Google Gboard: Spracherkennung in Zukunft offline statt online
Google hat ein künstliches neuronales Netz entwickelt, das in Zukunft für die in die Android-Tastatur Gboard eingebaute Spracherkennung zuständig sein soll. Damit verlagert sich die Verarbeitung der Sprache von Servern zu den Endgeräten. Vorerst funktioniert das aber nur auf Pixel-Smartphones mit amerikanischem Englisch.
Das von Google entwickelte neuronale Netz nimmt als Eingabe ein Audiosignal entgegen und generiert daraus Vorhersagen auf Zeichen-Ebene. Damit ähnelt das Modell der Eingabe durch einen Menschen in dem Sinne, dass Wörter nicht komplett, sondern Zeichen für Zeichen generiert werden. Neben dieser Unterscheidung zu klassischen Ansätzen, in denen die Verarbeitung in mehreren Schritten erfolgte und ganze Wörter generiert wurden, ermöglicht das neuronale Netz die Verarbeitung der Eingabe als Stream. Demnach kann das Modell Eingaben verarbeiten, ohne dass bereits das komplette Audiosignal vorliegt.
Rekurrentes neuronales Netz als Architektur
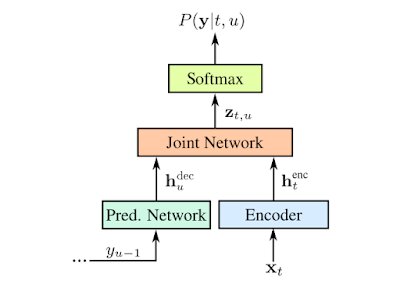
Als Architektur verwendet Google dafür ein RNN-T (Rekurrentes-Neuronales-Netz-Transducer; Paper (PDF)). Dieses ist aus mehreren Bestandteilen aufgebaut: Der Encoder besteht aus acht LSTM-Schichten mit jeweils 2.048 Einheiten und generiert aus der Eingabe xt zu einem Zeitpunkt t einen Vektor htenc. Das Prediction-Network, welches aus zwei LSTM-Schichten je 2.048 Einheiten besteht, nimmt die vorherige Ausgabe yu-1 als Eingabe entgegen und generiert daraus den Vektor hudec. Aus diesen beiden Vektoren wird über einen weiteren Zwischenschritt die Ausgabe yu, abhängig von allen vorherigen Vorhersagen und Eingaben, berechnet.
Speichervorteil entscheidend
Entscheidend für den Einsatz des neuronalen Netzes auf Android-Endgeräten ist der belegte Speicherplatz. Der bisherige Ansatz bestand aus einem Suchgraphen, dessen Kanten die Wahrscheinlichkeiten der Übergänge abbildeten und der nach dem Pfad mit der höchsten Wahrscheinlichkeit durchsucht werden musste. Dieser Graph ist laut Google typischerweise 2 GB groß und damit zu groß, um ihn auf jedem Smartphone oder Tablet vorzuhalten. Aus diesem Grund befindet sich der Graph auf einem Google-Server, der entsprechende Anfragen verarbeitet.
Das entwickelte neuronale Netz kommt nach Komprimierung auf rund 80 MB. Demnach ist es klein genug, um auf jedem Endgerät gespeichert zu werden; die Spracherkennung kann somit offline und direkt auf dem Gerät durchgeführt werden. Die Geschwindigkeit ist dabei laut Google ausreichend, um Sprache schneller als in Echtzeit „auf einem Single-Core“ auszuführen. Google plant neben dem Modell für amerikanisches Englisch, in Zukunft weitere Modelle für andere Sprachen und andere Endgeräte als die Pixel-Smartphones auszuliefern.
