ATi Radeon HD 5870 im Test: Die erste Grafikkarte mit DirectX 11
3/29Technik im Detail Part 1
Mit der RV870-Architektur, die intern unter dem Namen „Cypress“ läuft, hat ATi nach einer über ein Jahr andauernden Wartepause wieder größere Änderungen an der Architektur vorgenommen. Das Rad hat der Chipspezialist mit der GPU allerdings nicht neu erfunden, denn der RV870 basiert zu einem Großteil auf dem RV770 und bietet primär nur eine höhere Anzahl Einheiten.
Als Fertigungsprozess muss die neue 40-nm-Technologie von TSMC herhalten, die laut ATi gut funktioniert soll. Die Anzahl der Schaltungen ist auf dem RV870, der sowohl auf der Radeon HD 5850 als auch auf der Radeon HD 5870 eingesetzt wird, massiv gestiegen: satte 2,15 Milliarden Transistoren sind es geworden, was mehr als eine Verdoppelung zum Vorgänger, der aus 956 Millionen Transistoren aufgebaut ist, darstellt.
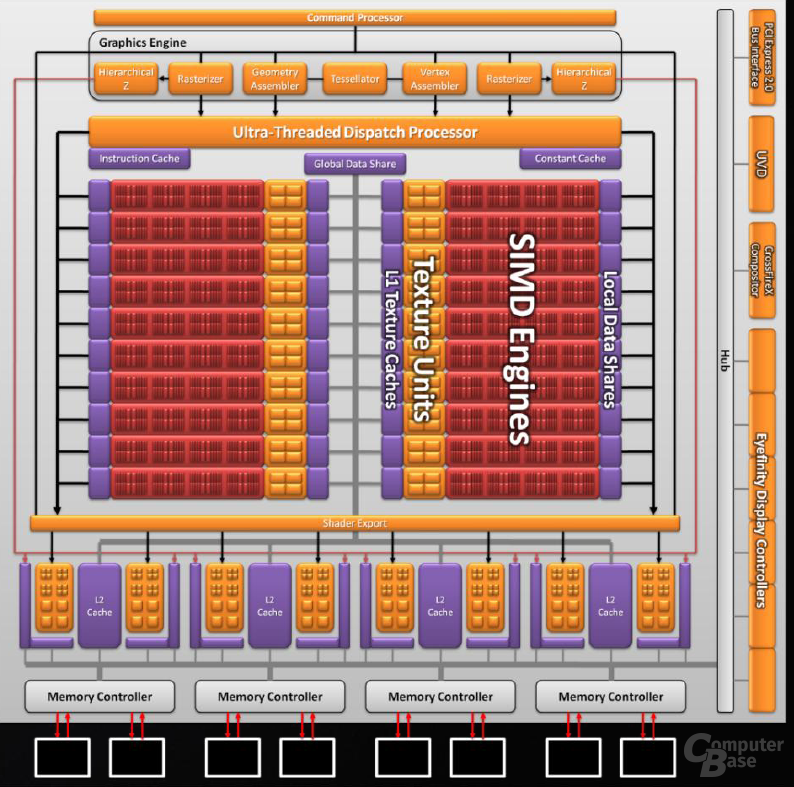
Die Größe des Dies ist ebenfalls angestiegen. Der RV870 ist trotz des 40-nm-Prozesses 334 mm² groß, der RV770 dagegen misst nur 263 mm². Die über zwei Milliarden Transistoren setzen sich primär aus 320 5D-Shadereinheiten, 80 Textureinheiten sowie 32 ROPs zusammen, womit ATi mehr oder weniger jede wichtige Schaltung in dem Rechenkern verdoppelt hat. Nicht vergessen darf man die Unterstützung der neuen DirectX-11-API, die die Kanadier sicherlich nicht kostenlos implementieren konnten. Der Unified Video Decoder wurde dagegen unverändert in der zweiten Generation belassen. Schauen wir uns den RV870 noch etwas genauer im Detail an.
Stream-Processing-Units (SPU):
Mit die wichtigsten Änderungen sind in den Shadereinheiten vorzufinden, die nun mit der DirectX-11-API umgehen können. Der RV870 verfügt über 320 5D-Shadereinheiten, die rein von der Architektur mehr oder weniger identisch zu denen des Vorgängers sind. Anstatt zehn SIMD-Einheiten gibt es nun schlicht und ergreifend 20, die weiterhin aus 16 gleichen Shaderkernen bestehen, die wiederum fünf ALUs fassen.
