
GeForce RTX 3080: Tensor-Kerne im Vergleich zu Turing und A100

Mit der Ampere-Architektur hat Nvidia auch die mit Volta eingeführten Tensor-Kerne der GPU überarbeitet. Nachdem zunächst unklar war, inwiefern sich die Tensor-Kerne der GeForce RTX 3080 (Test) von denen der professionellen A100-GPU unterscheiden, gibt ein Nvidia-Whitepaper nun Aufschluss.
Wofür Tensor-Kerne gut sind
Tensor-Kerne sind Recheneinheiten, die speziell dafür entwickelt wurden, Matrixmultiplikationen zu beschleunigen. Der Name stammt von den mathematischen Tensoren, die bei neuronalen Netzen verwendet werden. Dort liegt auch der Einsatzzweck der Tensor-Kerne, die das Training sowie die Inferenz, die extensiven Gebrauch von Matrixmultiplikationen machen, eines neuronalen Netzes massiv beschleunigen können.
Mehr relevante Datentypen
Die erste Generation Tensor-Kerne, welche mit Volta (Titan V und Quadro GV100) eingeführt wurde, konnte lediglich mit FP16-Matrizen umgehen. In den meisten Fällen wird bei neuronalen Netzen jedoch FP32 verwendet, wobei die Umstellung auf FP16 sich negativ auf die Genauigkeit der Ausgaben auswirken kann. Mit Turing überarbeitete Nvidia die Tensor-Kerne und fügte Unterstützung für die Datentypen INT8, INT4 und INT1 ein. Da alle diese Datentypen nur sehr kleine Wertebereiche abdecken und die Eingabe quantisiert werden musste, waren ihre Anwendungszwecke limitiert.
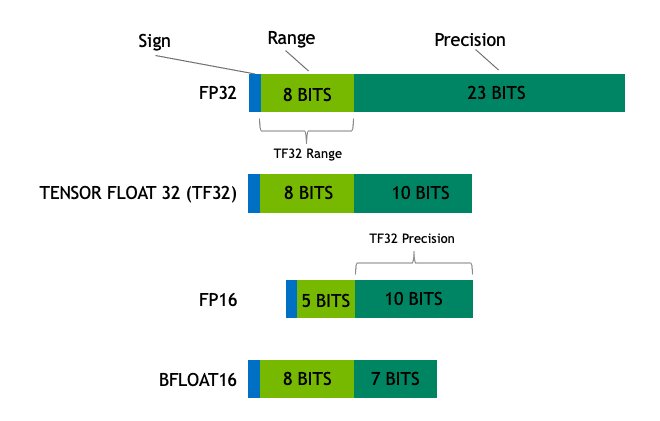
Die dritte Generation Tensor-Kerne, die in Ampere Einzug hielt, beherrscht deutlich mehr Datentypen. Die Tensor-Kerne der im Mai vorgestellten A100-GPU können zusätzlich mit FP64, TF32 und bfloat16 umgehen. Davon haben es mit TF32 und Bfloat16 die beiden relevanteren Datentypen auch auf die GA10x-GPUs geschafft, die in der GeForce RTX 3070, 3080 und 3090 zu finden sind. Bei TF32 handelt es sich um einen Mittelweg zwischen FP32 und FP16, wobei der Name etwas irreführend ist. TF32 besitzt wie FP32 8 Bit für die Darstellung des Exponenten und wie FP16 10 Bit für die Darstellung der Mantisse sowie ein weiteres Bit für das Vorzeichen. Damit besteht der Datentyp aus 19 Bits und ist somit deutlich kleiner als FP32 mit 32 Bit. Laut Nvidia entstehen aus der Verwendung von TF32 keine (bedeutenden) Genauigkeitsverluste bei neuronalen Netzen, während die Tensor-Kerne etwa 2,7 mal so schnell mit TF32 wie mit FP32 arbeiten können. Bei Bfloat16 wurde der Exponent im Vergleich zu FP16 von 5 auf 8 Bit erweitert und die Mantisse im Gegenzug von 10 auf 7 Bit verkürzt.
Da TF32 die gleiche Struktur wie FP32 aufweist (mit kürzerer Mantisse), können die Tensor-Kerne auf FP32-Eingaben arbeiten und auch wieder FP32 ausgeben. Somit ist die Umstellung von FP32 auf TF32 für Entwickler trivial und wird vollständig von Nvidias CUDA/cuDNN gehandhabt.
