StefanPahl
Cadet 1st Year
- Registriert
- Sep. 2017
- Beiträge
- 10
Hallo zusammen,
Ich habe folgendes Problem. Ich habe ein Word Dokument erhalten, benutze selber word 2016. Wenn ich dieses Dokument öffne, sind die meisten, nicht alle, der Wörter rot unterstrichen und ganz oben steht "Compatibility Mode".
Wenn ich einen Text aus diesem Dokument übersetzen will, erhalte ich einen Buchstabensalat, das Dokument is also irgendwie korrupt?
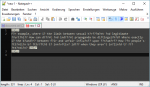
Ich habe zwei Beispiele angefügt, Beispiel 1 zeigt wie der Text im Dokument aussieht. Beispiel 2 zeigt das Ergebnis der Übersetzung mit deepl.


Ich habe folgendes Problem. Ich habe ein Word Dokument erhalten, benutze selber word 2016. Wenn ich dieses Dokument öffne, sind die meisten, nicht alle, der Wörter rot unterstrichen und ganz oben steht "Compatibility Mode".
Wenn ich einen Text aus diesem Dokument übersetzen will, erhalte ich einen Buchstabensalat, das Dokument is also irgendwie korrupt?
Ich habe zwei Beispiele angefügt, Beispiel 1 zeigt wie der Text im Dokument aussieht. Beispiel 2 zeigt das Ergebnis der Übersetzung mit deepl.