GF100 „Fermi“: Nvidias nächste Grafik-Architektur im Detail erklärt
4/6Streaming Multiprocessor (SM)
16 Streaming Multiprocessors sind auf dem GF100 vorhanden, die auf jeweils 32 „CUDA-Cores“ vertrauen. Jeder CUDA-Kern setzt sich aus einer vollwertigen Arithmetic Logic Unit (ALU) und einer Floating Point Unit (FPU) zusammen. Der GF100 ist wie die neuen Radeon-HD-5000-Karten vollständig mit dem IEEE 754-2008-Standard kompatibel, was für das GPU-Computing eine wichtige Rolle spielt.
Jeder Rechenkern kann pro Takt ein Fused Multiply-ADD (FMA) berechnen, unabhängig davon, ob es eine Single-Precision- oder eine Double-Precision-Operation ist. Der Unterschied zwischen FMA und einem normalen MADD ist in der Präzision zu suchen, da FMA die Nachkommastellen absolut Präzise bei einer Addition und einer Multiplikation berechnen kann. Dies ist jedoch primär für das GPU-Computing wichtig. Neben einem normalen MADD hatte der GT200 noch ein MUL (Multiplikation), das im GF100 nun nicht mehr vorhanden ist.
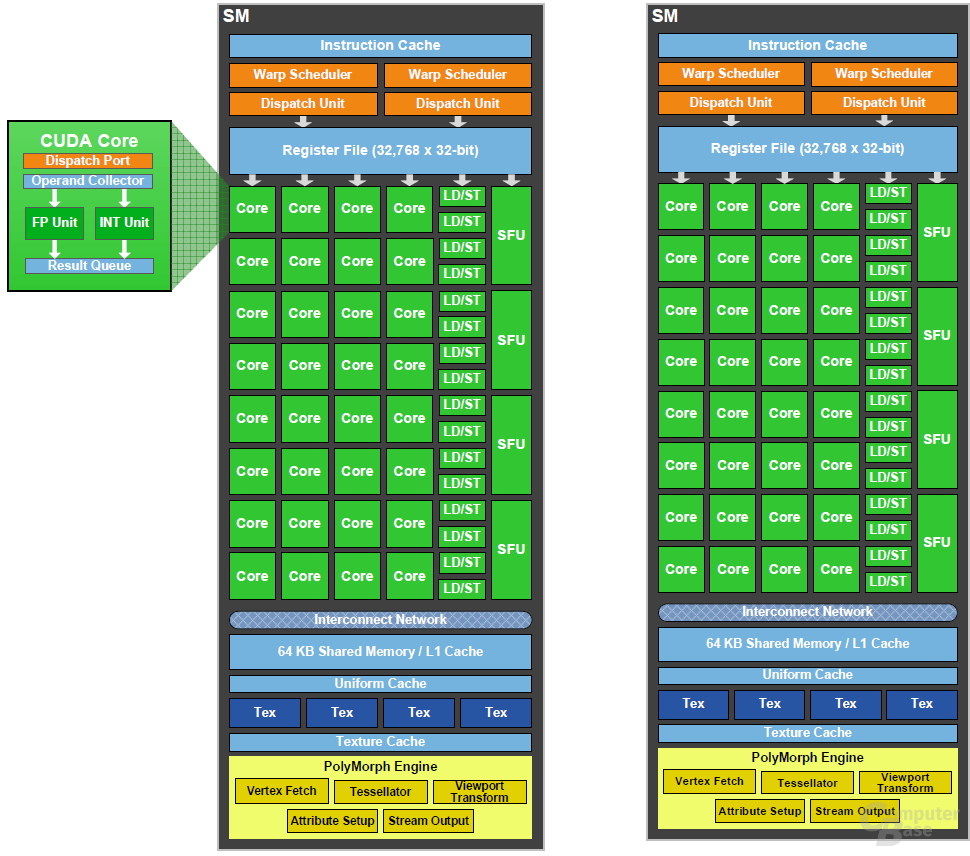
Abgesehen von den 32 CUDA-Cores gibt es in jedem Streaming Multiprocessor zusätzlich noch 16 so genannte Load-Store-Einheiten, die die Quell- und Zieladressen von 16 Threads in einem Takt berechnen und die Ergebnisse in den Cache oder VRAM schreiben können. Die GPU kann pro SM auf vier Special-Funktion-Units (SFU) zugreifen, die zum Beispiel Berechnungen wie Sinus oder Cosinus durchführen. Jede SFU kann pro Takt eine Instruktion pro Thread ausführen. Ein Warp benötigt acht Takte.
