zer0core
Ensign
- Registriert
- Sep. 2007
- Beiträge
- 174
Guten Abend,
ich habe eine Frage bezüglich dem Aufbau meiner DB.
Als Datengrundlage habe ich eine Excel Liste, in der alle Daten in verschiedenen Spalten zusammengetragen sind. es gibt höchstens 2 Ansprechpartner.
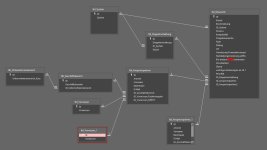
in dem angehangenen Bild seht ihr die bisherigen Beziehungen der verschiedenen Tabellen.
ich denke, dass ich bei dem Aufbau ein Denkfehler habe...
Denn wenn ich über eine Anfüge oder aktualisierungsabfrage versuche die Daten in die Tabellen zu schreiben passiert nichts...
könnt ihr mir bitte auf die Sprünge helfen?
LG Zer0
ich habe eine Frage bezüglich dem Aufbau meiner DB.
Als Datengrundlage habe ich eine Excel Liste, in der alle Daten in verschiedenen Spalten zusammengetragen sind. es gibt höchstens 2 Ansprechpartner.
in dem angehangenen Bild seht ihr die bisherigen Beziehungen der verschiedenen Tabellen.
ich denke, dass ich bei dem Aufbau ein Denkfehler habe...
Denn wenn ich über eine Anfüge oder aktualisierungsabfrage versuche die Daten in die Tabellen zu schreiben passiert nichts...
könnt ihr mir bitte auf die Sprünge helfen?
LG Zer0