Ampere: Nvidia rüstet A100 mit 80 GB HBM2e aus

Nvidia bietet die „A100 Tensor Core GPU“ auf Basis der Ampere-Architektur fortan mit 80 statt 40 GB Speicher an. Der Wechsel von HBM2 zu HBM2e erlaubt es Nvidia, auf dem gleichen SXM4-Modul nun doppelt so viel Speicher wie im Frühjahr zu verbauen. Von mehr Speicher profitieren beim KI-Training vor allem besonders große Modelle.
Nachdem der Fokus der Ampere-Architektur zuletzt auf den GeForce-RTX-3000-Grafikkarten für Spieler lag, widmet sich Nvidia heute wieder dem Supercomputing-Segment, für das die neue Architektur im Mai dieses Jahres ursprünglich zuerst vorgestellt worden war. Zur Hausmesse GTC hatte Nvidia die „A100 Tensor Core GPU“ als erstes Produkt auf Basis der GA100-GPU vorgestellt. Heute folgt mit der neuen „A100 80GB GPU“ der nächste Schritt im Bereich Supercomputing. Nvidias Ankündigung erfolgt im Rahmen der SC20, die auch AMD nutzt, um Instinct MI100 für dasselbe Segment und einen aktualisierten Fahrplan für Epyc Gen3 vorzustellen.
HBM2e mit 16 GB pro Speicherstack
Die „A100 80GB GPU“ besitzt grundsätzlich einen zur „A100 Tensor Core GPU“ vergleichbaren Aufbau, da sich die Veränderungen an der Hardware auf den Speicher beschränken. Bei diesem wechselt Nvidia für die neue Variante von HBM2 zu HBM2e. Bei HBM2e besteht ein Speicherstack aus bis zu acht übereinander gestapelten 16-Gbit-Chips, sodass mit einem Stack nun bis zu 16 GB statt der 8 GB bei HBM2, der schon bei Volta zum Einsatz kam, möglich sind. Wie bei der „A100 Tensor Core GPU“ sind am Bild gemessen vermeintlich sechs HBM2e-Stacks rund um die GPU versammelt, tatsächlich handelt es sich aber um fünf Stacks zu je 16 GB, woraus sich die insgesamt 80 GB ergeben, und einen Dummy-Stack, um den Anpressdruck des großen passiven Kühlers auszugleichen.

Samsung und SK Hynix bieten HBM2e an
HBM2e wird aktuell von Samsung und SK Hynix gefertigt, wobei Samsung pro Pin eine Datenrate von 3,2 Gbit/s und SK Hynix von 3,6 Gbit/s bewirbt. Die Speicherbandbreite für einen kompletten Speicherstack liegt demnach bei 410 GB/s respektive 460 GB/s. Auf welchen Zulieferer Nvidia vertraut, lässt sich an der beworbenen Speicherbandbreite insgesamt ablesen, die für die „A100 80GB GPU“ bei „2 TB/s +“ liegt, so Nvidia. Mit fünf Speicherstacks zu je 410 GB/s knackt Nvidia mit 2,002 TB/s die entsprechende Marke, mit dem Speicher von SK Hynix wären es hingegen knapp 2,25 TB/s gewesen.
Geht der Speicher aus, sind 80 GB im Vorteil
Von dem verdoppelten Speicher sollen beim KI-Training vor allem besonders große Modelle profitieren. Schon zur Vorstellung von Ampere hieß es, die Architektur sei für den exponentiell wachsenden Ressourcenbedarf des Trainings neuronaler Netze und das Inferencing im Datacenter entwickelt worden. Von Volta zu Ampere würden gewisse neuronale Netze eine 3.000 Mal höhere Komplexität aufweisen. Und genau für diese gestiegene Komplexität ist nun auch die „A100 80GB GPU“ ausgelegt, die bei besonders hohen Anforderungen einen teils deutlichen Vorsprung liefern soll, wenn der „A100 Tensor Core GPU“ nicht mehr genügend Speicher für die Berechnungen zur Verfügung steht.
Nvidia spricht von „enormen Anforderungen“ an den Speicher, etwa für das KI-Training bei Modellen von Empfehlungssystemen (Recommender Systems) etwa in Online-Shops, darunter DLRM (Deep Learning Recommendation Models) mit Tabellen für Milliarden Nutzer und Produkte. Im Vergleich zur 40-GB-Variante soll die 80-GB-Version einen Geschwindigkeitszuwachs um bis zu Faktor drei liefern, sodass Unternehmen diese Modelle für genauere Empfehlungen schneller neu trainieren können.
