LeChris schrieb:
Decoder: ein Befehl ist nur eine binäre Zahl. Heute meist noch 32 Bit. Anhand der Zahl, die ja einen bestimmten Befehl repräsentiert, stellt der Decoder quasi die CPU ein und sorgt dafür, dass die zu berechnenden Werte auch an der richtigen Recheneinheit landen.
Na, so ganz richtig ist das aber auch nicht! Es gibt keine Befehle, die komplett 32 Bit lang sind! Die meistverwendeteten sind nur 1 Byte groß und es gibt noch 2- und 3-Byte Befehle, der Rest sind Nutzdaten wie z.B. Offsets. Das ganze wird zusammen als 32 Bit Datum versendet. Die Dekodierung ist allerdings sehr aufwendig, da zwischen Daten und Befehlen unterschieden werden muss, weshalb "reines" CISC auch sehr langsam im Vergleich zu RISC ist!
LeChris schrieb:
Darüber hinaus sind Decoder heute zwingend nötig, da kein heutiger x86-Prozessor auch 1:1 die x86-Befehle versteht: es sind einfach zu viele und zu komplexe Befehle, um für jeden eine eigene Schaltung zu realisieren(Stichwort: CISC). Im Kern hat jeder Prozessor ab Pentium viele kleine Prozessoren, die dynamisch miteinander verschaltet werden können, um so viele verschiedene Befehle ausführen zu können(Stichwort: RISC).
Da hast du aber etwas falsch verstanden, CISC und RISC beziehen sich auf die Anzahl und Größe der Befehle und die CPU braucht doch nicht für jeden eine eigene Schaltung! Zum eigenlichen Berechnen sogar streng genommen nur die ALU und die FPU! Die Multimedia-Extensions klammere ich mal aus, da sie für best. Berechnungen spezialisiert und somit nicht universell sind.
CISC wird vorher in Microcode übersetzt, welcher ja wiederum RISC-ähnlich ist, da diese standartisierten und an die jeweilige CPU angepassten Befehle meist ähnlich schnell wie RISC abgearbeitet werden können. Das Dekodieren kostet natürlich wieder etwas Leistung.
Moderne CPUs haben dafür aber auch mehrere Abarbeitungs-Pipelines, das nennt sich dann Superskalare Ausführung.
Die OoO-Execution ist auch auf mehrere parallele Pipelines angewiesen, da es sonst gar nicht möglich wäre, weil beim Vorziehen eines Befehls die ganze Pipeline wieder zurückgesetzt werden müsste!
Der Scheduler verteilt die Aufgaben so geschickt an die Pipelines, das OoO einen echten Vorteil bringt. Die Verwaltung ist zwar sehr groß, aber das ganze ist immer noch schneller als In-Order-Execution.
LeChris schrieb:
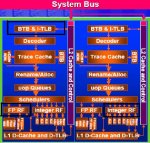
Die Befehle werden auch nicht mehr in einem Takt berechnet, beim Pentium D sind es 31 Einzelschritte. Jeder Block im Diagramm ist mindestens ein Schritt: es ist also sehr stark vereinfacht, das Diagramm. .
Das ist nur das Diagramm der Pipeline, die hat nämlich besagte 31 Stufen!
LeChris schrieb:
Unter dem Decoder sind offensichlich noch Wartepuffer(Queues) und halt der Scheduler.
Und noch die MMU, die L1- und L2-Cache-Controller, die Branch Prediction usw. Übrigens ist die Cache-Logik so fortgeschritten, dass 95% der benötigten Daten bereits im Cache vorliegt (95% Cache-Hits) und so nur im Durchschnitt nur jedes 20. Datum aus dem Hauptspeicher angefordert werden muss. Neuere "Speculative branch prediction"-Einheiten versuchen das noch zu minimieren, in dem Daten auf Verdacht (spekulativ) geladen werden. Werden sie gebraucht, entfällt die Anforderung aus dem RAM, sind sie unbrauchbar, werden sie verworfen.
LeChris schrieb:
Da wären wir wieder bei OOO: es kann ein späterer FP-Befehl vorgezogen werden, wenn aktuell halt nur Integer-Befehle anliegen. Wenn denn der FP-Befehl wirklich an der Reihe ist, wird dessen Ausführung umgangen und das bereits gespeicherte Ergebnis geliefert. (Das dürfte in der Queue geprüft werden: "wenn Befehl schon ausgeführt wurde, springe gleich zu Ergebnis" o.ä.).
Langsam, das ganze geht nur, wenn die Daten nicht voneinander abhängig sind, sich also parallelisieren lassen!
Ist das Ergebnis einer Berechnung die Grundlage für den nächsten, so muss diese Reihenfolge zwingend eingehalten werden!
LeChris schrieb:
Die Recheneinheiten rechnen halt: FP für Kommazahlen und die SIMD-Instruktionen wie SSE(2/3) und die Integer für alle ganzen Zahlen und Adressierung.
Die SIMD-Einheiten sind nur zusätzlich, die eigentlichen Integer-Rechnungen nimmt die ALU vor! Und mit der Adressierung haben die nichts zu tun, das übernehmen die Cache-Controller, die MMU und der TLB im Zusammenspiel!
PCB