diesem Benchmark erreicht Vera eine bis zu 2,02-fache Leistung gegenüber Grace. Das lässt sich folgendermaßen erklären: 46 Prozent mehr Leistung Im Vergleich zu Grace kommen zunächst einmal über die Verbesserungen der Mikroarchitektur von Olympus. Der höhere Vektor-Durchsatz und die größeren Caches tragen ihren Teil dazu bei. Weitere 27 Prozent kommen über die 27 Prozent mehr Kerne von Vera hinzu. Weitere 29 Prozent lassen sich mit SMT hinzufügen.
Taktraten waren kein Thema
Nvidia vergleicht dabei nach dem Ansatz „ISO Core“, also mit gleicher Anzahl von Kernen, obwohl Grace 72 Kerne und Vera eigentlich 88 Kerne bietet. Ob der Vergleich auch nach „ISO Clock“ erfolgt ist, wollten die Moderatoren der Session nicht offenlegen. Taktraten blieben ebenfalls unter Verschluss, sie sollen sich aber nicht stark voneinander unterscheiden. Bis zu 3,44 GHz sind es bei Grace.
TDP liegt bei 450 Watt
Zum Abschluss der Session folgte im Raum noch eine letzte Frage zum Verbrauch von Vera. Nvidia gibt bis zu 450 Watt pro Sockel an. Bei Grace sollen es inklusive Speicher 500 Watt sein. Vera könne mit einer TDP von minimal 250 Watt konfiguriert werden.
ComputerBase hat Informationen zu diesem Artikel von Nvidia unter NDA im Vorfeld und im Rahmen einer Veranstaltung des Herstellers in San Jose, Kalifornien erhalten. Die Kosten für An-, Abreise und fünf Hotelübernachtungen wurden vom Unternehmen getragen. Eine Einflussnahme des Herstellers oder eine Verpflichtung zur Berichterstattung bestand nicht. Die einzige Vorgabe aus dem NDA war der frühestmögliche Veröffentlichungszeitpunkt.
Dieser Artikel war interessant, hilfreich oder beides? Die Redaktion freut sich über jede Unterstützung durch ComputerBase Pro und deaktivierte Werbeblocker. Mehr zum Thema Anzeigen auf ComputerBase.