-
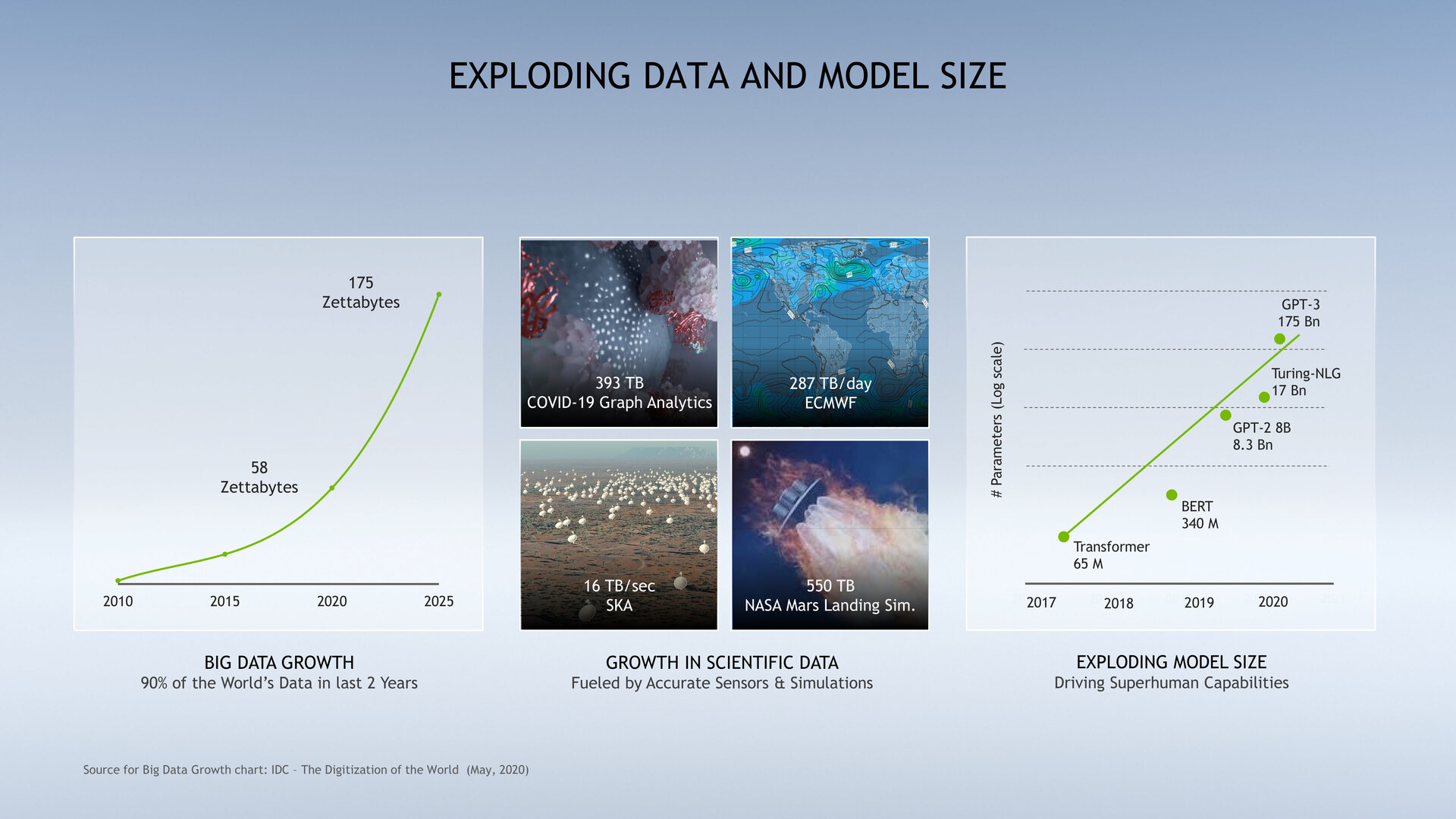 Nvidia orientiert sich an immer größeren Modellen (Bild: Nvidia)
Nvidia orientiert sich an immer größeren Modellen (Bild: Nvidia)

Weil mit der „A100 80GB GPU“ jetzt innerhalb eines DGX A100 oder HGX A100 mit bis zu acht SXM4-Modulen bis zu 640 GB angeboten werden können, lässt sich bei Sprachmodellen wie dem GPT-2, das darauf trainiert wurde, Texte mit nur wenigen vorgegebenen Zeilen selbstständig zu ergänzen, das künstliche neuronale Netzwerk nun mit deutlich mehr Parametern nutzen, ohne dass dafür eine Parallelisierung über mehrere Nodes stattfinden muss, was potenziell einen Flaschenhals darstellen könnte. Dasselbe gilt für Berechnungen auf bis zu sieben unterteilten GPU-Instanzen, denen nun jeweils 10 GB Speicher zur Verfügung stehen. Beim RNN-T-Modell für die Spracherkennung soll das Inferencing um 25 Prozent auf einer GPU-Instanz zulegen.
