Hallo zusammen,
ich habe mal eine Frage zu Git und hoffe, jemand hat vielleicht ein paar zündende Ideen.
Wir setzen bei unserer Arbeit Git als Versionskontrolle ein. Das klappt an sich auch wunderbar.
Wir haben viele verschiedene Kunden und für jeden Kunden gibt es zwei Bestandteile:
Der globale Teil enthält alle globalen Funktionen und Codes und ist kundenübergreifend identisch. Es gibt also mehrere Kunden-Teile und einen globalen Teil, der in jedes Kunden-Projekt eingebunden wird.
Nun stehen wir aber vor folgendem Problem, ich stelle hier mal ein Beispiel auf:
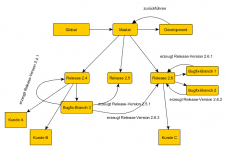
Es gibt die Kunden A und B, beide verwenden den globalen Teil in Version 2.4 - diese Version ist bei beiden Kunden im Test- und im Livesystem installiert.
Kunde A meldet einen Fehler, also erstellen wir einen Branch, beheben den Fehler und mergen das ganze wieder in den globalen Teil Version 2.4 und rollen das als Version 2.4.1 bei Kunde A im Testsystem aus.
Danach meldet Kunde B einen Fehler, also erstellen wir einen Branch, beheben den Fehler und mergen das ganze wieder in den globalen Teil Version 2.4 und rollen das als Version 2.4.2 bei Kunde B im Testsystem aus. Dabei ist natürlich der Bugfix von Kunde A auch enthalten.
Nun gibt Kunde B den Bugfix frei und möchte, dass das ganze im Livesystem installiert wird. Leider wurde der Bugfix von Kunde A noch nicht freigegeben. Ohne eine solche Freigabe sollen diese Sachen nicht installiert werden. Also muss Kunde B nun darauf warten, dass Kunde A in seinem System den Bugfix freigibt, obwohl die Kunden gar nichts voneinander wissen bzw. nichts miteinander zu tun haben.
Die große Frage ist: Hat jemand eine Idee, wie man diesen Workflow verbessern könnte, damit man nicht vor diesem Problem steht?
Ich muss noch anmerken, dass diese Beispiele stark vereinfacht sind. In der Regel sind es nicht ein oder zwei andere Tickets, auf die noch gewartet werden muss, sondern eher mal 10 oder 20. Außerdem sind das nicht immer alles nur Fehler, sondern können auch Änderungswünsche an Darstellungen etc. sein, bei denen entschieden wurde, sie global umzusetzen.
Es ist leider auch nicht möglich, da immer eine "Einzelbewertung" durchzuführen, also die anderen Tickets, die dabei mit installiert würden, einzeln zu prüfen und für ok zu befinden, aktuell sind wir auf die Abnahme angewiesen.
Hat jemand eine gute Idee, wie man das ganze verbessern könnte?
ich habe mal eine Frage zu Git und hoffe, jemand hat vielleicht ein paar zündende Ideen.
Wir setzen bei unserer Arbeit Git als Versionskontrolle ein. Das klappt an sich auch wunderbar.
Wir haben viele verschiedene Kunden und für jeden Kunden gibt es zwei Bestandteile:
- kundenspezifischer Projekt-Teil
- globaler Projektteil
Der globale Teil enthält alle globalen Funktionen und Codes und ist kundenübergreifend identisch. Es gibt also mehrere Kunden-Teile und einen globalen Teil, der in jedes Kunden-Projekt eingebunden wird.
Nun stehen wir aber vor folgendem Problem, ich stelle hier mal ein Beispiel auf:
Es gibt die Kunden A und B, beide verwenden den globalen Teil in Version 2.4 - diese Version ist bei beiden Kunden im Test- und im Livesystem installiert.
Kunde A meldet einen Fehler, also erstellen wir einen Branch, beheben den Fehler und mergen das ganze wieder in den globalen Teil Version 2.4 und rollen das als Version 2.4.1 bei Kunde A im Testsystem aus.
Danach meldet Kunde B einen Fehler, also erstellen wir einen Branch, beheben den Fehler und mergen das ganze wieder in den globalen Teil Version 2.4 und rollen das als Version 2.4.2 bei Kunde B im Testsystem aus. Dabei ist natürlich der Bugfix von Kunde A auch enthalten.
Nun gibt Kunde B den Bugfix frei und möchte, dass das ganze im Livesystem installiert wird. Leider wurde der Bugfix von Kunde A noch nicht freigegeben. Ohne eine solche Freigabe sollen diese Sachen nicht installiert werden. Also muss Kunde B nun darauf warten, dass Kunde A in seinem System den Bugfix freigibt, obwohl die Kunden gar nichts voneinander wissen bzw. nichts miteinander zu tun haben.
Die große Frage ist: Hat jemand eine Idee, wie man diesen Workflow verbessern könnte, damit man nicht vor diesem Problem steht?
Ich muss noch anmerken, dass diese Beispiele stark vereinfacht sind. In der Regel sind es nicht ein oder zwei andere Tickets, auf die noch gewartet werden muss, sondern eher mal 10 oder 20. Außerdem sind das nicht immer alles nur Fehler, sondern können auch Änderungswünsche an Darstellungen etc. sein, bei denen entschieden wurde, sie global umzusetzen.
Es ist leider auch nicht möglich, da immer eine "Einzelbewertung" durchzuführen, also die anderen Tickets, die dabei mit installiert würden, einzeln zu prüfen und für ok zu befinden, aktuell sind wir auf die Abnahme angewiesen.
Hat jemand eine gute Idee, wie man das ganze verbessern könnte?