Die zusätzlichen Vec32 Einheiten sind extrem limitiert. Es gibt viele Rahmenbedingungen, die erfüllt werden müssen, damit diese eingesetzt werden können, z.B. betreffend der nutzbaren Anzahl an Quell-, Ziel- und Operandenregistern. Momentan lässt sich da nicht viel mehr, als FMA (A*B + shared_const bzw. A*shared_const + B) beschleunigen, und das dann auch nur, wenn sich eben beide Vec32 Blöcke dieselbe Konstante teilen. Das RDNA3 Whitepaper ist diesbezüglich sehr aufschlussreich.
Bezüglich Blender/OpenCL werden die zusätzlichen Einheiten auf Windows noch nicht genutzt. Zum Launch gabs außerdem nur OpenCL 1.x - das spricht stark für einen unfertigen Treiber bzw. Compiler.
Generell scheint RDNA3 viel stärker auf softwareseitige Optimierungen angewiesen zu sein. Es war beispielsweise üblich, dass AMDs Grafikhardware automatisch eine andere Wave bearbeitet, wenn die derzeit ausgeführte ins Stalling kommt. Der Compiler muss dies jetzt voraussehen, und manuell eine entsprechende Instruktion emittieren. Das war ein Tradeoff, um eine höhere ALU-Dichte am GCD zu erreichen.
Errata gibts auch genug (siehe Whitepaper und Mesa gitlab); Manche Instruktionen liefern falsche Ergebnisse, wenn diese innerhalb von X Takten nach bestimmten, vorherigen Instr. ausgeführt werden, oder kein Synchronisierungs, Warte- oder Cache-Flush Befehl eingeschoben wird. Das erzeugt Pipeline Bubbles und Leerlauf.
Die Raytracing Verbesserungen, wie "early Subtree Culling", oder das Benötigen von weniger Instruktionen für BHV Traversal müssen ebenfalls durch die Nutzung anderer HW Funktionalität via Compiler angestoßen werden (z.B. via ds_bhv_stack_rtn)…
Fixed function Geometriepipeline gibt es auch keine mehr. Das läuft jetzt alles über die Shader via NGG - auch hier wird eine Heuristik benötigt, die den Betriebsmodus festlegt (NGG Culling ja/nein, welche Form des Cullings, Nutzung von Streamout ja/nein, …)
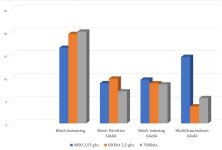
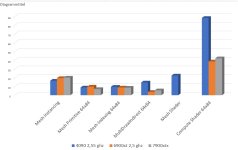
IPC Tests unter Linux (sowohl für 3D, als auch Compute) wären interessant - der Treiber lässt einen dort CUs deaktivieren; so könnte man einen relativ genauen CU für CU Vergleich ggü. RDNA2 anstellen. Dass im worst-case die 7900XTX gerade mal 5%-10% schneller ist, als eine 6900XT/6950XT (trotz 20% mehr CUs!), zeigt, dass es hier interessante Funde geben könnte.
Ich gehe auch davon aus, dass AMD mit RDNA4 einen neuen Commandprozessor benötigen wird. Dass dieser durchwegs höher takten muss, als die Shader, lässt darauf schließen, dass dieser manchmal mit der Arbeitsverteilung nicht hinterher kommt. Das Delta scheint größer zu werden, je höher der Shadertakt ist, beträgt es bei 2,3GHz auf den Shadern nur +200Mhz: In dem von GerryB eingebetteten Video sind fast 3,8GHz am Commandproc. bei ca. 3-3,1GHz auf den Shadern angeführt…
Also ein bisschen Sorgen mache ich mir schon bezüglich dieser Entwicklungen. Compilerkomplexität war das, was letztlich zum Tod von AMDs VLIW Architektur (und Intels Itanum) geführt hatte. Der hohe Stromverbrauch erinnert ein bisschen an GCN, ist aber wenigstens diesmal von einem hohen Takt begleitet, was nebenbei fast schon ein bisschen Pentium 4 Vibes aufkommen lässt