3600er kann ich dienen - schreib mir mal, was du genau brauchst.Ned Flanders schrieb:Was uns fehlt sind ein 8-Kerniger und ein 6-kerniger (@cm87 ?) Zen2 und ein 6-kerniger Intel. Dann wärs komplett.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
- Registriert
- Aug. 2004
- Beiträge
- 12.312
Z
ZeroStrat
Gast
Mit aktivem Tweak: https://pastebin.com/8pSumqyX
@Ned Flanders Willst du auch den Run mit nicht aktivem Tweak?
@Ned Flanders Willst du auch den Run mit nicht aktivem Tweak?
- Registriert
- Aug. 2004
- Beiträge
- 12.312
Wäre gerade bei deinem hilfreich, denn der tritt ja gegen den 9900k als preisgleichen Mainstream Prozessor an.
Z
ZeroStrat
Gast
Ohne Tweak: https://pastebin.com/cMgyNcgh
I'm unknown
Rear Admiral
- Registriert
- Feb. 2005
- Beiträge
- 5.508
@ZeroStrat Sind deine Daten von einem 3700X? Falls ja spare ich mir meinen angebotenen Durchlauf, bin bisher noch nicht dazu gekommen...
Z
ZeroStrat
Gast
iamunknown schrieb:Sind deine Daten von einem 3700X?
Hab einen 3900X.
- Registriert
- Aug. 2004
- Beiträge
- 12.312
Diese CPUs haben wir bereits:

Was fehlt ist ein 6 und ein 8 Kern Ryzen 3k sowie ein 6 Kern i7. Dann wärs komplett.
Wenn wirs zusammen haben schauen wir einfach nochmal ob @SV3N den Artikel eventuell nochmal updaten will und/oder ich poste das auf Reddit mit dazugehöriger Analyse damit es mal ein paar aktuelle Benchmarks zur MKL und Matlab gibt. Gibts afaik bislang garnicht.
Was fehlt ist ein 6 und ein 8 Kern Ryzen 3k sowie ein 6 Kern i7. Dann wärs komplett.
Wenn wirs zusammen haben schauen wir einfach nochmal ob @SV3N den Artikel eventuell nochmal updaten will und/oder ich poste das auf Reddit mit dazugehöriger Analyse damit es mal ein paar aktuelle Benchmarks zur MKL und Matlab gibt. Gibts afaik bislang garnicht.
Zuletzt bearbeitet:
I'm unknown
Rear Admiral
- Registriert
- Feb. 2005
- Beiträge
- 5.508
Installiere gerade Matlab, im laufe vom Tag werde ich die beiden Durchläufe starten und dir die Ergebnisse für den 3700X bereitstellen.
I'm unknown
Rear Admiral
- Registriert
- Feb. 2005
- Beiträge
- 5.508
Die Tests sind durch, kein OC nur der RAM läuft auf dem XMP-Profil mit 3200 MHz. CPU-Last ist nicht über ca. 60% hoch, es wirkt so als ob SMT nicht verwendet wird?
https://pastebin.com/xERXhVWA
https://pastebin.com/5VQJE6yp
https://pastebin.com/xERXhVWA
https://pastebin.com/5VQJE6yp
@Ned Flanders
Mir ist grad eingefallen, dass ich meinen ja schon gebencht hab -> Post
Reicht dir das ober brauchst noch mehr?
Mir ist grad eingefallen, dass ich meinen ja schon gebencht hab -> Post
Reicht dir das ober brauchst noch mehr?
- Registriert
- Aug. 2004
- Beiträge
- 12.312
@süchtla
Perfekt, hatte ich auch vergessen!
Und herzlichen Dank auch an @iamunknown
Perfekt!
So langsam wirds umfangereicher

Perfekt, hatte ich auch vergessen!
Ergänzung ()
Und herzlichen Dank auch an @iamunknown
Perfekt!
