goldmomo
Ensign
- Registriert
- Sep. 2013
- Beiträge
- 143
Hallo,
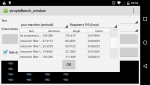
bin jetzt auch Besitzer eines RaspBerryPi 3( ), habe mir das Teil eigentlich ohne wirklichen Grund gekauft, war aber beeindruckt von der Performance die er abliefert. Benchmarks habe ich kaum gefunden, also hab ich mir gedacht schreibst mal schnell selber etwas (simple/portabel).
), habe mir das Teil eigentlich ohne wirklichen Grund gekauft, war aber beeindruckt von der Performance die er abliefert. Benchmarks habe ich kaum gefunden, also hab ich mir gedacht schreibst mal schnell selber etwas (simple/portabel).
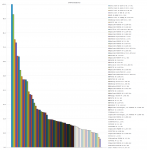
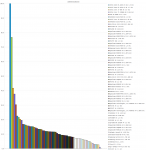
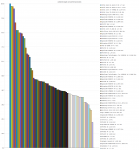
Die Ergebnisse (Singlcore CPU/MEM lastig Tests) haben mich überrascht, hätte nicht gedacht, das ein einfaches nicht Superskalares-inorder-design so gut gegen x86 CPUs aussieht (von der Caches + Memoryspeed gar nicht zu sprechen).
Besonders wenn man die Resultate Taktnormiert anschaut (gut ist wieder Designsache aber trotzdem interessant).
Meine Tests sind sicherlich etwas fern der Realität, aber vielleicht interessierst jemanden ( )
)
Compiler war unter Linux gcc, bei x86 Windows mit MSVC14 (liefert etwas schlechtere Ergebnisse als gcc unter Linux .. besonders bei der AMD-CPU).
bin jetzt auch Besitzer eines RaspBerryPi 3(
Die Ergebnisse (Singlcore CPU/MEM lastig Tests) haben mich überrascht, hätte nicht gedacht, das ein einfaches nicht Superskalares-inorder-design so gut gegen x86 CPUs aussieht (von der Caches + Memoryspeed gar nicht zu sprechen).
Besonders wenn man die Resultate Taktnormiert anschaut (gut ist wieder Designsache aber trotzdem interessant).
Meine Tests sind sicherlich etwas fern der Realität, aber vielleicht interessierst jemanden (
Compiler war unter Linux gcc, bei x86 Windows mit MSVC14 (liefert etwas schlechtere Ergebnisse als gcc unter Linux .. besonders bei der AMD-CPU).