Benchmarks im Terabyte-Bereich zur Datenanalyse im Einzelhandel attestieren der „A100 80GB GPU“ eine Verdoppelung der Geschwindigkeit. Bei wissenschaftlichen Anwendungen etwa zur Wettervorhersage oder zur Quantenchemie erwartet Nvidia ebenfalls massive Zugewinne gegenüber der bisherigen Ausführung mit 40 GB. Quantum Espresso, eine Suite für elektronische Strukturberechnungen und die Materialmodellierung, erziele auf nur einem Node mit „A100 80GB GPU“ den beinahe zweifachen Durchsatz.
GPU mit 54,2 Milliarden Transistoren
Von den Veränderungen am Speicher und den davon abgeleitet neuen Optionen für die multiplen GPU-Instanzen abgesehen bleibt die „A100 80GB GPU“ das vom Mai bekannte Produkt. Die zugrundeliegende GA100-GPU, die mit Teildeaktivierung genutzt wird, wird nach Volta erneut bei TSMC, nun aber im N7-Verfahren mit Immersionslithografie (DUV), gefertigt. Mit 54,2 Milliarden Transistoren auf 826 mm² ist die GA100-GPU der laut Nvidia weltweit größte 7-nm-Chip. Die GPU-zu-GPU-Kommunikation findet bei Ampere über den zweimal schnelleren NVLink der dritten Generation mit 600 GB/s statt.
| A100 80GB | A100 | Tesla V100 | Tesla P100 | |
|---|---|---|---|---|
| GPU | GA100 | GV100 | GP100 | |
| Architektur | Ampere | Volta | Pascal | |
| Fertigung | TSMC N7 | TSMC 12FFN | TSMC 16FF | |
| Transistoren | 54,2 Mrd. | 21,1 Mrd. | 15,3 Mrd. | |
| GPU Die Size | 826 mm² | 815 mm² | 610 mm² | |
| Board | SXM4 | SXM2 | SXM | |
| TDP | ? | 400 Watt | 300 Watt | |
| SMs | 108 | 80 | 56 | |
| TPCs | 54 | 40 | 28 | |
| FP32 Cores/SM | 64 | |||
| FP32 Cores/GPU | 6.912 | 5.120 | 3.584 | |
| FP64 Cores/SM (exkl. Tensor) | 64 | |||
| FP64 Cores/GPU (exkl. Tensor) | 3.456 | 2.560 | 1.792 | |
| INT32 Cores/SM | 64 | NA | ||
| INT32 Cores/GPU | 6.912 | 5.120 | NA | |
| Tensor Cores/SM | 4 | 8 | NA | |
| Tensor Cores/GPU | 432 | 640 | NA | |
| GPU Boost Clock | 1.410 MHz | 1.530 MHz | 1.480 MHz | |