Ergänzung ()
So langsam wirds umfangereicher
Zuletzt bearbeitet:
- Registriert
- Aug. 2004
- Beiträge
- 12.312
iamunknown schrieb:CPU-Last ist nicht über ca. 60% hoch, es wirkt so als ob SMT nicht verwendet wird?
Ja, das ist korrekt. Offensichtlich benutzt die MKL kein hyperthreading auf Intel und SMT auf AMD. Wenn ich SMT abschalte, hab ich auf dem 2600x 100% Last. Die Ergebnisse bleiben aber etwa gleich (ohne SMT ist einen Hauch schneller).
Zuletzt bearbeitet:
- Registriert
- Aug. 2004
- Beiträge
- 12.312
nullPtr schrieb:Wie ordnet Windows denn die Threads im Taskmanager? Könnte ja auch sein, dass die MKL hier nur ein Thread pro Kern benutzt (also kein SMT).
Ok, also es ist noch viel abgefahrener! Auf der Dual Xeon Kiste dauert ein Benchmark run mit HT enabled fast DOPPELT so lange wie mit HT im BIOS auf disabled.
Der Grund scheint zu sein, dass Matlab bei HT enabled alle 12 Threads von Node0 (also CPU0) auslastet (auch HT) aber Node1 garnicht, und bei HT disabled einfach alle 12 Threads auslastet, also auch die von CPU1.
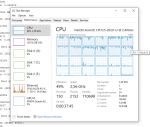
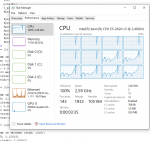
HT OFF vs. HT ON
Etwas bizarr oder?
Da stellt sich natürlich die Frage, wie viele Threads lastet die MKL denn generell aus? ist bei 12 schluss (bei SMT disabled?) Kannst du das eventuell nochmal kurz anchecken @SKu (TaskManager)?
Eigentlich kann das nicht sein, denn die neuen Threadripper legen ja sehr hohe Leistung hin.
Zuletzt bearbeitet:
Piktogramm
Fleet Admiral
- Registriert
- Okt. 2008
- Beiträge
- 10.392
An der Stelle der Hinweis, ihr testet an der Stelle nicht nur die MKL sondern auch (vorrangig?) die Implementierung seitens Matlab. Matlab selbst arbeitet ja mit threads (pthread) und die MKL bietet nochmals eigenes Threading (basiert wohl auf OpenMP). Da gibt es ein paar Hinweise seitens Intel, dass man da etwas aufpassen muss beim Pinnen der eignen und Mathethreads.Ned Flanders schrieb:Da stellt sich natürlich die Frage, wie viele Threads lastet die MKL denn generell aus? ist bei 12 schluss (bei SMT disabled?) Kannst du das eventuell nochmal kurz anchecken @SKu (TaskManager)?
https://software.intel.com/en-us/articles/using-threaded-intel-mkl-in-multi-thread-application
PS: Wenn ich zurückdenke an verteiltes Rechnen im Studium und die möglichen Probleme, die zur Laufzeit auftreten konnten, bekomme ich spontan schlechte Laune -.-
- Registriert
- Aug. 2004
- Beiträge
- 12.312
@Piktogramm Das ist natürlich ein guter Punkt! Ich hab's Mal an den Matlab Support weiter gereicht. Mal sehen was die sagen.
Kann auch ein win prob sein, wobei halt komisch ist das ohne HT der zweie node benutzt wird. Möglicherweise stellt Matlab 12 Kerne fest und startet 12 Threads und Windows belegt nur node 0?
Kann auch ein win prob sein, wobei halt komisch ist das ohne HT der zweie node benutzt wird. Möglicherweise stellt Matlab 12 Kerne fest und startet 12 Threads und Windows belegt nur node 0?
simpsonsfan
Captain
- Registriert
- Feb. 2008
- Beiträge
- 3.539
Hi, ich habe gerade nur die letzten paar Posts überflogen, klinke mich aber ebenfalls mal ein.
Bezüglich der SMT-Thematik, was erwartest du denn da? Wie soll eine rechenintensive Floating-Point-Operation durch SMT schneller werden, wenn die FPUs komplett ausgelastet sind. Die ist ja durch SMT nicht öfter vorhanden.
