AlphaStar: Künstliche Intelligenz besiegt StarCraft-II-Profi MaNa
Das zu Google gehörende Unternehmen DeepMind hat unter dem Namen AlphaStar eine künstliche Intelligenz für Blizzards Echtzeit-Strategiespiel StarCraft II vorgestellt. In einer Reihe von Spielen gegen den Profi-Spieler MaNa konnte die KI fünf von fünf Spielen für sich entscheiden.
Schwierigkeiten einer StarCraft-II-KI
Eine künstliche Intelligenz für StarCraft II stößt generell auf mehrere Probleme. Dazu gehört unter anderem, dass es keine generell beste Strategie gibt, sondern viele unterschiedliche Aktionen zu ähnlichen Ergebnissen führen können. Zum anderen kann die hohe Spiellänge dafür sorgen, dass Entscheidungen, die zu Beginn des Spiels gut wirken, sich am Ende des Spiels negativ auswirken. Für die Rechenkapazität entscheidend ist zudem, dass das Spiel nicht rundenbasiert ist, sondern in Echtzeit abläuft und hunderte Einheiten und Gebäude gleichzeitig gesteuert werden müssen.
Netz-Architektur von AlphaStar
DeepMind hat für AlphaStar ein komplexes neuronales Netz entwickelt. Die genaue Netz-Architektur ist zum jetzigen Zeitpunkt noch nicht bekannt, soll aber später in einem wissenschaftlichen Papier offengelegt werden. Bekannt ist, dass AlphaStar sowohl auf ein tiefes rekurrentes neuronales Netz in Form eines Long-Short-Term-Memory-Teils (LSTM (PDF)) als auch auf einen Transformer (PDF) setzt. Ein LSTM ermöglicht es, Sequenzen von Eingaben zu betrachten, umgangssprachlich verfügt das neuronale Netz über ein Gedächtnis und kann so Ausgaben von früheren Eingaben abhängig machen. Ein Transformer ist ein Sequence-to-Sequence-Modell, das Eingabe- in Ausgabe-Sequenzen überführt, im Gegensatz zu klassischen Ansätzen aber komplett auf rekurrente Bestandteile verzichtet. Das ermöglicht unter anderem ein deutlich schnelleres Training: Rekurrente neuronale Netze müssen für das Training aufgerollt werden, so entstehen bei langen Sequenzen sehr tiefe Netze; der Transformer umgeht dieses Problem.
Verschiedene Strategien im Trainingsverlauf
Für das Training der KI hat DeepMind das Netz zuerst über Supervised Learning auf von Blizzard veröffentlichten anonymisierten Spielen normaler Menschen trainiert. Die so erzeugten Modelle wurden mittels Reinforcement Learning weiter verfeinert. DeepMind erzeugte dabei dynamisch neue Gegner durch Training der bestehenden Modelle gegeneinander. So entwickelten sich im Laufe des Trainings verschiedene Spielstrategien. Ausgehend von anfänglichen Strategien, wie zum Beispiel möglichst viele Photonenkanonen oder Dunkle Templer zu bauen und diese zur gegnerischen Basis zu senden, entwickelten sich ausgefeiltere Strategien wie ökonomische Stärke durch mehr Arbeiter zu gewinnen oder die Wirtschaft des Gegners gezielt durch zwei Oracles zu stören.
