
AMD Ryzen 5000 im Test: AMD Ryzen 5000 mit Zen 3 kurz erklärt
2/8Bevor es an die Benchmarks und Analysen geht, soll AMDs neue Zen-3-Architektur noch kurz umrissen werden. Wesentliche Details wie den neuen CCX-Komplex und die unveränderte Fertigung hatte der Hersteller schon zur Vorstellung genannt, ein paar interessante Aspekte zu Neuerungen in den Kernen und auch den Chiplets aber noch außen vor gelassen.

Ein vollständiges Redesign
AMD nennt Zen 3 ein „vollständiges Redesign“ und stichelt vor diesem Hintergrund gegen Intels über Jahre von Core i-6000 bis Core i-10000 nur leicht angepasstes Skylake-Design. „Man kann nicht das Gleiche unzählige Male hervor holen“, heißt es seitens AMD. Dabei sieht Zen 3 auf den ersten Blick so aus wie Zen 2 und nutzt auch dieselbe Fertigung. Doch der Eindruck, dass sich nichts getan hat, täuscht – und zwar gewaltig.
Es hat gravierende Anpassungen gegeben, aber nicht an jeder Stelle. Das seit Zen 2 verfolgte I/O-Chiplet-Design mache so etwas möglich, erklärt AMD. Infinity Fabric, Speichercontroller und Co brauchen kein ständiges Update und skalieren nicht sehr gut mit einem kleineren Fertigungsprozess. Die Auslagerung in einen separaten Die ermöglichte es AMD, den Fokus auf die wichtigen Bereiche zu legen und den CPU-Die zu überarbeiten. Dabei wurde aber der Bereich nicht komplett vergessen, wie ein Patent, dass die Verbesserung der Latenzen zwischen den Chiplets beschreibt, zeigt.
Alter I/O-Die, neue Chiplets
Auch beim Blick unter den Heatspreader ist damit vieles beim Alten geblieben: Die beiden neuen Topmodelle Ryzen 9 5950X und Ryzen 5900X setzen auf zwei kleine CPU-Dies aus TSMCs 7-nm-Fertigung und den 125 mm² großen I/O-Die in 12 nm von Globalfoundries, die beiden kleinen Modelle wie bei Ryzen 3000 nur auf einen CPU-Die.
Der Vergleich mit dem Vorgänger zeigt, dass der CPU-Die etwas größer geworden ist und rund 250 Millionen zusätzliche Transistoren enthält. Der I/O-Die ist hingegen derselbe geblieben.
| CPU-Die („Chiplet“) | Aufbau | Transistoren | Größe |
|---|---|---|---|
| Zen 2 | 8 Kerne in zwei CCX, 32 MB L3 (16 pro CCX) | 3,90 Mrd. (TSMC N7) | 74 mm² |
| Zen 3 | 8 Kerne in einem CCX, 32 MB L3 | 4,15 Mrd. (TSMC N7) | 81 mm² |
Der neue Acht-Kern-Komplex (Zen-3-CCX)
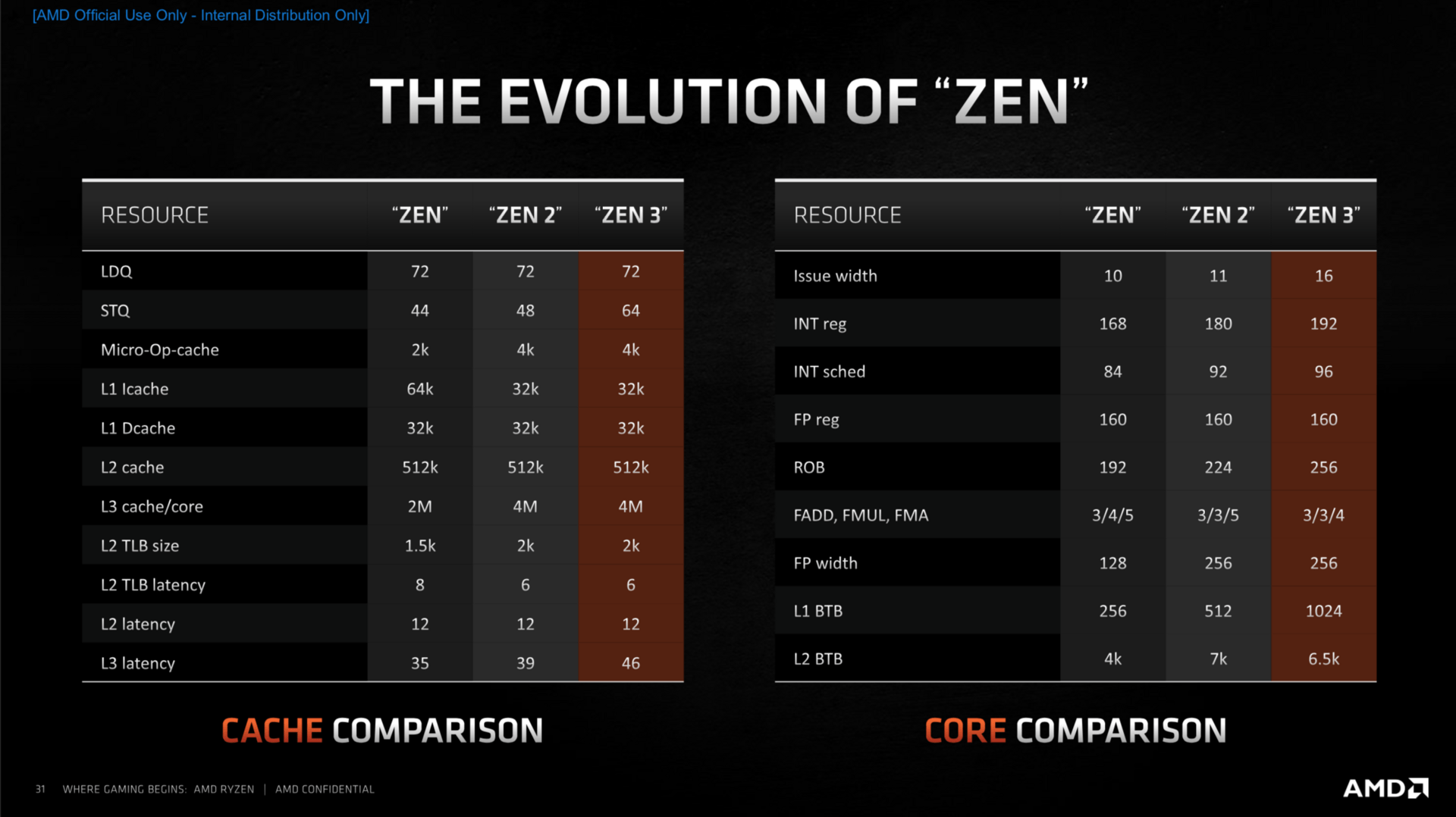
Das etwas größere Chiplet hat es dann in sich. Statt bisher zwei Mal vier Kerne getrennt voneinander zu beherbergen, sind es bei Zen 3 acht zusammenhängende Kerne. Damit ist ein CCX nun quasi ein CCD: ein monolithischer Acht-Kern-Prozessor. Das ist am Ende in der Tat der markanteste Unterschied zu allen Vorgängern, der weitreichende Folgen mit sich bringt.