Weniger, aber schnellere Tensor-Kerne
Während bei Volta und Turing pro SM noch 8 Tensor-Kerne vorhanden waren, sind es bei Ampere nur noch 4. Jeder Tensor-Kern selbst arbeitet dabei aber doppelt so schnell. Damit erreicht Ampere genauso wie Turing pro SM 512 FP16-FMA-Operationen. Nvidias A100 kommt im Vergleich dazu auf 1.024 FP16-FMA-Operationen pro SM. Ein weiteres Feature, das Nvidia bei den neuen Tensor-Kernen eingeführt hat, ist, automatisch dünnbesetzte neuronale Netze zu beschleunigen (Sparsity). Dafür können die Tensor-Kerne innerhalb einer 4 Zellen weiten Struktur bis zu 2 Nullwerte bei der Berechnung von Matrixoperationen ignorieren. Dadurch können die Operationen um den Faktor 2 beschleunigt werden. Dieses Verfahren kann allerdings (vorerst) nur bei der Inferenz – also der Anwendung eines neuronalen Netzes – angewandt werden.
-
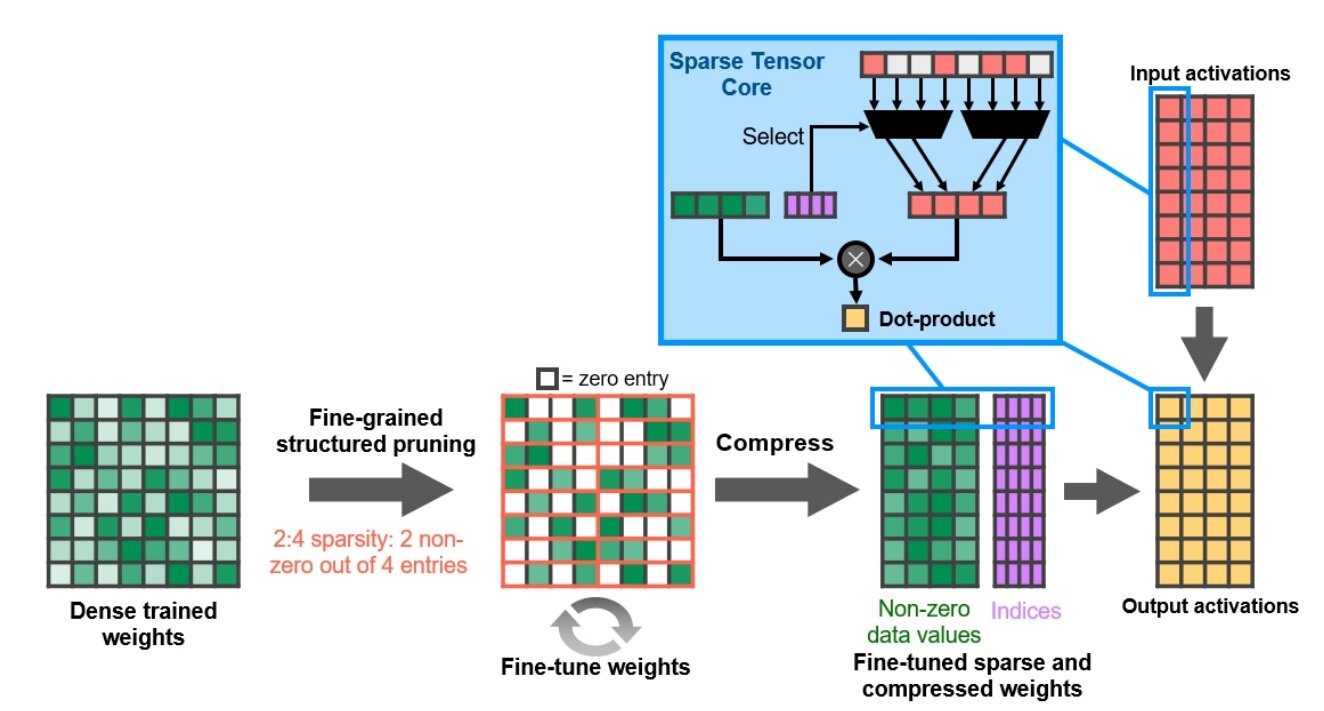 Sparsity – Ampere kann spärliche Matrizen beschleunigen (Bild: Nvidia)
Sparsity – Ampere kann spärliche Matrizen beschleunigen (Bild: Nvidia)

Hohe KI-Leistung
In der Theorie bietet Ampere in puncto KI-Training und -Anwendung auf der GeForce RTX 3080 damit nicht nur mehr Flexibilität als auf Turing und Volta, sondern auch eine bedeutend höhere Leistung. Die Rechenleistung liegt im Vergleich zu Turing in Form der GeForce RTX 2080 (Super) bei FP32 um den Faktor 2,66 und bei FP16 um 1,40 (2,80 mit Sparsity). Bei der Nutzung von TF32 ergibt sich gegenüber FP32 bei der GeForce 2080 Super ein Leistungssprung um den Faktor 2,66 (5,22 mit Sparsity). Für die Nutzung der neuen Features wird sowohl CUDA 11 als auch cuDNN 8 sowie eine angepasste Version des entsprechenden Deep-Learning-Frameworks benötigt.