nVidia GeForce 8800 GTX im Test: Der neue König unter den Grafikkarten
4/36Technik im Detail Part 2
Raster Operation Processor (ROP):
Der G80 auf der GeForce 8800 GTX setzt auf insgesamt 24 ROPs, die in sechs verschiedene Partitionen eingeteilt sind. Auf der GeForce 8800 GTS hat nVidia eine dieser Partitionen deaktiviert, womit die GPU nur noch auf 20 Rops zurückgreifen kann. Eine dieser Partitionen kann insgesamt vier Pixel mir Farb- sowie Z-Werten (Tiefeninformationen) pro Takt fertigstellen. Wie ab der GeForce-FX-Serie gewohnt, beherrschen die GeForce-ROPs bei reinen Z-Berechnungen die Möglichkeit, die Rechenkraft um ein vielfaches zu steigern. So lange einzig Tiefeninformationen berechnet werden, können nicht 24, sondern 192 Samples pro Takt zur weiteren Nutzung bereit gestellt werden. Bei 4xMSAA bleiben noch 48 Samples pro Takt übrig.
Doch damit noch nicht genug. Auch das Anti-Aliasing wurde auf dem G80 kräftig aufgebohrt. Neben dem gewohnten 2-fach- und 4-fach-Modus, gibt es nun eine 8-fach- sowie 16-fach-Einstellung mit acht beziehungsweise 16 einzeln verteilten Multi-Sample-Anti-Aliasing-Samples – auf das hybride SSAA muss der G80-Käufer allerdings verzichten. Neu ist das so genannte „Coverage Sample AA“, das eine gute Bildqualität bei kaum geringerer Performance ermöglichen soll. 16xCSAA soll dieselbe Optik wie 16xMSAA aufweisen, jedoch nur einen leicht höheren Geschwindigkeitsverlust als 8xMSAA haben. 8xCSAA soll dagegen so aussehen wie herkömmliches 8xMSAA und nur gering schlechter als 4xAA den Dienst verrichten. Erreicht wird dies durch eine spezielle Komprimierung der Farb- und Z-Werte. Diese Methode funktioniert aber nicht mit jedem Spiel. In 3D-Applikationen, in denen Stencil-Schatten eingesetzt werden, funktioniert CSAA nicht.

Die Direct3D-10-Spezifikationen schreiben es vor und der G80 hält dies ein: Die Rede ist hier von FP32-Blending, sprich 128 Bit High Dynamic Range Rendering. Die alten Grafikkarten unterstützten nur FP16-Blending, was ein Zwischenschritt zwischen der herkömmlichen Farbtiefe und dem „richtigen“ HDRR ist. Mit FP32-Blending sollen Spiele ermöglicht werden, die eine noch ausgefeiltere Farbdarstellung und Präzision aufweisen, als es beispielsweise in Far Cry möglich ist. Der G80 kann zudem sowohl auf ein FP16- als auch auf ein FP32-Rendertarget MSAA anwenden – harte Kanten wie auf einem G7x werden einem erspart bleiben. Um die Featureliste zu vervollständigen, kommt der G80 mit FP16- und FP32-Filtering daher. Bei Floating-Point-Formaten kann also direkt in der TMU gefiltert werden; ein Umweg über den Pixelshader, so wie es auf dem R5x0 nötig ist, bleibt der GPU erspart.
Speicherinterface:
Seit der legendären Radeon 9700 Pro gehört ein 256 Bit breites Speicherinterface zum guten Ton einer High-End-Karte. Doch damit ist nun Schluss. nVidia trennt sich von der vertraut gewordenen Zahl und verbaut auf der GeForce-8800-Serie ein 384-Bit-Speicherinterface (GeForce 8800 GTX) beziehungsweise eine 320-Bit-Anbindung (GeForce 8800 GTS). Möglich wird dies durch einen sechsfach aufgeteilten Memorycontroller, der jeweils mit einem 64 Bit breiten Interface an den VRAM angebunden ist. Bei der GeForce 8800 GTS ist der Speichercontroller nur noch fünffach aufgeteilt, was einer Breite von 320 Bit entspricht. Anders als bei der Radeon X1950 XTX setzt nVidia auf der GeForce 8800 nicht auf modernen GDDR4-RAM, sondern belässt es bei kostengünstigeren GDDR3-Bausteinen. Der 768 MB große VRAM auf der GeForce 8800 GTX (12 RAM-Bausteine mit je 64 MB) taktet mit 900 MHz, während der 640 MB fassende Speicher der GeForce 8800 GTS (10 RAM-Bausteine mit je 64 MB) mit einer Frequenz von 800 MHz arbeitet.