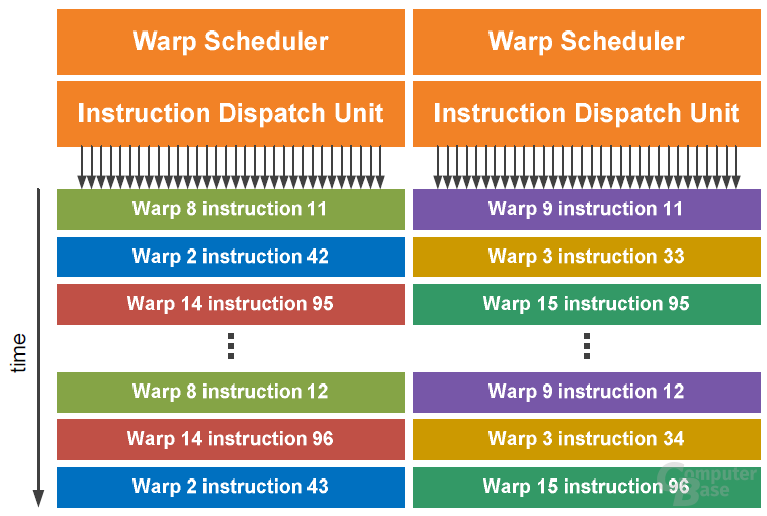
Darüber hinaus beherbergt jeder SM noch zwei „Warp Scheduler“ und zwei „Instruction Dispatch Units“. Der SM teilt die Threads in Gruppen von 32 parallelen Threads, auch Warps genannt, ein. Die Warp Scheduler suchen insgesamt zwei Warps aus und verteilen einen Thread eines Warps zu einer Gruppe von 16 ALUs, den 16 Load-and-Store- oder den vier SFU-Einheiten. Da alle Warps unabhängig voneinander ausgeführt werden können und es gleich zwei Warp Scheduler gibt, sollen alle Einheiten durchgängig mit Arbeit versorgt sein.
Textureinheiten
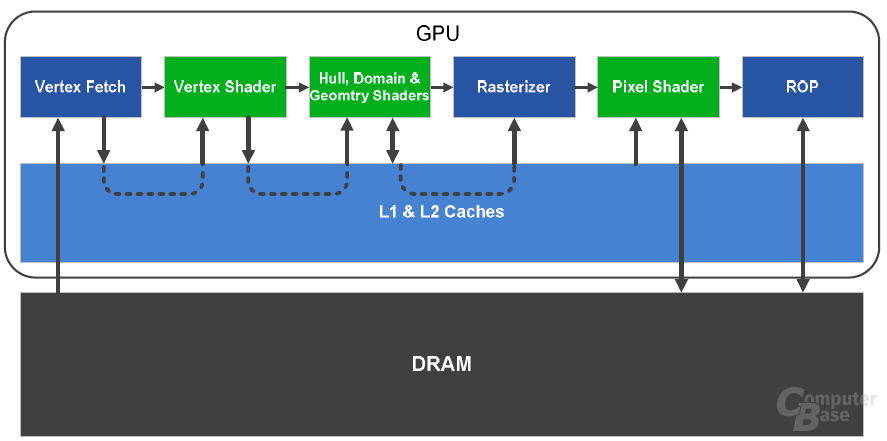
Beim GT200 sind die Textureinheiten in einem speziellen Bereich namens „Texture Processing Clusters“ zusammen gefasst. Dieser entfällt bei dem GF100, da die TMUs direkt an einem Streaming Multiprocessor angeschlossen sind. Pro SM gibt es vier Textureinheiten, insgesamt sind auf dem GF100 also deren 64 vorhanden. Obwohl der GT200 über 80 Textureinheiten verfügt, soll die entsprechende Leistung auf dem GF100 um einiges höher ausfallen, da die Effizienz massiv erhöht worden sein soll (unter anderem besserer L1 Texture Cache). Darüber hinaus haben die TMUs, ähnlich wie die Shadereinheiten, eine eigene „High-Clock-Domain“, die mit einer höheren Frequenz als der restliche Chip angesteuert wird.
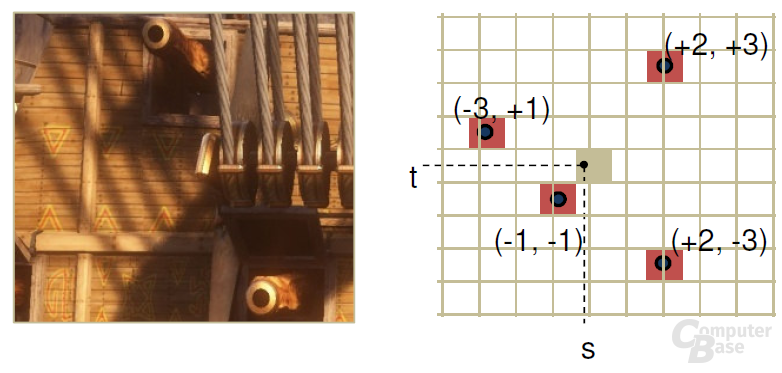
Jede TMU auf dem GF100 kann pro Takt ein Pixel adressieren sowie texturieren. Abgesehen von der Platzierung innerhalb eines SM hat Nvidia auch den Aufbau einer TMU verbessert, sodass nun vor allem Shadow Mapping sowie Screen Space Ambient Occlusion (SSAO) schneller berechnet werden können. Neben dem L1 Cache können die Textureinheiten zudem auf einen globalen L2-Cache zurück greifen, weshalb der GF100 insgesamt einen dreifach so großen internen Cache wie der GT200 hat.


