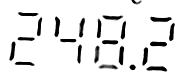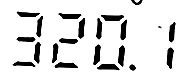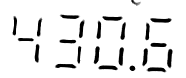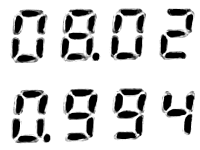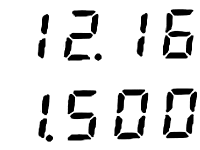Wertes Forum,
ich bin auf der Suche nach einer Möglichkeit Zahlen aus Bildern/Videos zu digitalisieren. Ich habe dazu
1. ein Video von einem Messaufbau während eines Tests gemacht
2. aus diesem Video mittels ffmpeg in einem bestimmten Intervall Bilder exportieren lassen (jeweils von den Bild-Bereichen in denen die Messwerte im Video zu sehen sind.)
Anbei sind ein paar Beispiele von den so erzeugten Bildern. Ich habe jetzt diverse online OCR-Dienste und auch den gImageReader getestet um aus diesen Bildern die Zahlen zu extrahieren - leider ohne Erfolg, obwohl ich bspw. beim gImageReader die möglichen Zeichen mit einer Whitelist (0123456789.) eingeschränkt habe.
Hat hier jemand eine Idee wie man das hinbekommen kann? Ich habe hier pro Video zwischen 100 und 1000 Bildern, die ich ungern per Hand in eine Excel übertragen würde.
Besten Dank schonmal und viele Grüße
Berti
ich bin auf der Suche nach einer Möglichkeit Zahlen aus Bildern/Videos zu digitalisieren. Ich habe dazu
1. ein Video von einem Messaufbau während eines Tests gemacht
2. aus diesem Video mittels ffmpeg in einem bestimmten Intervall Bilder exportieren lassen (jeweils von den Bild-Bereichen in denen die Messwerte im Video zu sehen sind.)
Anbei sind ein paar Beispiele von den so erzeugten Bildern. Ich habe jetzt diverse online OCR-Dienste und auch den gImageReader getestet um aus diesen Bildern die Zahlen zu extrahieren - leider ohne Erfolg, obwohl ich bspw. beim gImageReader die möglichen Zeichen mit einer Whitelist (0123456789.) eingeschränkt habe.
Hat hier jemand eine Idee wie man das hinbekommen kann? Ich habe hier pro Video zwischen 100 und 1000 Bildern, die ich ungern per Hand in eine Excel übertragen würde.
Besten Dank schonmal und viele Grüße
Berti