Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden. Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Die untersuchten LLMs scheinen ein von Sprache losgelöstes Verständnis zu haben und erst im letzten Schritt eine Überführung der Struktur in eine bestimmte Sprache vorzunehmen.
Das dürfte insgesamt ein spannendes Feld sein, weil es vermutlich gar nicht so einfach ist, die genauen Prozesse bis zu dem Moment, wo sie verbalisiert werden, nachzuvollziehen und begrifflich zu fassen. "Sprache" ist ja ein zutiefst menschliches Konzept - und ob sich das so einfach auf LLM übertragen lässt? Schon mit Blick auf den Menschen wäre ja die Frage, wie unsere Gedanken tatsächlich repräsentiert sind, bevor wir sie aussprechen. Auch da muss man ja trennen, denn Denkprozesse laufen ja auch vor dem Spracherwerb ab ...
Sind die denn fix? Ich stecke längst nicht so tief in der Materie wie manch anderer hier, aber meiner Erfahrung mit ein wenig privatem ausprobieren nach, möchtest du für lokale LLMs so viel VRAM wie möglich.
Die 12GB einer RTX 3060 sind dahingehend nicht ganz so mies wie die 8GB meiner RTX 3070, trotzdem dürftest du damit relativ schnell ans Limit kommen, wenn du versuchst die etwas größeren, "smarteren" Modelle zu nutzen.
Wenn du das Ganze tatsächlich für einen produktiven Zweck einsetzen möchtest und mit etwas Blick auf die Zukunft, würde ich mal schauen ob du nicht direkt auf eine 16GB Karte gehst.
Die relativ neue RTX 5060Ti gibt es in der 16GB Variante ab ca. 450€.
@Xes Nein, nicht wirklich fix. Aber aktuell gibt meine Portokasse nicht mehr her. Evtl. schiebe ich die Investition noch etwas und versuche dann eine halbwegs zukunftsträchtige Entscheidung und Investition zu tätigen.
@Xes Nein, nicht wirklich fix. Aber aktuell gibt meine Portokasse nicht mehr her. Evtl. schiebe ich die Investition noch etwas und versuche dann eine halbwegs zukunftsträchtige Entscheidung und Investition zu tätigen.
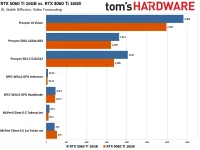
Das würde ich stark empfehlen. Du bist noch ca. 150 € von einer 5060 TI mit 16 GB VRAM entfernt, und das würde ich doch eher als gute Investition für die nächste Zeit für Deinen Zweck sehen als eine ältere GPU. Eine 4060 TI kostet fast genauso viel, und eine 3060 TI und tiefer lohnt sich für KI so nicht mehr.
40% mehr bei MLPerf Client 0.5 Tokens/sec, das ist schon beachtlich mehr.
Schon mal herzlichen Dank an alle, die sich mit Ratschlägen und Ideen beteiligt haben! Und auch vielen Dank für die interessanten, halb off-topic Gesprächsfäden!
Ich werde einen Kauf erst mal aufschieben und keinen Schnellschuss machen, sondern längerfristig planen. Bis dahin schaue ich mal, was man mit llama.cpp und UMA für die iGPU so erreichen kann.