Alle fünf ALUs können jeweils ein MADD (Multiply-ADD) ausführen, wobei eine der ALUs genauso als „Special Function Unit“ agieren kann, um Spezialberechnungen wie zum Beispiel Sinus oder Cosinus auszuführen. Diese ALU ist in dem Fall dann nicht als normale ALU zu verwenden. Die einzelnen ALUs können als skalare Einheiten angesehen werden, während die Architektur als Ganzes, im Gegensatz zu der von Nvidia, nicht skalar aufgebaut ist, sondern weiterhin als Vektor-Einheit mit fünf einzelnen Komponenten (RGBA, Rot Grün, Blau, dem Alphawert und noch einem einzelnen Skalar) zu sehen ist.
Zwar kann jeder Shaderkern die 5D-Einheiten in 1D+1D+1D+1D+1D aufteilen, womit es sich prinzipiell um Vektoreinheiten handelt, die wie Scalar-Units agieren, dafür müssen die Berechnungen aber komplett unabhängig voneinander sein. Sind diese dagegen abhängig, können längst nicht immer alle ALUs ausgelastet werden und ein Leerlauf entsteht. Darüber hinaus gibt es in einem Shaderkern eine Branch-Execution-Einheit, die Sprungbefehle wie „if“ oder „when“ ohne Blockierung der ALUs durchführen kann. Ein Shaderkern im RV870 setzt sich nicht nur aus den bis jetzt genannten Einheiten zusammen. Es kommt noch ein „General Purpose Register“, also ein kleiner Zwischenspeicher, hinzu, der beim GPU-Computing hilfreich ist.
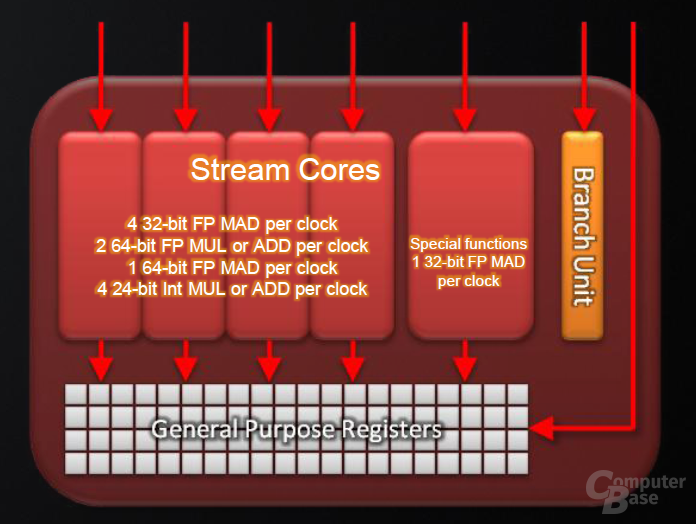
ATi hat die IPC (Instructions per Clock) beim RV870 angeblich verbessern können. Die theoretische Rechenleistung der Radeon HD 5870 beträgt satte 2,72 TFLOPS bei normaler Single-Precision. Die Double-Precision-Leistung (64 Bit, nach IEEE754-2008) liegt bei 544 GFLOPS. Die 64-Bit-Genauigkeit wird weiterhin durch das Zusammenschalten der vier gewöhnlichen ALUs pro Shaderkern erledigt, was die DP-Leistung fünftelt. Dedizierte Einheiten gibt es nicht.
Auch für ATi nimmt die Bedeutung des GPU-Computings zu, weshalb auch der „Local Data Share“ in der Kapazität verdoppelt wurde. Dieser ist nun nicht mehr 16 KB sondern 32 KB groß und findet seinen Platz an jeder SIMD-Einheit. In diesem Speicher werden Ergebnisse gespeichert, auf die dann später ohne neue Berechnungen wieder zugegriffen werden können. Jede SIMD-Einheit hat einen 8 KB großen L1-Cache. Zudem gesellt sich noch ein 64 KB „Global Data Share“ hinzu, in dem Rechenergebnisse gespeichert werden, auf die daraufhin jede SIMD zugreifen kann. Zu guter Letzt existieren im RV870 vier 128 KB große L2-Caches.