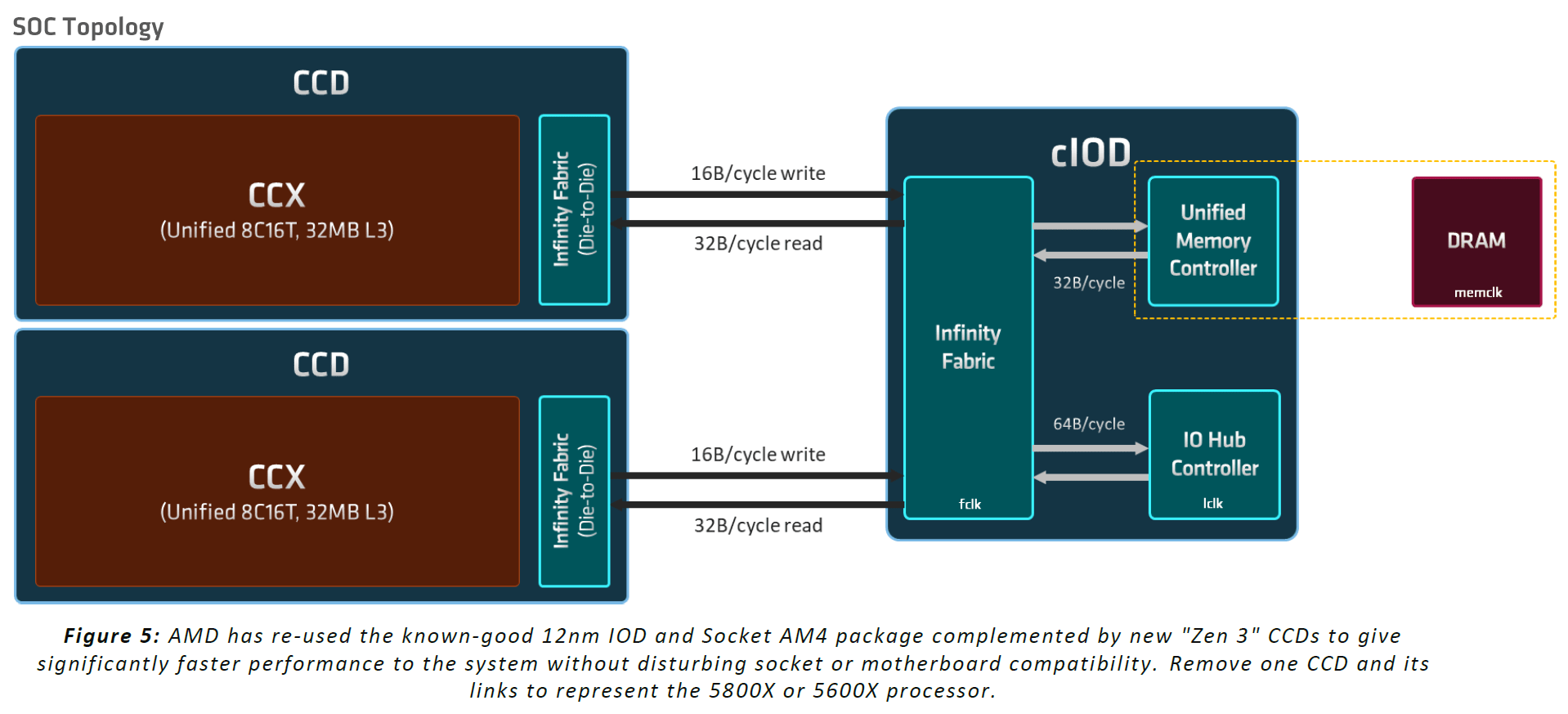
Eine betrifft den L3-Cache: Er ist pro Chiplet zwar weiterhin 32 MB groß, aber alle Kerne können jetzt direkt darauf zugreifen. Die Zeit für den einzelnen Zugriff von einem Kern auf den pro Kern jetzt viel größeren L3-Cache mit seinen insgesamt 8 Sub-Slices geht damit zwar um sieben Cycles nach oben. Doch zuvor musste ein Kern häufig den Umweg über das Fabric in Kauf nehmen, was die Latenz deutlich erhöhte. Acht Kerne, erklärte der Chefarchitekt, sei dabei der richtige Trade-off zwischen Kernen und Cache und den Latenzen. Noch mehr Kerne pro Die würde das Gleichgewicht laut AMD negativ verschieben. Mit dieser Aussage dürfte klar sein, wie AMDs Server-Prozessoren in Zukunft aussehen werden: exakt so.