Wenn du nun die MKL im MPI Modus (es gab doch bei der MKL einen OMP und einen MPI-Modus, oder irre ich da gerade?) mit mehr Threads als Kernen aufrufst, müssen sich die verbleibenden Threads ja gegenseitig um Rechenleistung streiten und so gegenseitig ausbremsen. Erscheint mir zumindest logisch.
Und aus eigener Erfahrung kann ich dir sagen, dass die MKL durchaus mehr als 12 Kerne auslasten kann, konnte das seinerzeit mit einem 64-core Knight's Landing mal etwas ausgiebiger testen und die Kerne wurden durchaus genutzt.
P.S. Was die Thread-Verteilung bei Multi-CPU-Maschinen angeht, könnte die Speicheranbindung (NUMA) auch noch eine Rolle spielen. Da könnte es u.U. Einstellungsmöglichkeiten am Mainboard geben, oder auch die manuelle Threadverteilung.
Bezüglich der SMT-Thematik, was erwartest du denn da? Wie soll eine rechenintensive Floating-Point-Operation durch SMT schneller werden, wenn die FPUs komplett ausgelastet sind. Die ist ja durch SMT nicht öfter vorhanden.
Wenn du nun die MKL im MPI Modus (es gab doch bei der MKL einen OMP und einen MPI-Modus, oder irre ich da gerade?) mit mehr Threads als Kernen aufrufst, müssen sich die verbleibenden Threads ja gegenseitig um Rechenleistung streiten und so gegenseitig ausbremsen. Erscheint mir zumindest logisch.
Und aus eigener Erfahrung kann ich dir sagen, dass die MKL durchaus mehr als 12 Kerne auslasten kann, konnte das seinerzeit mit einem 64-core Knight's Landing mal etwas ausgiebiger testen und die Kerne wurden durchaus genutzt.
P.S. Was die Thread-Verteilung bei Multi-CPU-Maschinen angeht, könnte die Speicheranbindung (NUMA) auch noch eine Rolle spielen. Da könnte es u.U. Einstellungsmöglichkeiten am Mainboard geben, oder auch die manuelle Threadverteilung.
Zuletzt bearbeitet:
- Registriert
- Aug. 2004
- Beiträge
- 12.312
@simpsonsfan
Macht perfekt Sinn. Das Problem ist nicht das SMT hier nichts bringt, sondern das auf der Dual Socket Xeon Workstation nicht alle Kerne belegt werden solange HT eingeschaltet ist.
Hier mal zwei Screenshots des Taskmanagers einmal mit HT an und HT aus.
Auch bei HT aus gibts Unterschiede bei der Last zwischen CPU0 und CPU1, aber immerhin rechnet CPU1 mit. Bei HT ON garnicht.
Macht perfekt Sinn. Das Problem ist nicht das SMT hier nichts bringt, sondern das auf der Dual Socket Xeon Workstation nicht alle Kerne belegt werden solange HT eingeschaltet ist.
Hier mal zwei Screenshots des Taskmanagers einmal mit HT an und HT aus.
Auch bei HT aus gibts Unterschiede bei der Last zwischen CPU0 und CPU1, aber immerhin rechnet CPU1 mit. Bei HT ON garnicht.
Anhänge
simpsonsfan
Captain
- Registriert
- Feb. 2008
- Beiträge
- 3.539
Ah, so ist das. Wie gesagt, hatte vorher nur überflogen. Das ist ja wirklich ungünstig. Da scheint wohl irgendwas bei der Threadverteilung schief zu laufen. Was aber, wie von Piktogramm schon angerissen, nicht unbedingt allein der MKL sondern auch dem OS oder OpenMP anzulasten sein könnte. Ich habe ja gerade schon geschrieben (hat sich zeitlich mit deiner Antwort überschnitten), dass ich mir auch vorstellen könnte, das der Arbeitsspeicher bzw. dessen Einstellung da noch ne Rolle spielen kann.