-
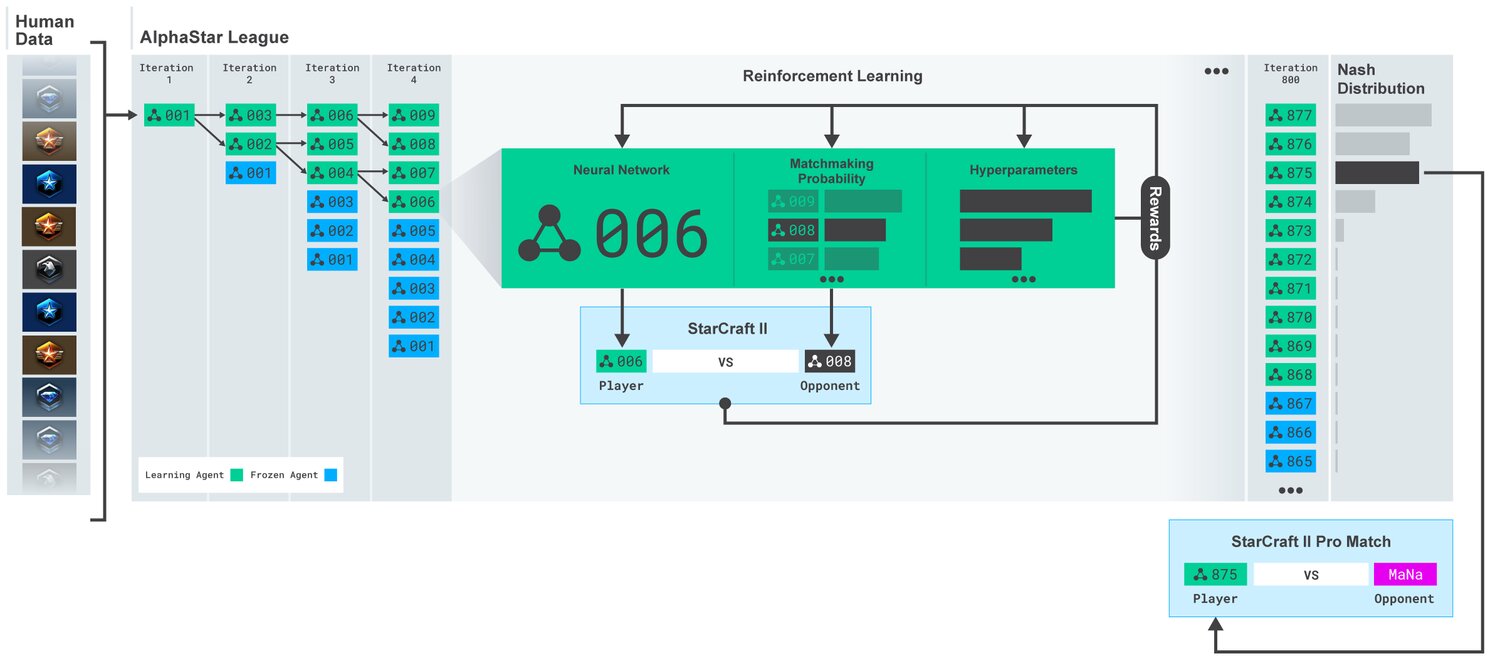 AlphaStar: Trainingsprozess (Bild: DeepMind)
AlphaStar: Trainingsprozess (Bild: DeepMind)
Für das Training hat DeepMind einen enormen Rechenaufwand betrieben: Bis zu 200 Jahre In-Game-Spielzeit in 14 Tagen Training wurden auf eine KI verwendet. Dabei standen jeweils 16 von Googles auf Deep Learning spezialisierten TPUs pro KI zur Verfügung. Die KIs wurden ausschließlich auf 1-vs-1-Spielen, in denen beide Spieler die Rasse Protoss auf der Karte „CatalystLE“ spielen, trainiert.
Weniger Aktionen pro Minute (ApM) als Profis
Gegenüber den beiden Profi-Spielern MaNa und TLO machte die final gewählte KI mit 277 ApM zu 390 ApM (MaNa) oder 678 ApM (TLO) im Durchschnitt deutlich weniger Aktionen pro Minute – obwohl sie aufgrund fehlender physischer Eingabebeschränkungen jede Einheit einzeln steuern könnte und unbegrenzt viele ApM ausführen könnte. Die von der KI gewählten Aktionen waren dafür laut DeepMind vermutlich deutlich genauer als die der menschlichen Spieler. Zudem lagen im Schnitt 350 ms zwischen der Beobachtung einer Aktion und einer entsprechenden Reaktion der KI. DeepMind schließt daraus, dass die Überlegenheit der KI nicht durch schnellere Reaktionszeiten folgt.
AlphaStar takes well-known strategies and turns them on their head. The agent demonstrated strategies I hadn’t thought of before, which means there may still be new ways of playing the game that we haven’t fully explored yet.
TLO
Beide Profis wurden Fünf-Null geschlagen, solange die KI auf maximaler Zoomstufe spielte und trainiert wurde – also die gesamte Karte sehen konnte, ohne die Kamera bewegen zu müssen. Eine zweite KI, die für lediglich sieben Tage trainiert wurde und die Kamera selbst bewegen musste, konnte von MaNa geschlagen werden.
Die von DeepMind für AlphaStar verwendeten Techniken sind prinzipiell auch für andere Anwendungsgebiete interessant. Probleme mit Eingaben von Sequenzdaten sind Wettervorhersagen oder finden sich in der Verarbeitung natürlicher Sprachen, bei der beispielsweise Sequenzen von Buchstaben, Wörtern oder Sätzen (indirekt) als Eingabe dienen.