Hallo,
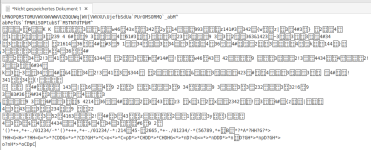
ich habe nachstehendes PDF-Dokument erhalten. Beim Anbieter, von dem ich es erhalten habe, kann der Text ganz hormal kopiert bzw. durchsucht werden. Ich habe aber eine Ausfertigung vorliegen, bei der der Text zwar markiert und kopiert werden kann. Beim Einfügen sind aber nur "Sonderzeichen" zu sehen. Der Text im PDF kann auch nicht durchsucht werden.
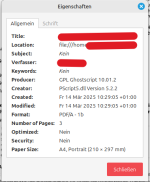
Meine Frage: Gibt es ein Programm, mit dem dieses letztendlich nicht kopierbare Dokument erzeugt wurde?
Danke.
ich habe nachstehendes PDF-Dokument erhalten. Beim Anbieter, von dem ich es erhalten habe, kann der Text ganz hormal kopiert bzw. durchsucht werden. Ich habe aber eine Ausfertigung vorliegen, bei der der Text zwar markiert und kopiert werden kann. Beim Einfügen sind aber nur "Sonderzeichen" zu sehen. Der Text im PDF kann auch nicht durchsucht werden.
Meine Frage: Gibt es ein Programm, mit dem dieses letztendlich nicht kopierbare Dokument erzeugt wurde?
Danke.