-
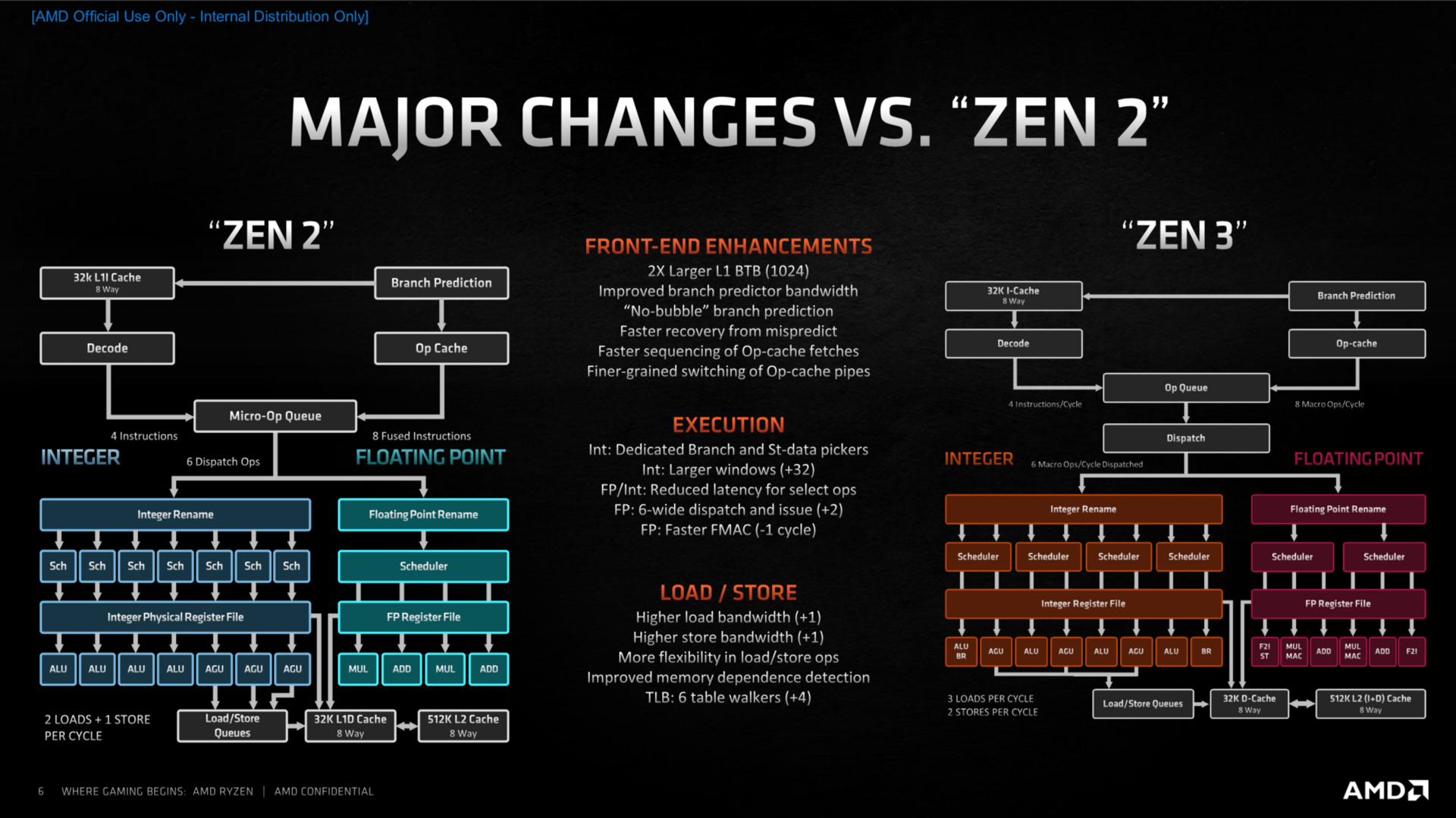
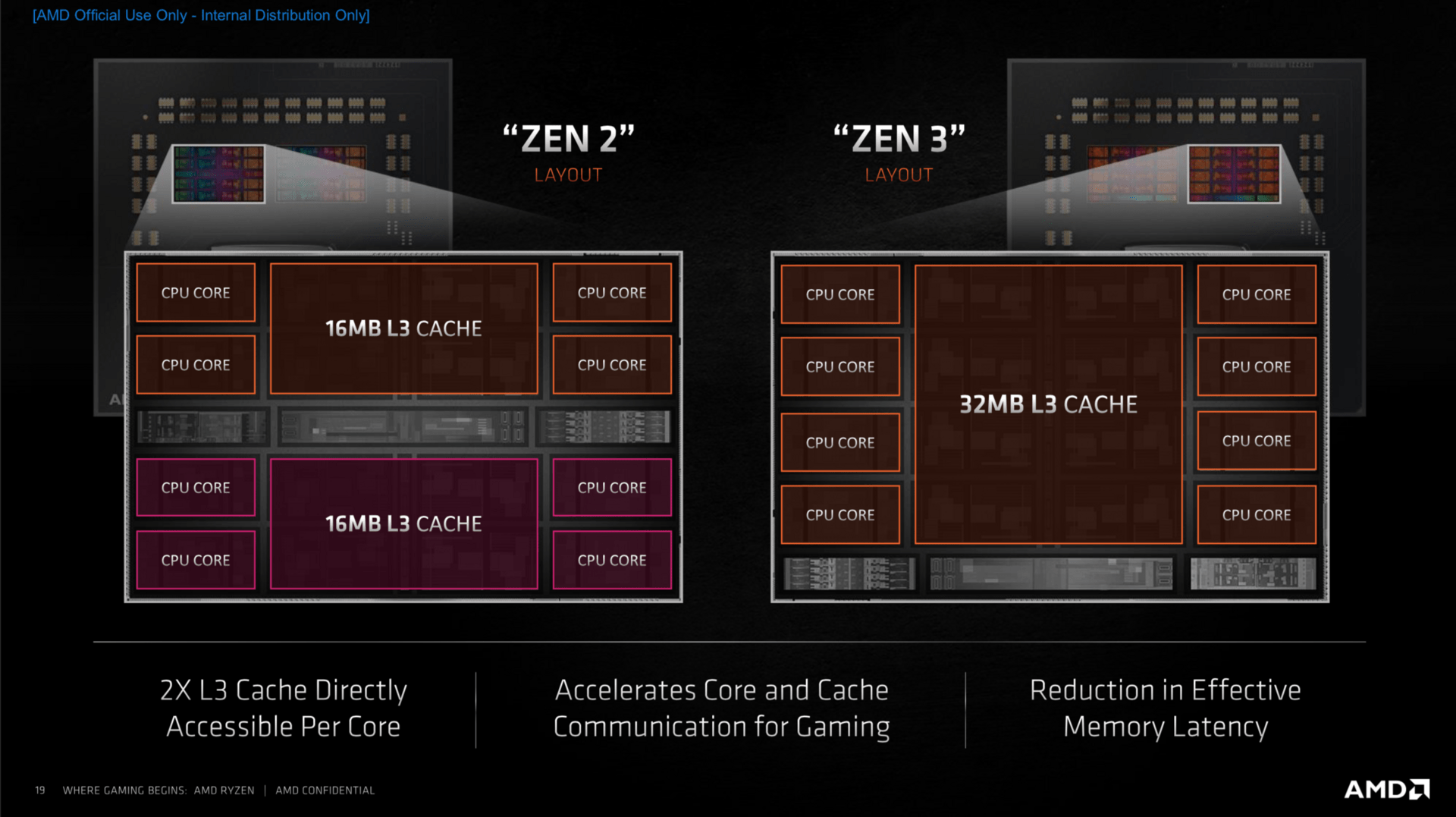 Zen-3-Architektur: Unterschied zu Zen 2 im Aufbau (Bild: AMD)
Zen-3-Architektur: Unterschied zu Zen 2 im Aufbau (Bild: AMD)
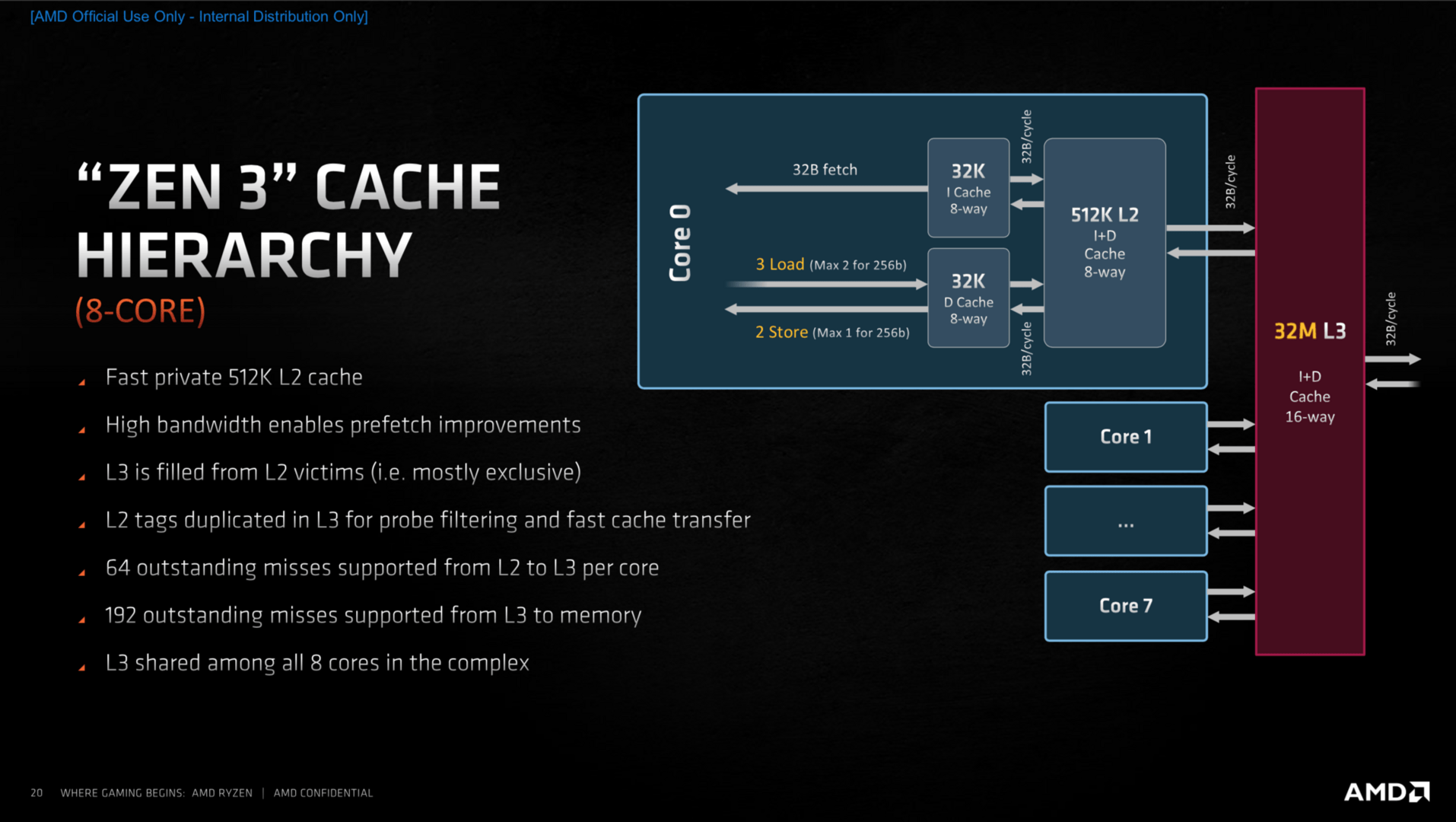
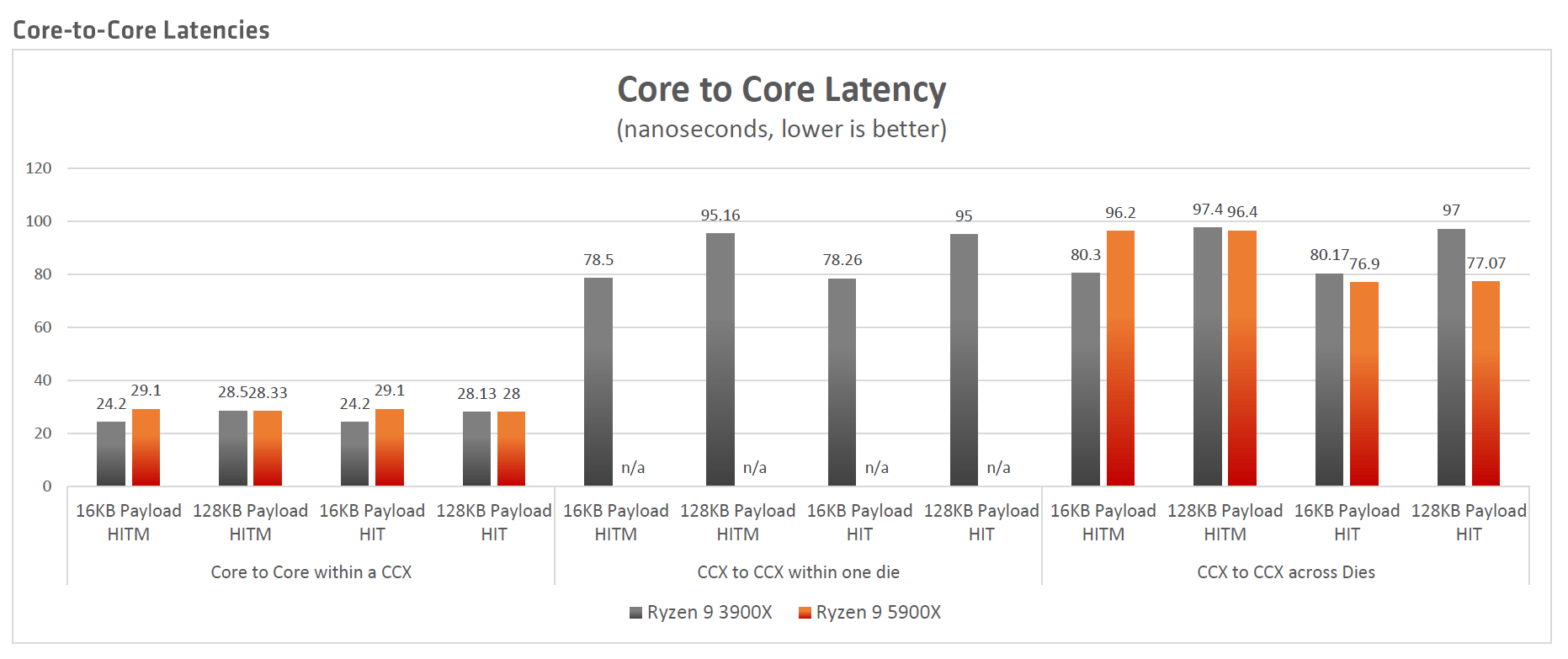
Damit das neue Konzept auch aufgeht, wurde die Zusammenarbeit mit Microsoft zuletzt weiter vorangetrieben. Das Ziel: Sicherzustellen, dass vom Scheduler Anfragen zunächst in einem Acht-Kern-Komplex bleiben und nicht über den Fabric zum andern CCD im anderen Chiplet springen, sofern dieser vorhanden ist. Dies hätte weiterhin negative Auswirkungen, wie AMD an dem Latenz-Diagramm aufzeigt.