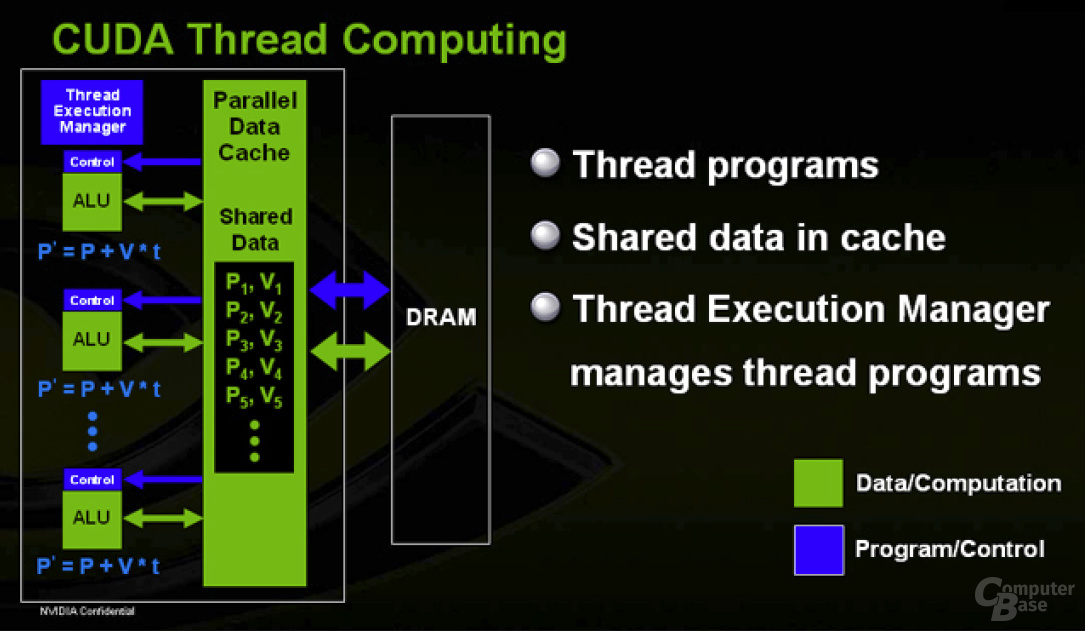
Dynamic Branching:
Dynamic Branching (Sprunganweisungen im Shadercode, durch if-, else, then-Befehle) gehört spätestens mit dem Shader-Model 3.0 zum guten Ton eines 3D-Beschleunigers, wobei jedoch längst nicht immer Wert auf eine gute Performance gelegt wurde. So ist das Dynamic Branching auf dem R5x0 im Pixelshader zwar extrem schnell, die Geschwindigkeit im Vertex-Shader lässt aber zu wünschen übrig – genau anders herum sieht es beim G7x aus.
Beim G80 soll dies nun anders werden, da Dynamic Branching im Shader-Model 4 eine wichtige Rolle spielt. Der G80 kann einen Shader nun in ein 4x4 Pixel großes Feld unterteilen und aufgrund dessen effizientere und genauere Berechnungen ohne einen allzu großen Verschnitt durchführen. Im Vergleich dazu teilt der R580 den Shader in einen 4x12 Pixel großen Block ein, arbeitet also etwas ineffizienter.