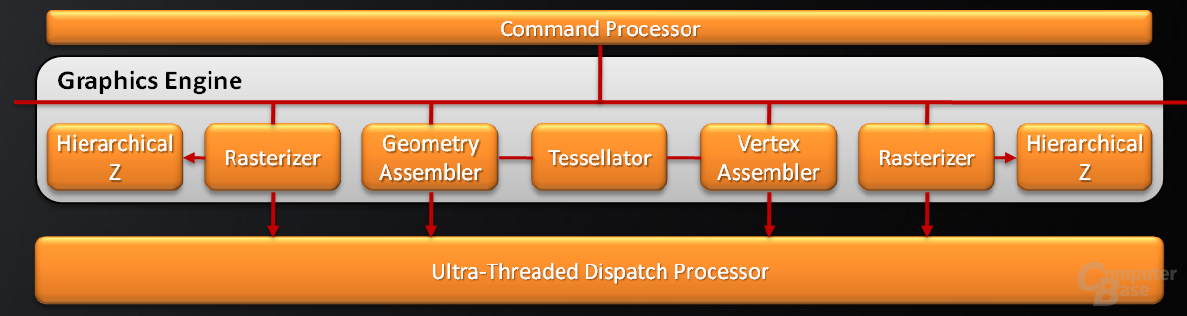
Mit Daten versorgt werden die 320 5D-Shadereinheiten (wie von ATi gewohnt) durch den so genannten „Ultra-Threaded Dispatch Processor“, dessen Hauptaufgabe darin besteht, keine „Blasen“ (also nicht genutzte Rechenkapazitäten) in den 5D-Shadereinheiten entstehen zu lassen. Dieser wiederum wird durch Daten von der „Gaphics Engine“ versorgt, die aus gleich zwei Hierarchial-Z-Einheiten (Tiefentests für Sichtbarkeitsprüfungen) sowie zwei Rasterizern besteht. Von beiden gab es vorher jeweils nur eine Einheit, womit ATi Engpässe in der Datenversorgung der Shadereinheiten umgehen möchte. Die Graphics Engine beinhaltet zudem den Tessellator und die dazu gehörigen Hull- sowie Domain-Shader.
Textureinheiten:
Ebenso verdoppelt im RV870 haben sich die Textureinheiten, von denen es nun 80 gibt. Dies ist nur logisch, da ATi die Anordnung der Texture Mapping Units, kurz TMUs, gleich gelassen hat. Somit gibt es pro SIMD einen Textur-Cluster, der sich aus vier TMUs zusammen setzt. An die Textureinheiten ist der L1-Cache angeschlossen. Die TMUs können pro Takt 80 Pixel bilinear sowohl filtern als auch texturieren, womit es 68 Milliarden bilinear gefilterte Texel pro Sekunde gibt.
Die Fähigkeiten der TMUs musste ATi allerdings modifizieren, um die Spezifikationen von DirectX 11 zu erreichen. In Folge dessen können die TMUs nun eine maximale Texturauflösung von 16k x 16k darstellen (vorher 8k) und es gibt einen neuen Kompressionsmodus. Dieser hört auf den Namen „Block Compression Modes“ (BC6/7) und gilt für die 32-Bit- sowie 64-Bit-HDR-Darstellung. Zusätzlich wurde die anisotrope Filterung in den Textureinheiten verbessert.
Raster Operation Processor (ROP):
Die Shader- und die Textureinheiten sind also verdoppelt worden, für die Raster Operation Processors (ROPs) gilt dasselbe. Auf dem RV870 sind 32 solcher ROPs verbaut, die leicht gegenüber dem Vorgänger modifiziert worden sind. Anstatt eines ROP-Clusters pro Speichercontroller sind auf dem RV870 zwei ROP-Cluster vorhanden, die von einem 128 KB L2-Cache umgeben sind. Pro ROP gibt es weiterhin vier Z/Stencil-Einheiten, insgesamt also deren 128.
An den normalen MSAA-Fähigkeiten hat ATi pro ROP keine Änderungen vorgenommen, womit 4xMSAA weiterhin innerhalb eines Taktzyklus' berechnet werden kann (insgesamt also 32 Pixel), 8xMSAA aber weiterhin zwei Takte benötigt. Es ist dabei gleichgültig, ob ein Pixel mit einer 32-Bit- oder einer 64-Bit-Genauigkeit bearbeitet werden soll. Darüber hinaus hat ATi angeblich die Performance des Custom-Filter-AA (CFAA) in die Höhe schrauben können.