| Peak FP16 Tensor TFLOPS (mit FP16 Accumulate) |
312/624* | 125 | NA | |
| Peak FP16 Tensor TFLOPS (mit FP32 Accumulate) |
312/624* | 125 | NA | |
| Peak BF16 Tensor TFLOPS (mit FP32 Accumulate) |
312/624* | NA | ||
| Peak TF32 Tensor TFLOPS | 156/312* | NA | ||
| Peak FP64 Tensor TFLOPS | 19,5 | NA | ||
| Peak INT8 Tensor TOPS | 624/1.248* | NA | ||
| Peak INT4 Tensor TOPS | 1.248/2.496* | NA | ||
| Peak FP16 TFLOPS (Non-Tensor) | 78 | 31,4 | 21,2 | |
| Peak BF16 TFLOPS (Non-Tensor) | 39 | NA | ||
| Peak FP32 TFLOPS (Non-Tensor) | 19,5 | 15,7 | 10,6 | |
| Peak FP64 TFLOPS (Non-Tensor) | 9,7 | 7,8 | 5,3 | |
| Peak INT32 TOPS | 19,5 | 15,7 | NA | |
| Texture Units | 432 | 320 | 224 | |
| Speicher | HBM2e | HBM2 | ||
| Speicherinterface | 5.120 Bit | 4.096 Bit | ||
| Speichergröße | 80 GB | 40 GB | 16/32 GB | 16 GB |
| Speichertakt | 1.594 MHz | 1.215 MHz | 877,5 MHz | 703 MHz |
| Speicherbandbreite | 2.040 GB/s | 1.555 GB/s | 900 GB/s | 720 GB/s |
| * Mit Sparsity-Beschleunigung | ||||
Rechenleistung steigt mit TF32- und Sparsity-Beschleunigung
Die verfügbare Rechenleistung ändert sich durch die Verdoppelung des Speichers nicht, sofern es sich nicht um die beschriebenen speziellen Anwendungsszenarien handelt, wo durchaus teils massive Zuwächse zu erwarten sind. Auch die „A100 80GB GPU“ kommt in der Spitze (Peak) auf 9,7 TFLOPS für FP64, 19,5 TFLOPS für FP32, 312 TFLOPS für FP16 und 624 TOPS für INT8. Für Single-Precision FP32 kommt bei Ampere standardmäßig das von Nvidia eingeführte Zahlenformat TF32 für Multiply-Add-Rechenoperationen auf der dritten Generation der Tensor Cores zum Einsatz.

Bei TF32 stehen wie bei FP32 8 Bit für den Exponenten und wie bei FP16 10 Bit für die Mantisse zur Verfügung. Nvidia will damit ein neues hybrides Format schaffen, um mit 8 Bit großen Variablen wie bei Single-Precision FP32 mit der 10 Bit Genauigkeit von Half-Precision wie bei FP16 umgehen zu können. Dies