Viel Optimierung auf Kern-Ebene
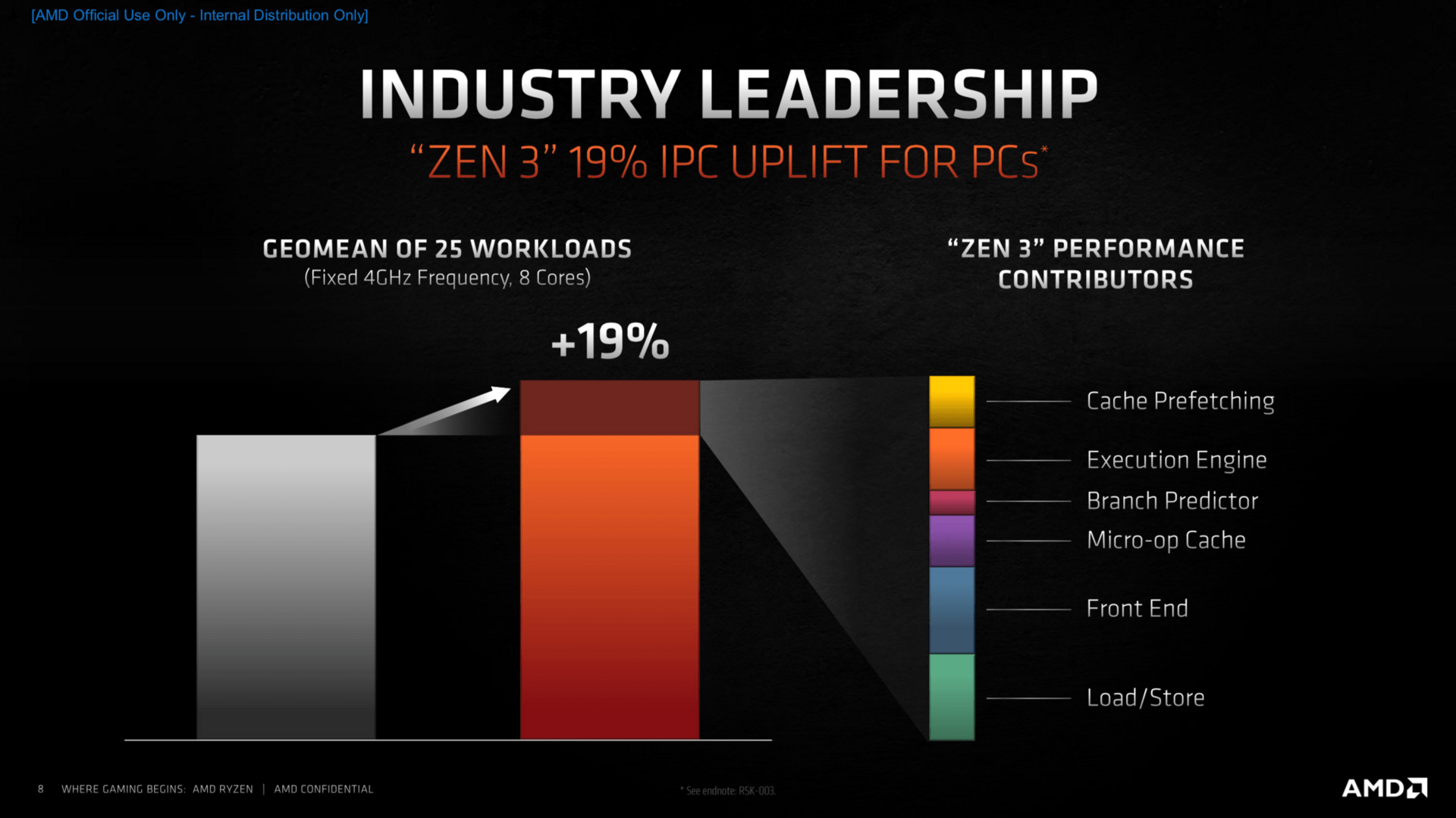
Große Überarbeitungen innerhalb der Kerne gab es im Bereich des Front Ends, zu dem die Sprungvorhersage und der Micro-op-Cache gehören, aber auch die Load- und Store-Einheiten wurden angepasst. Abschließend leisten auch die Ausführungseinheiten noch etwas mehr als bisher, sodass am Ende abermals ein Plus von 19 Prozent IPC (Instructions per Clock; Befehle pro Takt) gegenüber Zen 2 auf dem Papier stehen soll.