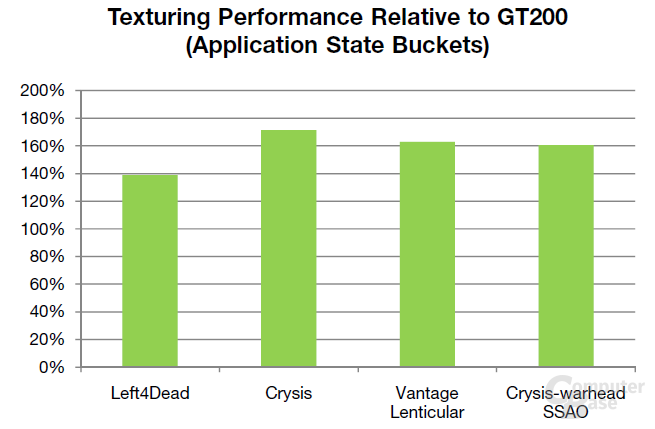
Auch das Feature-Set der TMUs im GF100 wurden verbessert, da diese nun mit BC6H und BC7 (Texturkompressionsverfahren in DirectX 11) umgehen können. Nvidia gibt einige Benchmarkwerte für die Texturleistung des GF100 an. Demnach soll diese trotz der geringeren Anzahl an TMUs 40 bis zu 70 Prozent über den Werten des GT200 liegen.
Caches im GF100
Wie bei CPUs darf ein schneller Cache (interner Speicher) auch in einer modernen GPU nicht mehr fehlen. So verfügt auf dem GF100 jeder SM über einen Shared-Memory- und einen L1-Cache. Ersterer verbessert den Speicherzugriff für Algorithmen mit einem klar definierten Speicherzugriff. Der L1-Cache kümmert sich dagegen um das Gegenteil, also um Algorithmen mit einem unbekannten Ziel. Jeder SM kann auf einen insgesamt 64 Kb großen Cache zugreifen, wobei entweder der L1-Cache 48 Kb und der Shared-Memory-Cache 16 Kb groß, oder genau das Gegenteil der Fall ist. Das Verhältnis ist frei konfigurierbar. Zusätzlich gibt es noch einen 12 Kb großen L1 Texture Cache.
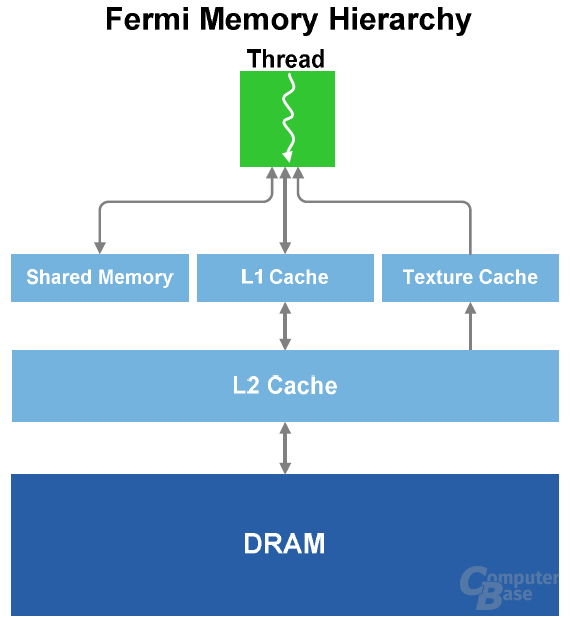
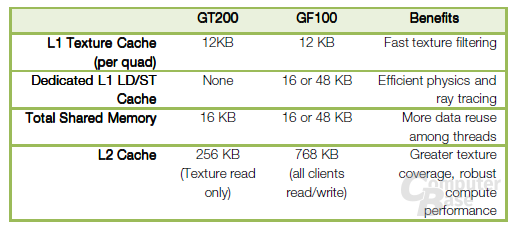
Insgesamt hat der GF100 einen 76 Kb großen L1-Cache (12 Kb Texture Cache + 64 Kb L1/Shared-Cache), während der GT200 mit 28 Kb auskommen muss. Neben dem L1- gibt es auf dem GF100 noch einen L2-Cache, der eine Größe von 768 Kb aufweist (GT200: 256 Kb). Der L2-Cache ist dafür zuständig, alle Load-, Store- und Textur-Anfragen aufzunehmen. Der L2-Cache im GF100 ist als „Unified“ ausgelegt, womit sämtliche Einheiten gleichzeitig auf ihn zugreifen können und dieser optimal ausgelastet sein soll. Der GT200 dagegen hatte für diverse Einheiten noch verschiedene Caches.