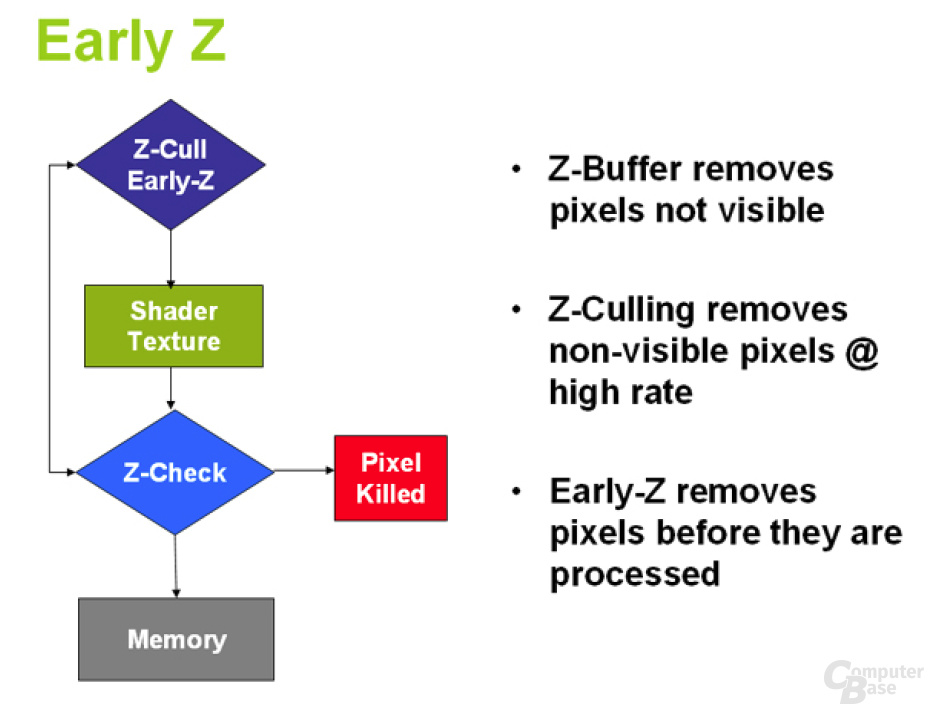
Early-Z:
Auch wenn die Speicherbandbreite bei GeForce 8800 GTX und GeForce 8800 GTS massiv gestiegen ist, so kann es sich der G80 dennoch nicht leisten, verschwenderisch mit dieser wichtigen Ressource umzugehen. Um dies zu verhindern, arbeiten moderne 3D-Beschleuniger mit speziellen Z-Mechanismen, die bei gewissen Pixelblöcken erkennen können, ob diese komplett oder teilweise von anderen Pixel überdeckt werden, somit unsichtbar sind und nicht mitberechnet werden müssen. Eine dieser Techniken nennt sich „Early-Z“, das nVidia auf dem G80 verbessert hat. Z-Cull ermöglicht es, nicht sichtbare Pixelblöcke in der Rasterization-Stage (noch vor dem Pixelshader beziehungsweise den Streamprozessoren) zu verwerfen. Dies soll der G80 vier mal so schnell wie eine GeForce 7900 GTX durchführen können. Zudem wurde eine Technik implementiert, die es ermöglicht, einzelne Pixel, noch bevor diese die ROPs durchlaufen, zu entfernen. Vor allem bei langem Shadercode ergeben sich so Vorteile. Wie nVidia uns auf Nachfrage mitteilte, wurde der On-Chip-Speicher auf dem G80 für das Hidden Surface Removal aufgestockt, damit die bandbreitenschonenden Maßnahmen auch in der hohen Auflösung 2560x1600 ordnungsgemäß funktionieren. Ein Abfall der Performance, wie man es beispielsweise des Öfteren auf einer GeForce 7900 GTX beobachten kann, sollte also der Vergangenheit angehören.
Abschließend wäre es, da die GeForce 8800 GTX eine Direct3D-10-Grafikkarte ist, natürlich noch möglich, auf die neue API mit dem Shader Model 4 sowie den verbesserten Fähigkeiten, Effekt-Physik zu simulieren, genauer einzugehen. Um den Umfang dieses Artikels nicht endgültig zu sprengen, wollen wir aber hier darauf verzichten und holen eine detaillierte Beschreibung in einem späteren Artikel nach.