-
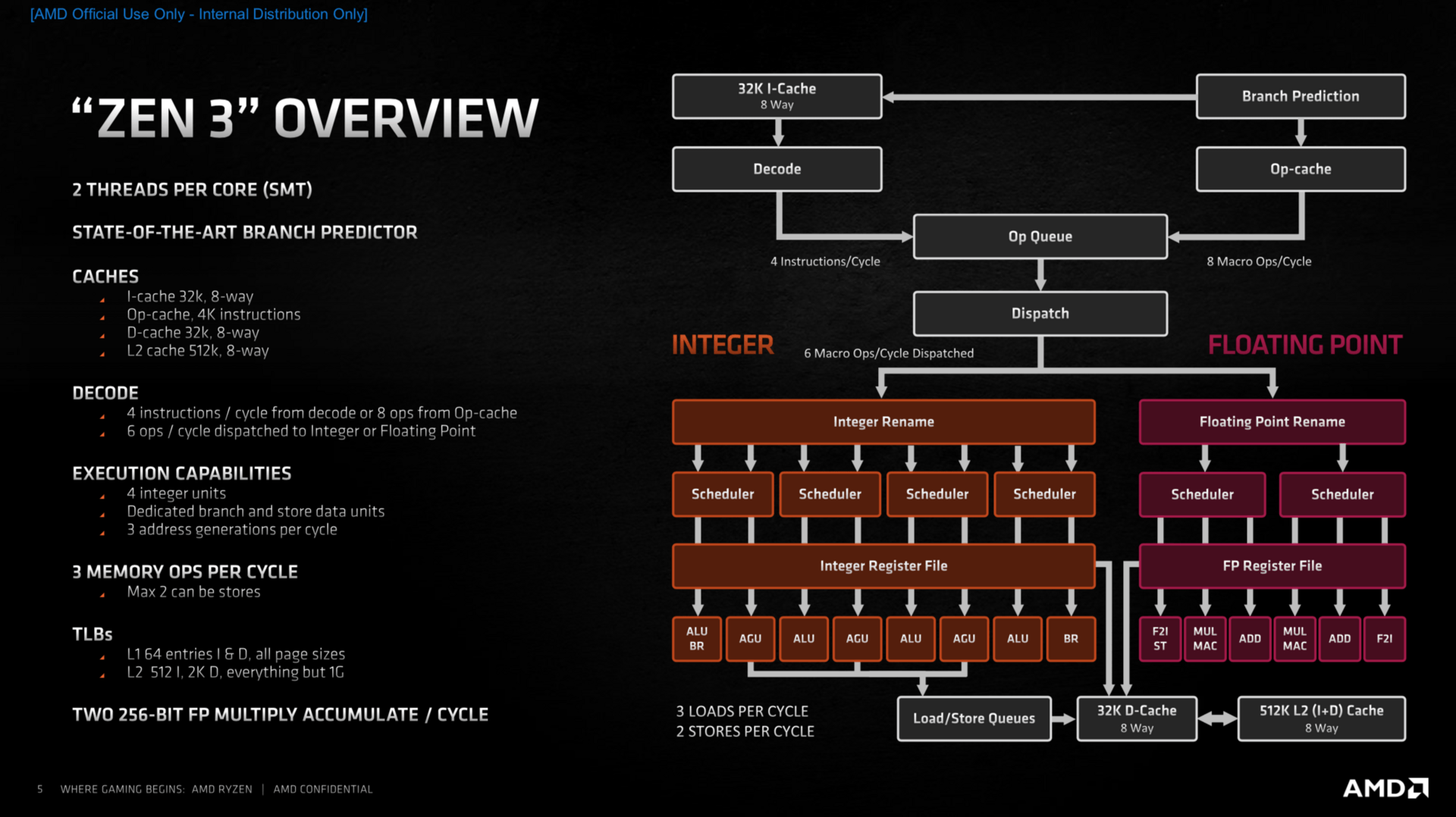 Zen-3-Architektur: Überblick (Bild: AMD)
Zen-3-Architektur: Überblick (Bild: AMD)

Sprungvorhersage und Micro-op-Cache
Ausgangspunkt der Optimierungen im Kern war die Sprungvorhersage. Dort hatte AMD mit Zen 2 erstmals die „TAGE“-Sprungvorhersage-Technologie genutzt, jetzt kommt das Feature „Zero Bubble“ in größerem Umfang hinzu. Zen 2 hatte es bereits im L0-BTB genutzt, es erlaubt mit geringer Latenz genaue Ergebnisse bei der Vorhersage. Größere Puffer in allen Bereichen, aber auch eine reduzierte Reaktionszeit, falls eine Vorhersage mal komplett daneben geht und alles zurück auf Anfang fährt, wurden umgesetzt. Viel mehr Bandbreite steht dem Bereich nun zur Verfügung, was laut AMD nicht der Genauigkeit dient, die sich zwar etwas aber nur minimal verbessert hat, sondern dem Wegschaffen der Instruktionen in die Pipeline für die nächsten Arbeitsschritte.
Ebenfalls im Fokus stand der Micro-op-Cache, bei dem AMD noch hohes Optimierungs- und damit Leistungspotenzial sah. Der Standard-Decoder kann nur vier Instruktionen per Cycle liefern, gab es eine Instruktion bereits einmal, wird sie in einem Micro-Op-Cache zwischengespeichert. Wenn diese dann noch einmal benötigt wird, kann sie nun aus dem Op-Cache abgerufen werden, im Idealfall liefert dieser bis zu acht sogenannte Macro-Ops an die Verteilzentrale.
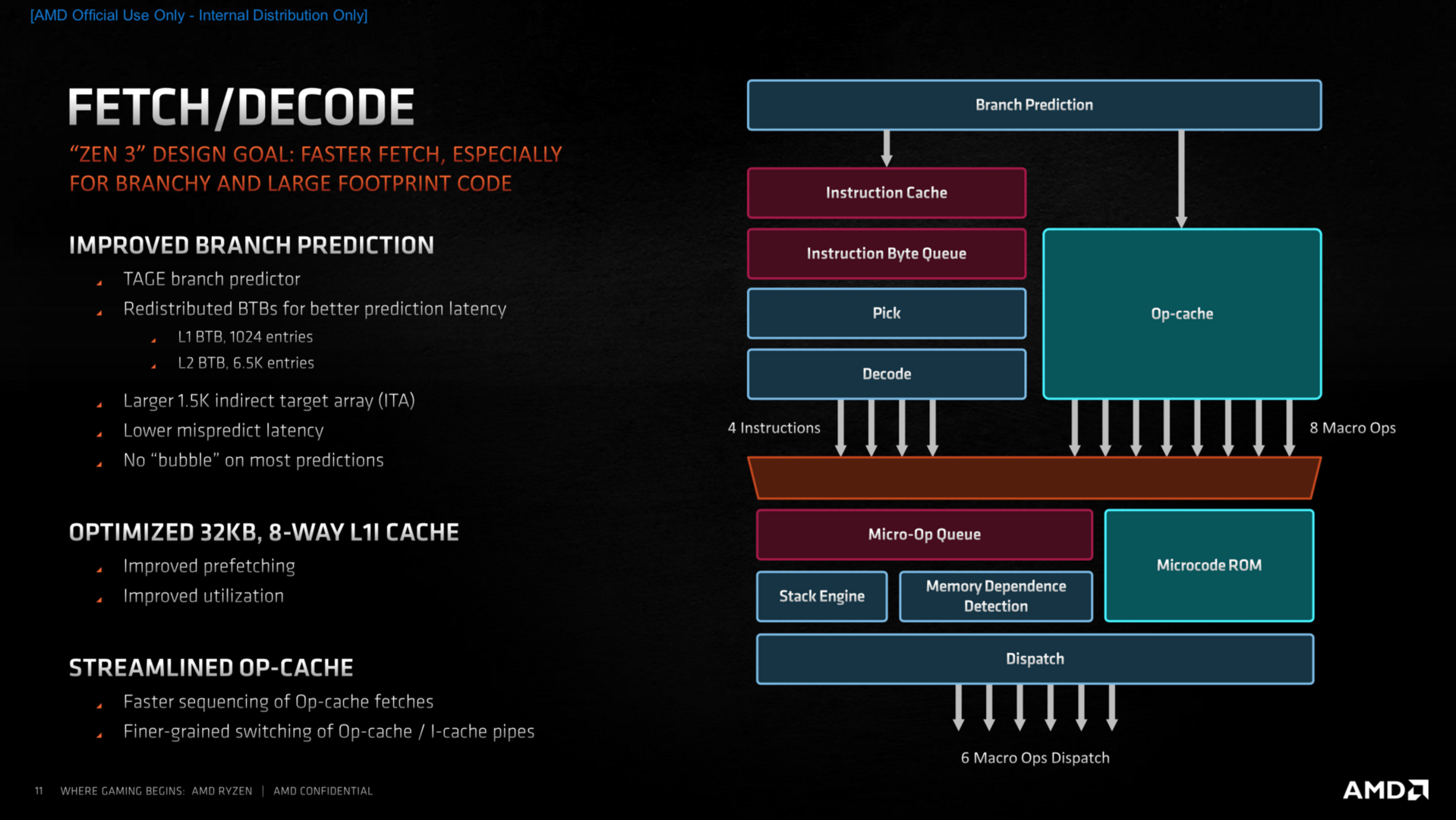
Intel war einmal Vorreiter in dieser Technologie, doch AMD hat in diesen Bereich zuletzt sehr viel Arbeit gesteckt, wie auch neue Patente untermauern und interessante Studien belegen. AMD wird in Zukunft vermutlich genau hier noch mehr Leistung herausholen, denn wie AMDs Chefarchitekt betont, war gerade das Zusammenführen der Daten aus dem Micro-Op-Cache oder denen über den klassischen Weg bisher nicht immer sehr effizient – wahrscheinlich ein Wink mit dem Zaunpfahl, was noch bevorsteht.
Verbesserte Ausführungseinheiten
Der Integer-Bereich der Ausführungseinheiten ist zum großen Teil identisch zu Zen 2, allerdings können nun deutlich mehr Befehle parallel ausgeführt werden, was der Leistung der CPU zugute kommt. Im Fließkommabereich sind die Parallelen klar erkennbar, vergrößerte Buffer und eine erhöhte Parallelisierung sollen auch hier für mehr Leistung sorgen. Der überarbeitete Load-Store-Bereich kann nun je eine Instruktion zusätzlich verarbeiten, was das Komplettpaket mit vergrößerten Puffern in fast allen Bereichen zu mehr Durchsatzrate komplettiert.
