
Inference Prefill: Nvidia will mit Feynman auf CPX-Chip zurückkommen

Schon zur GTC-Keynote am Montag vermisste die ComputerBase-Redaktion den Rubin-CPX-Chip. Von Ian Buck, VP & General Manager, Hyperscale und HPC bei Nvidia, erhielt die Redaktion nun eine Antwort, warum er denn nicht mehr auf der Roadmap zu sehen war. Demnach will Nvidia mit Feynman statt Rubin auf die CPX-Lösung zurückkommen.
Erst vor einem guten halben Jahr hatte Nvidia den Chip überhaupt enthüllt. Nvidia Rubin CPX mit GDDR7 war auf brachiale Rohleistung für einen hohen Inferencing-Durchsatz ausgelegt, vor allem für den FP4-Bereich. Passend dazu war die Lösung dann auch auf Nvidias Roadmaps vertreten. Zur Eröffnungskeynote der GTC 2026 am Montag war von Rubin CPX aber nichts mehr auf der Roadmap zu sehen.
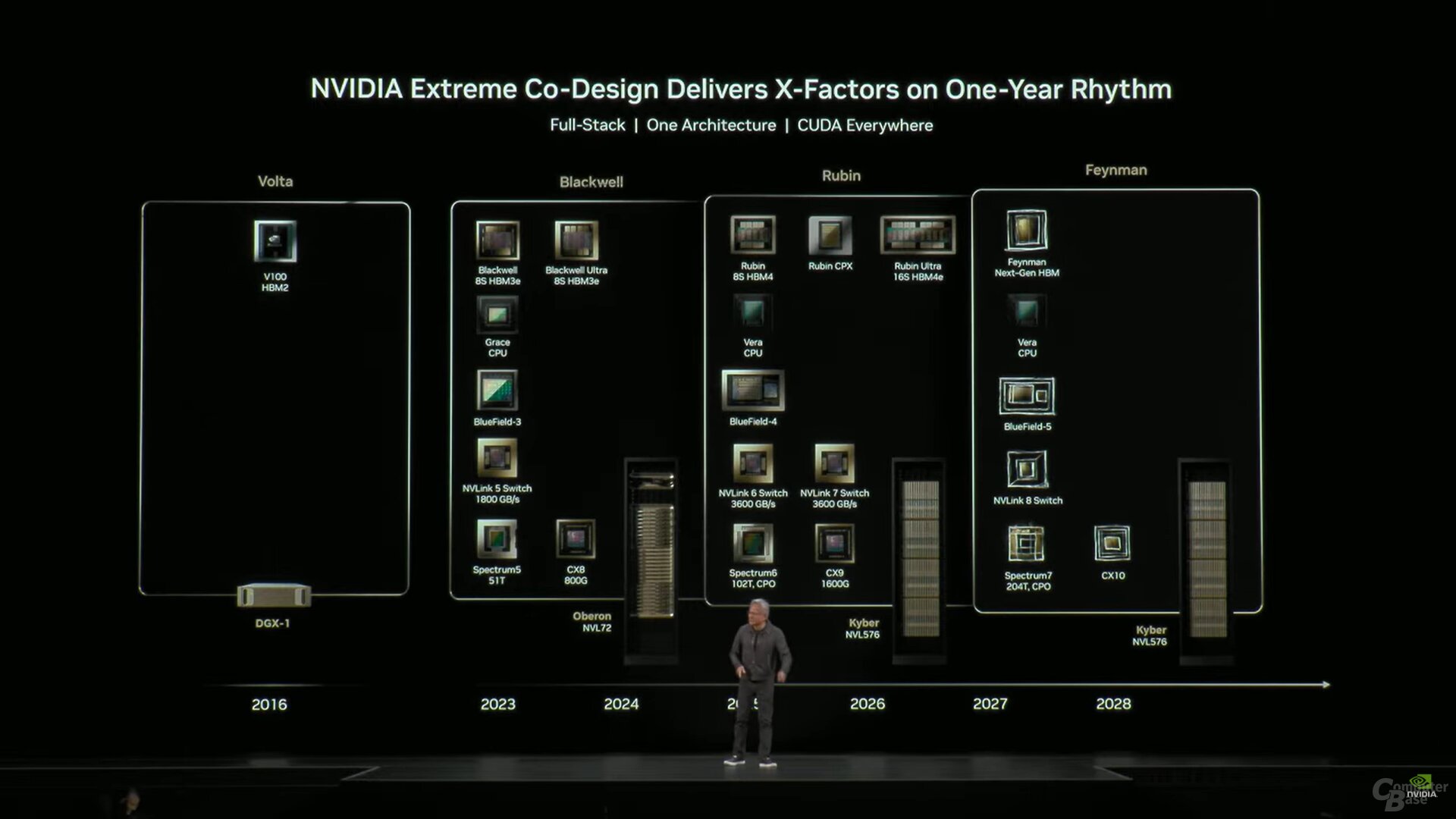

In einem Roundtable mit Ian Buck, verantwortlich für alle Hyperscale- und HPC-Produkte von Nvidia, bestätigte der Manager, dass bei Rubin der Fokus nun auf der Groq-Lösung liege, um die eigentliche Token-Geschwindigkeit zu erhöhen statt nur die Zeit bis zum ersten Token zu reduzieren. Die Idee sei damit aber nicht vom Tisch, mit bei Feynman, also der nächsten Chip-Generation, werde Nvidia darauf zurückkommen.
Der CPX-Chip hatte auch seine Stärken, beim Prefill hätte diese Lösung durchaus geholfen, nicht aber bei der eigentlichen Token-Ausgabe. Der Fokus ist nun erst einmal auf die schnelle Token-Generierung gewechselt, und dafür sei das zur GTC 2026 enthüllte LPX-Rack mit den neuen Nvidia Groq 3 LPU besser geeignet.
Die LPU übernimmt (zum Teil)
Für die bei Inference wichtige, sehr schnelle Token-Generierung für Echtzeit-KI-Anwendungen setzt Nvidia nun also auf Groqs Language Processing Unit (LPU). Diese nutzt eine deterministische Architektur ohne Caches, Branch-Prediction oder dynamisches Scheduling. Weil der Compiler jede Operation und jeden Datenfluss im Voraus plant, entstehen exakt vorhersehbare Laufzeiten. Das Ergebnis ist ein Inference-Beschleuniger mit konstanter und sehr niedriger Latenz. Für sehr kurze Zugriffszeiten und eine hohe Bandbreite sorgt dabei auch ein 500 MB großer On-Chip-SRAM.
Statt den CPX-Chip aber wie ursprünglich einmal geplant noch in dem regulären NVL72-Rack unterzubringen, werden die LPUs in einem separaten Rack daneben gestellt. Am Ende soll das Gesamtpaket so ein breiteres Spektrum des Marktes mit effizienten Lösungen für ihre Probleme abdecken.
ComputerBase hat Informationen zu diesem Artikel von Nvidia im Rahmen einer Veranstaltung des Herstellers in San Jose, Kalifornien erhalten. Die Kosten für An-, Abreise und fünf Hotelübernachtungen wurden vom Unternehmen getragen. Eine Einflussnahme des Herstellers oder eine Verpflichtung zur Berichterstattung bestand nicht.
- CB-Funk-Podcast #162: Jensen mag keinen „AI Slop“, FSR 4.1 und Death Stranding 2
- MB. Drive Assist Pro: Level 2++ im Mercedes mit Nvidias Drive AGX Orin ausprobiert
- Was macht DLSS 5?: Nvidias Antwort in einem Satz ist „die KI weiß, was sie tut“
- +20 weitere News