Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden. Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
[Sammelthread] AI - Bildgenerierung (Stable Diffusion, Midjourney & Co)
Ich habe Supir (Juggernaut) als Upscaler genommen. Allerdings nicht in Comfyui, sondern als Separate APP von SECourse. Ansonsten bis auf auf Speed Lora (4 Steps), aber 8 Steps für die generierung, keine weiteren Lora.
Der Prompt macht bei Qwen viel aus.
Ich nutze z.b. Ollama als Server für Sprachmodelle um meinen Prompt zu verbessern. Ein guter "System Prompt" um die KI in die richtige richtung zu bringen, hilft dort sehr gut.
Da sich mein Supir Workflow gerne selber zerlegt (neue Versionen von den verschiedenen Nodes und Modellen) - Ich bin zu blöd, die App zu finden von SECourse... magst Du die hier verlinken?
Du musst bei SECourse eine Patreon Mitgliedschaft abschließen. Die günstigste reicht.
In sein scripten ist auch eine Update funktion mit drin. Es reicht also die Mitgliedschaft für einen Monat
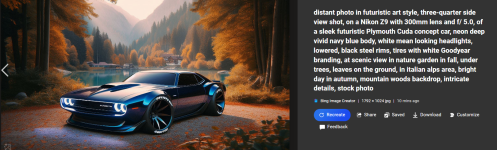
Hi Leute Als Auto und Herbst Fan ^^ mal ein paar Kreationen mit Bing Image Creator und Beispiel Prompts für Interessierte zum rauskopieren. Thema quasi Classic vs Future Muscle Cars oder so ^^
Mit der lightning lora im Gebrauch kannst du auf cfg 1 stellen, dann wird es schon etwas besser aussehen.
Mehr als 12 Steps machen wahrsch. wenig Unterschied in dem Setting.
Wenn Du keinen Prozess benutzt, der sich nach der Bildgenerierung noch um Details kümmert, bspw. über einen Upscale/Refine- Prozess, der dann noch andere models einbindet (bspw, wie blubberbirne oben sagte mit SDXL ( zu finden z.B. hier )),
dann könntest Du auch mal ein paar zusätzliche QWEN-LORAS für Realismus testen. z.B. von diesem User oder hier und hier. (Erstmal einfacher, schau Dir auch mal die Prompts usw. an; evtl. sind Trigger Wörter nötig, steht dann dabei.)
Desweiteren kann das Prompt optimiert werden, z.B. wenn du ein Foto möchtest, sollte das auch da direkt zu Beginn stehen.
Vielen Dank für Deine Arbeit mit der echt langen Liste an Vorschlägen und Tipps! Hilft mir echt beim Lernen. Nachdem ich länger mit Loras rum gespielt habe
habe ich mal QWEN Image Edit ran gezogen (bin ich echt nicht allein drauf gekommen, d'oh
Ja in der Tat benutzen manche Leute sogar die Edit Version direkt für alles (auch Bildgenerierung). Für I2I, was Du glaub ich mit QWEN Edit gemacht hast, hast Du schon was erreicht und bist im Prinzip auf dem richtigen Weg, aber wie weit Du speziell mit Qwen Edit damit kommst, wenn es explizit um Details und insb. Hautdetails geht, musst Du sehen. Für solche Prozesse wird afaik eher WAN oder SDXL benutzt, häufig in Verbindung mit Upscalern, diese Modelle können besser Hautdetails erzeugen, als das Base Modell von QWEN (ohne LORAs).
Ich hatte heute Mittag auch mal ein paar LORAS für QWEN getestet. QWEN liefert ja eine sehr gute Basis an Beleuchtung und Realismus, aber so out of the Box ist es vll etwas zu glatt manchmal und zuviel Bokeh usw. mit Hilfe der LORAS kommen Texturen und Details dann deutlich besser zum Tragen. Dein Prompt wurde auch getreuer umgesetzt, was das Bild verdunkelte (habe ich dann nicht geändert).
Grandios, gefällt mir sehr. Vielen Dank! Genau die Punkte, die mich noch gestört haben sind weg.
Ja, QWEN edit habe ich genommen, "bitte detaillierter und mehr "Dreck"". Hat tatsächlich gut geklappt aber ich gucke mir Deinen Workflow nun mal genau an, um auch ohne noch mal drüber editieren direkt ein realistisches Bild zu bekommen.
Edit: aus lauter Dollerei das Prompt mal durch Flux Schnell gejagt, das ist das, was ich auf der Arbeit nutzen kann weil nur i7-10irgendwas und 32 GB RAM (Graka zum vergessen).
Neben eines längeren Prompts, das natürlich das Bild detaillierter gestaltet usw. ist der Hauptunterschied zu Deinem Workflow das unterschiedliche Modell, das von Blubberbirne benutzt wurde (jibmix), in der Tabelle siehst Du links bereits in der Spalte OHNE LORA den deutlichen Unterschied zw. den J(ibmix)-Modellen und dem BaseModel von Qwen.