-
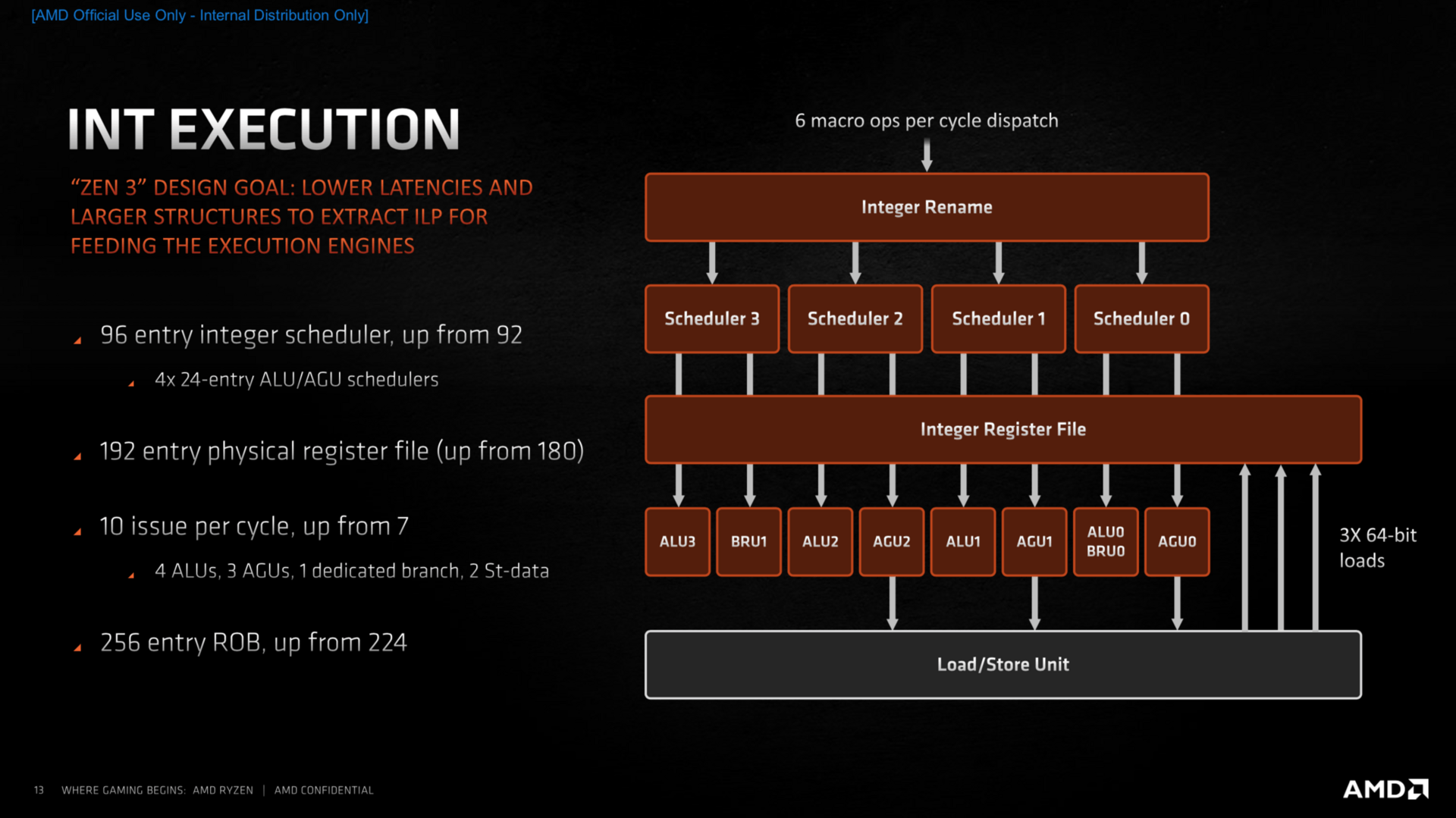 Zen-3-Architektur: Integer-Ausführung (Bild: AMD)
Zen-3-Architektur: Integer-Ausführung (Bild: AMD)
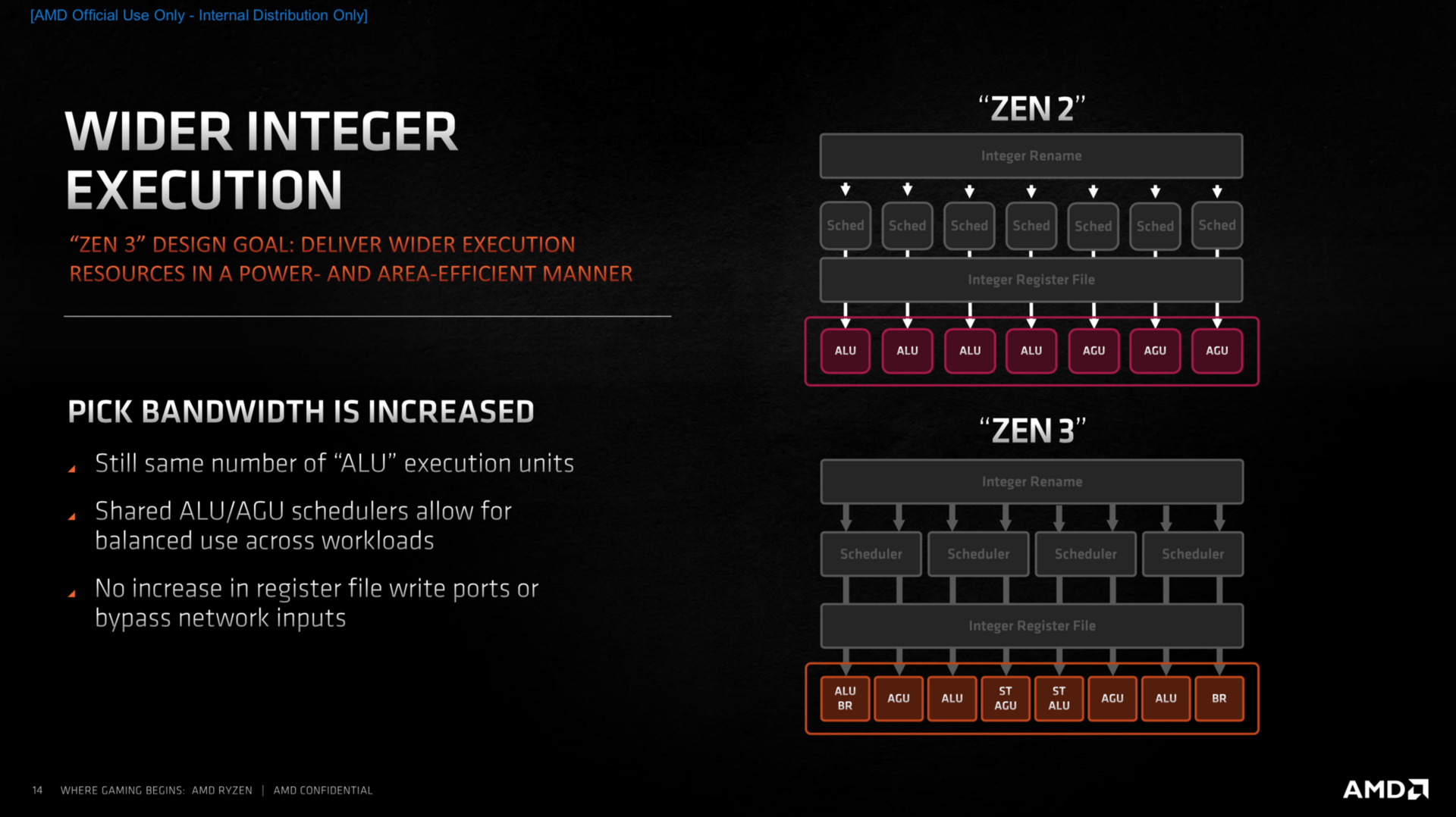
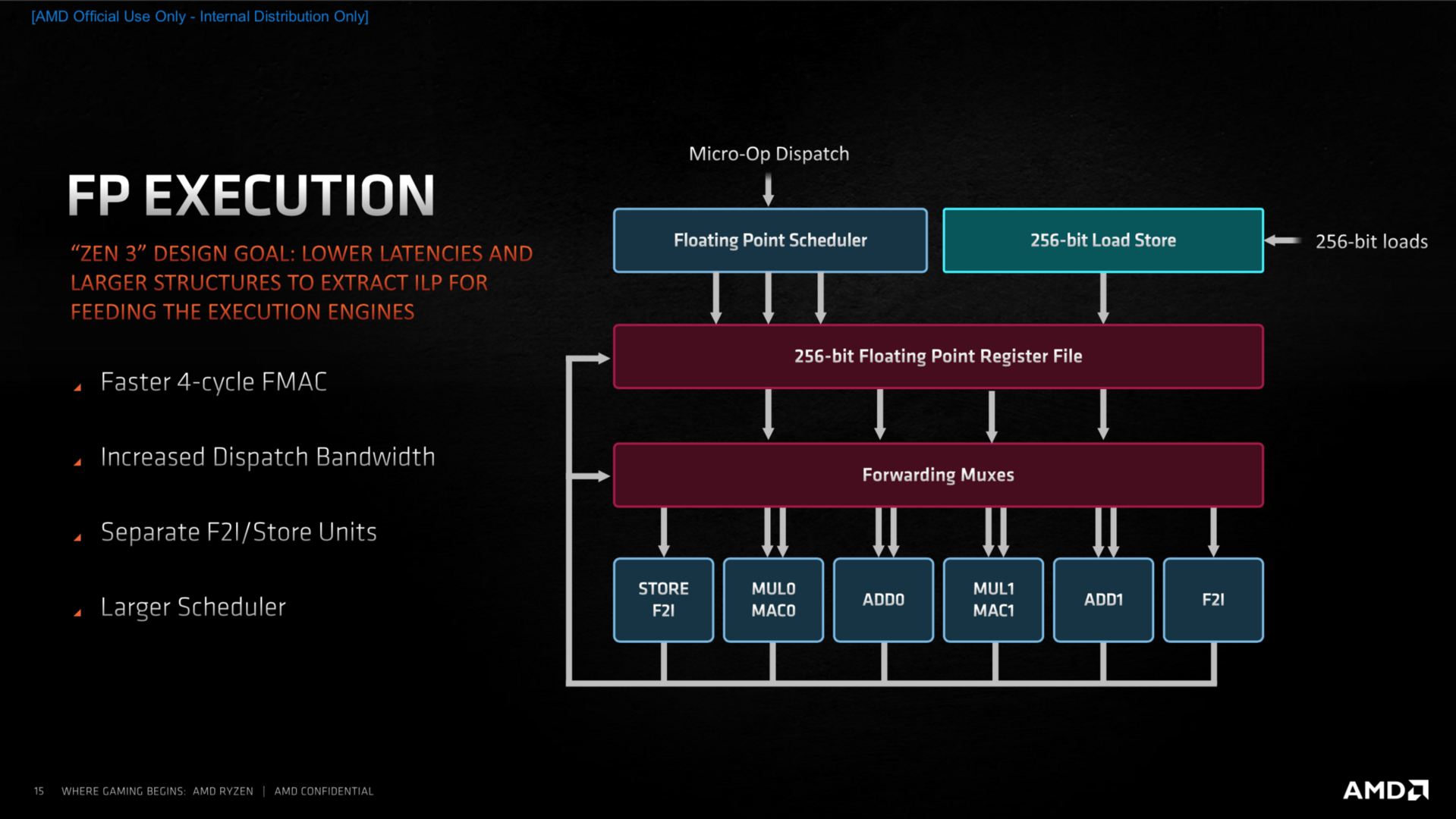
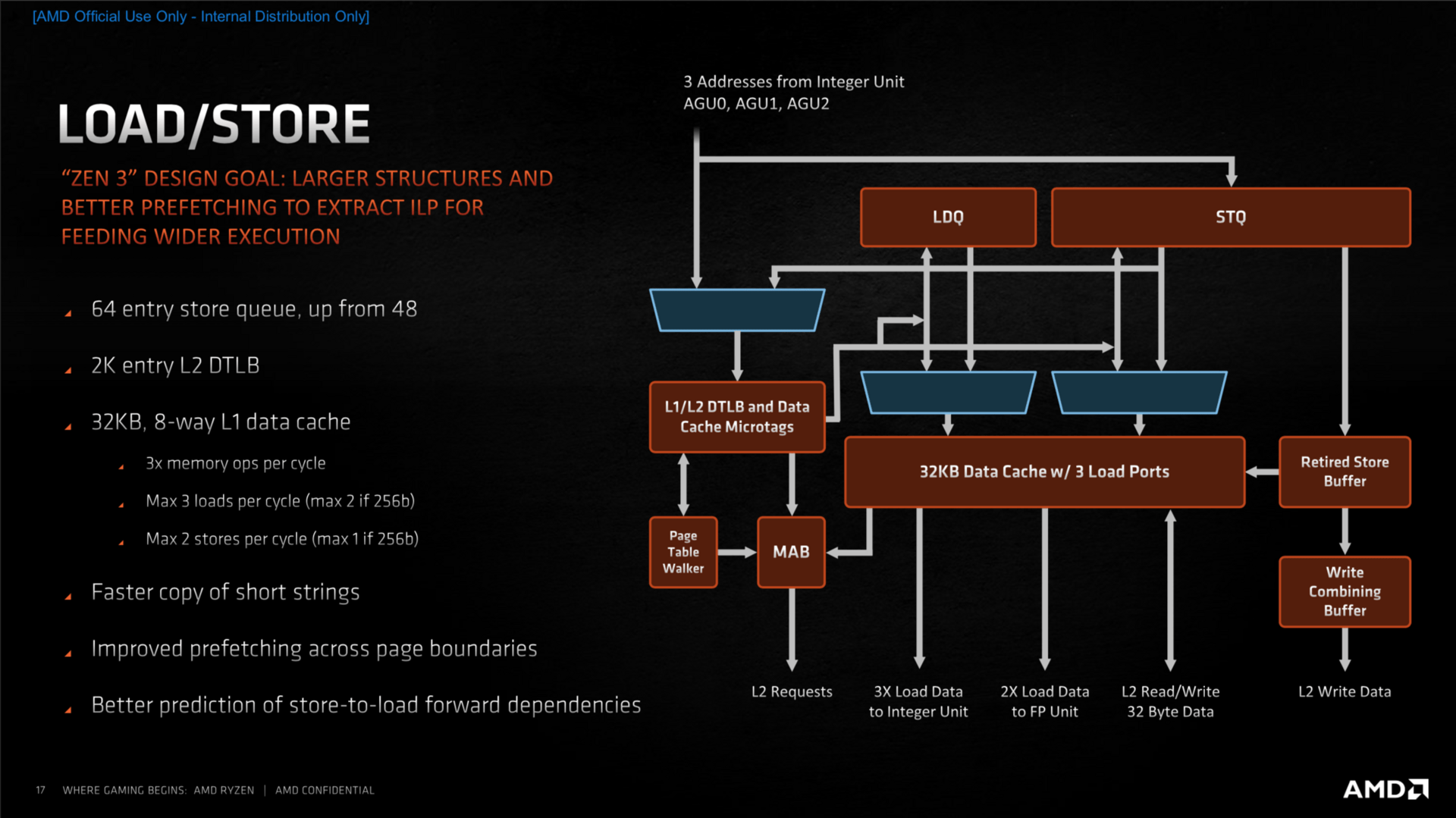
Das ISA-Set, also jene zusätzlichen Instruktionen, die die CPU beherrscht, bleibt hingegen fast völlig identisch. Das bedeutet unter anderem SHA256 aber auch weiterhin nur AVX2. Wie AMD auf Nachfrage betonte, blickt man natürlich auch auf AVX-512 sowie Matrix-Multiplikationen, wie es Intel mit dem neuen AMX-Feature bringen will.
Auch ML, also Machine Learning, hat AMD auf Roadmaps, genauso, wie man seit Jahren oder fast Jahrzehnten sich das big.LITTLE-Prinzip ansehe, doch deren Zeit im Desktop und Notebook für noch immer nicht gekommen erachtet. „Es gibt derzeit ein gutes big.LITTLE-Design“, erklärte Joe Macri in offenen Worten dazu. Und Intel war damit nicht gemeint, sondern ARM im Smartphone.
Man müsse stets aufpassen, nicht zu viel in Hardware-Vorleistung zu gehen, ohne dass die Software dazu bereit ist, erklärte der Chefarchitekt Mike Clarke. Ein Bonus sei dann nur in einem Bruchteil der Anwendungen sichtbar, die Kosten, sowohl das Mehr an Transistoren als auch Energie, unterm Strich zu hoch. Exakt dieses Problem verfolgt Intel seit fast fünf Jahren bei AVX-512, der echte Benefit ist noch heute kaum greifbar, obwohl Intel die Technik nun sogar schon ins Notebook gebracht hat.