wiederum wird mit der Sparsity-Beschleunigung kombiniert, mit der Nvidia häufig nicht benötigte Verbindungen eines neuronalen Netzes, die nicht zur genauen Vorhersage beitragen, loswerden will. Die dicht verwobene Matrix des neuronalen Netzes soll zu einer ausgedünnten (sparse) Matrix umgewandelt werden und effizienter sowie schneller ausgeführt werden. Die A100 und ihre Tensor Cores der dritten Generation sind für diese Sparsity-Beschleunigung optimiert worden, die bei TF32, FP16, BFLOAT16, INT8 und INT4 zum Einsatz kommt.
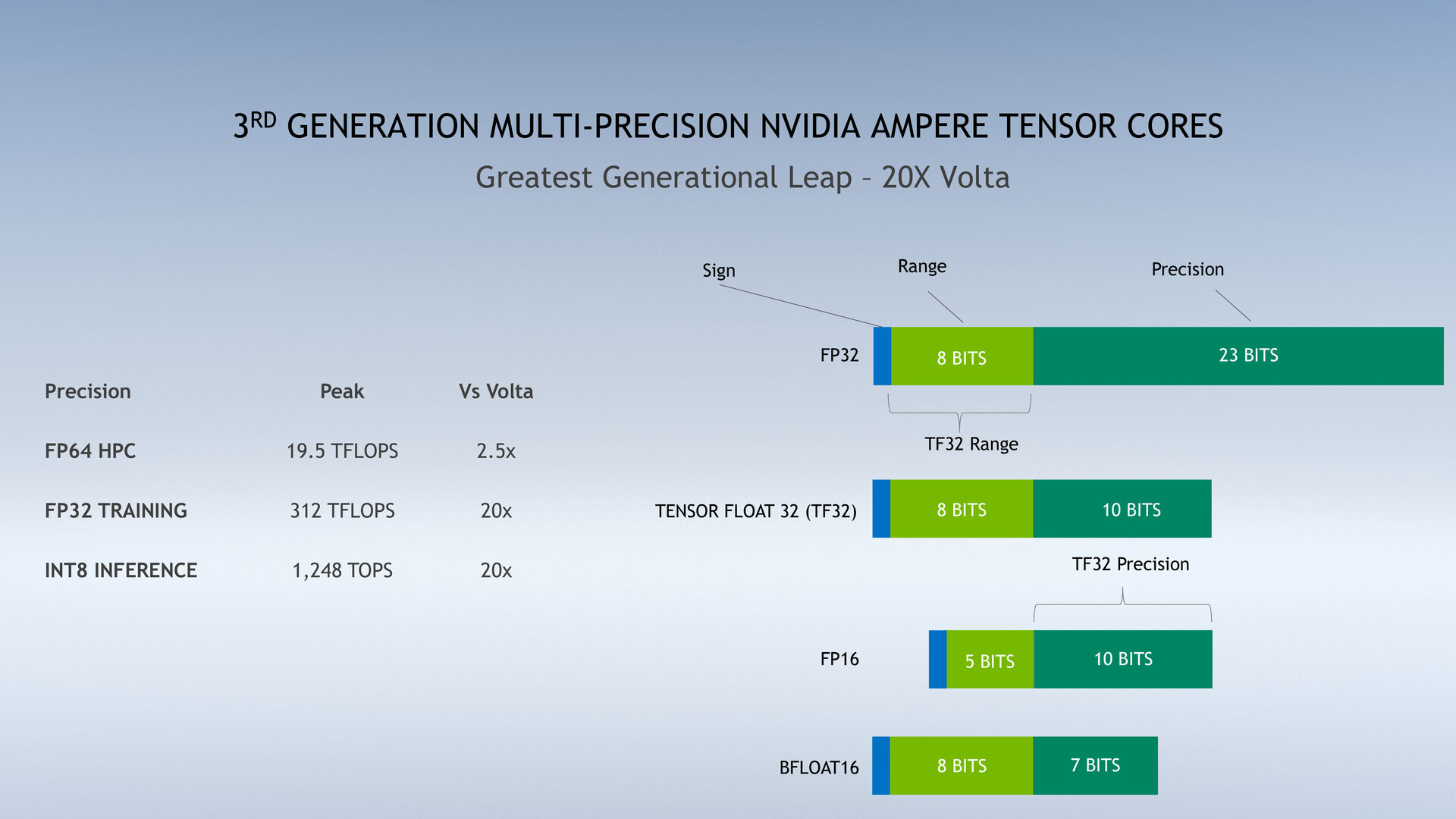
Das wiederum erklärt den immensen Leistungssprung für FP32 und INT8 bei Ampere, der nur dann vorliegt, wenn das neue Zahlenformat TF32 respektive die Sparsity-Beschleunigung zum Einsatz kommen. Aus 16 TFLOPS für FP32 bei der GV100-GPU werden so 160 TFLOPS für TF32 (als neuer Standard für FP32-Operationen) auf der A100-GPU. Und mit der neuen Sparsity-Beschleunigung wiederum werden daraus dann die propagierten 20 Mal höheren 312 TFLOPS mit Sparse TF32. Das gleiche Prinzip gilt für INT8-Operationen beim Inferencing, das von ehemals 60 TOPS bei GV100 zu 625 TOPS bei A100 und schließlich 1.248 TOPS bei A100 mit Sparse INT8 wächst.
DGX A100 und HGX A100 wechseln zu 80 GB
Die „A100 80GB GPU“ soll dieses Quartal in Nvidias eigenem KI-Server DGX A100 und der neuen DGX Station A100 verfügbar sein – mehr dazu in einem gesonderten Artikel. Im Verlauf des ersten Halbjahrs 2021 ist die Verfügbarkeit auf Servern mit HGX A100 geplant. HGX A100 ist Nvidias Plattform, mit der Partner wie Atos, Dell, Fujitsu, Gigabyte, Hewlett Packard Enterprise, Inspur, Lenovo, Quanta und Supermicro eigene Server in Konfigurationen mit vier oder acht „A100 80GB GPU“ anbieten können.
ComputerBase hat Informationen zu diesem Artikel von Nvidia unter NDA erhalten. Die einzige Vorgabe war der frühest mögliche Veröffentlichungszeitpunkt.
Die Reader's Choice Awards 2026