Neue Mitigation gegen Spectre
Zen 3 hat neue Hardware-Mitigation gegen die Angriffsvektoren vom Typ Spectre enthalten, die etwas weniger leistungsfordernd und vor allem effizienter als in Zen 2 ausfallen sollen. Dort kam AMD der Zeitfaktor zugute, denn bei Zen 3 konnte AMD die Anpassungen noch im Aufbau vornehmen, während sie bei Zen 2 nur sprichwörtlich obendrauf gesetzt wurden. Dass dies am Ende zu einem effizienteren Gesamtpaket führt, ist nachvollziehbar.
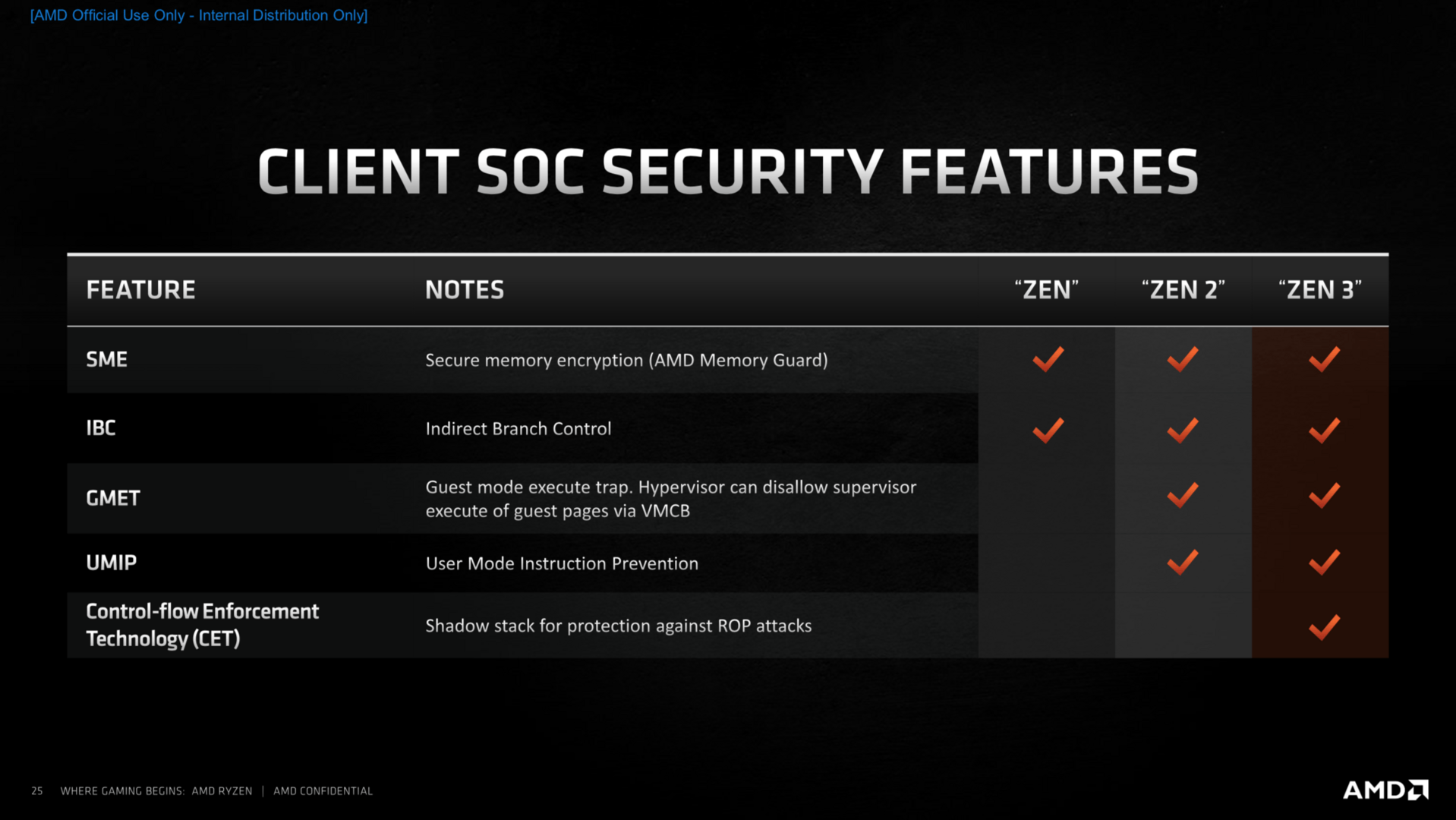
Über weitere größere Änderungen im Bereich Sicherheit hat AMD für den Client-Bereich nicht gesprochen. Zen 2 galt hier aber schon als vergleichsweise sicher, für das Server-Umfeld wird sich AMD mit Sicherheit aber noch etwas mehr haben einfallen lassen. Denn mehrfach betonte der Hersteller, dass diese Liste nur für den Client-Bereich zutreffend ist.
Mehr Leistung bei selbem Verbrauch
Mehr Leistung nur durch höheren Takt und TDP ermöglichen, ist ein Weg, wenn es denn die Plattform hergibt. AMD ist den Weg mit Ryzen 5000 aber nicht gegangen und betont das stets – ein weiterer Seitenhieb. So einfach möglich gewesen wäre das allerdings abseits der gleichen Fertigung nicht, denn der Sockel AM4 lässt gar nicht mehr zu. Bis auf maximal 142 Watt freigegeben, werden die neuen Ryzen 5000 exakt in dem Bereich arbeiten wie die Ryzen 3000 zuvor. Im Alltag bedeutet das TDPs von 65 und 105 Watt. Weil die CPUs allerdings mehr Leistung haben, sind sie als Gesamtpaket effizienter – um knapp 20 Prozent, um die auch knapp die IPC steigt.
Gegenüber dem Mitbewerber sieht sich AMD sehr gut aufgestellt, ist der Core i9-10900K doch im Extremfall mit rund 250 Watt unterwegs. Wird Cinebench R20 im Multi-Core-Test herangezogen, sei AMDs neueste Lösung um den Faktor 2,8 effizienter, erklärt der Hersteller.
Am Ende ist es bei Ryzen 5000 mit Zen 3 also das Zusammenspiel vieler Aspekte, die die Leistungssteigerung ermöglichen sollen – Fertigung und ein neuer I/O-Die gehören allerdings nicht dazu. Ohne Verbesserungen bei der Sprungvorhersage und dem Micro-Op-Cache würde das gesamte Front End nicht mehr Leistung liefern und die Load-&-Store-Einheiten tragen auf der Back-End-Seite ihren großen Anteil dazu bei, dass die Execution mehr Leistung hervorbringt. Erst am Ende setzt der Cache das I-Tüpfelchen. AMD hat das alles wenige Tage vor dem Start in einem Videobeitrag zusammengefasst:
Mainboard-Kompatibilität
Auf dem Papier steht der auch mit Ryzen 5000 genutzte Sockel AM4 für eine sehr gute Langlebigkeit seit dem Jahr 2016, doch in der Praxis werden zum Start nur Mainboards mit X570-, B550- und A520-Chipsatz funktionieren. Voraussetzung ist darüber hinaus ein aktuelles BIOS mit AGESA 1.0.8.0, damit die Platinen überhaupt booten. Zum Start sollen alle Partner bereits AGESA 1.1.0.0 ausliefern. Vor dem Start gab es fast täglich neue BIOS-Updates von Partnern, die meisten Testmuster setzen auf AGESA 1.1.0.0 Patch B oder bereits Patch C. Bis zum gestrigen Tag gab es noch BIOS-Updates – sehr zur Freude der Tester.
Eine aktuelle Übersicht über BIOS-Updates mit Ryzen-5000-Support liefert der Bericht BIOS-Updates für Ryzen 5000: Diese Mainboards unterstützen AMD Zen 3.
Bis zum Januar 2021 will AMD den im Mai dieses Jahres versprochenen Beta-Support für einige Mainboards der 400er-Serie ausrollen. Welche genau das sein werden, hängt vom Boardpartner ab.

Einen 600er-Chipsatz-Refresh wird es nicht geben. Mit der weiteren Nutzung des gleichen I/O-Dies, der bekanntlich auch den X570-Chipsatz stellt, sowie dem sehr neuen B550-Chipsatz, hielt das AMD nicht für nötig. Die nächste CPU-Generation wird ohnehin den Sockel wechseln, dann wird alles andere ebenfalls neu aufgelegt.