Google mit zwei „P“: Wie der AI Overview beim Buchstabieren scheitert
Google startet die nächste Ausbaustufe der KI-Suchmaschine, kämpft aber weiterhin mit Problemen und Fehlern. Ein aktueller Fauxpas: Wenn man fragt, wie viele „P“s im Wort Google enthalten sind, lautet die Antwort 2. Der Grund für solche Antworten ist nach wie vor die Architektur der KI-Sprachmodelle (LLM).
Über den Vorfall berichtet TechCrunch. Demnach entdeckten Nutzer in sozialen Medien, dass Google beim P-Zählen scheitert. Ungewohnt ist es nicht. Eine klassische Fangfrage, mit der sich KI-Systeme in die Irre führen lassen, ist die Anzahl der „E“s im Wort Erdbeere.
-
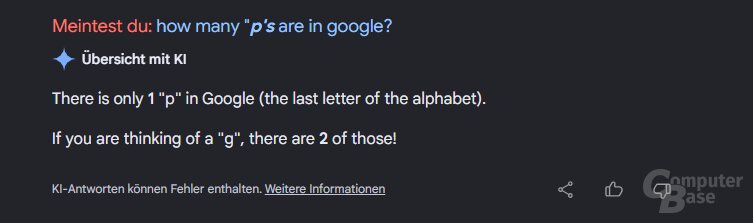 „P“s in Google zählen auf Englisch
„P“s in Google zählen auf Englisch

Den Erdbeertest bestehen KI-Chatbots mittlerweile in der Regel. Die Probleme des AI Overview beim Google-Buchstabieren tauchen derweil immer noch auf. Interessanter Aspekt: Bei Tests der Redaktion passierte das aber nur auf Englisch. Bei einer deutschen Anfrage konnte der AI Overview eine korrekte Antwort liefern.
Auf Anfrage von TechCrunch räumte Google die Probleme ein. „Das Zählen in Wörtern ist eine bekannte Herausforderung für LLMs; und wir arbeiten daran, dieses spezielle Problem zu beheben“, erklärte ein Sprecher.
Die Ursache ist die Transformer-Architektur, auf der aktuelle Sprachmodelle basieren. Diese nutzt Tokens als Grundlage, die aber nicht einzeln Buchstaben widerspiegeln, sondern Wortbestandteile. Bei dem Wort „The“ erkennt es etwa die Funktion des Begriffs – also der bestimmte Artikel auf Englisch –, sieht aber nicht die Buchstaben T, H und E, sagte Matthew Guzdial, ein KI-Forscher und Assistenzprofessor an der University of Alberta zu TechCrunch.
Details zur Architektur der KI-Modelle liefert ComputerBase in einem Hintergrundbericht.
Analyse: 91 Prozent der Antworten sind korrekt…
Solche klassischen KI-Stolpersteine sind aber nur eine Baustelle bei der KI-Suche. Und bislang sind die Hinweise noch weit entfernt von dem Debakel, das Google erlebte, als der AI Overview im Frühjahr 2024 startete. Damals empfahl die KI-Suche den Nutzern etwa Pizzakäse mit Kleber, damit dieser nicht verläuft. Das Problem war damals, dass das System Beiträge aus Foren wie Reddit als Wissensbasis nutzte – und dabei nicht unterscheiden konnte, ob es sich um satirische Inhalte handelte.
Hinzu kommen sachliche Fehler und andere halluzinierte Inhalte. Wie hoch die Fehlerrate von Googles KI-Suche ist, lässt sich jedoch nur schwer beziffern. Hinweise liefert eine Analyse der New York Times vom April 2026, bei der die Zeitung mit dem Startup Oumi kooperierte. Die Tests erfolgten also, bevor Google die neue Generation der KI-Suche auf der Entwicklerkonferenz I/O 2026 vorgestellt hat.
Oumi nutzte den branchenbekannten Benchmark SimpleQA, um die Qualität der KI-Suche anhand 4.326 Anfragen zu testen. Das Ergebnis: Mit dem älteren Modell Gemini 2 wurden 85 Prozent der Anfragen korrekt beantwortet, bei Gemini 3 (seit November 2025 verfügbar) waren es bereits 91 Prozent.
… und damit generiert der AI Overview Hunderttausende falsche Antworten pro Minute
Googles KI-Suche bewegt sich damit oberhalb der gängigen Resultate, die KI-Modelle im SimpleQA-Benchmark erreichen. Diese liegen in der Regel bei 60 bis 80 Prozent.
Angesichts der schieren Menge bedeutet eine Fehlerrate von 9 Prozent bei Gemini 3: Pro Minute werden mehrere 100.000 falsche Antworten generiert.
Wie so etwas zu Stande kommt, schildern die Forscher anhand eines Beispiels: Dem Datum, an dem das Haus des Musikers Bob Marley in ein Museum umgewandelt wurde. Die Quellen, die der AI Overview aufführt, liefern widersprüchliche Informationen. Ein Blog-Artikel nennt den 11. Mai 1986 als korrektes Datum, in Wikipedia-Artikeln finden sich aber sowohl das Jahr 1986 als auch das Jahr 1987 als Angabe. Am Ende liefert der KI-Assistent mit 1987 die falsche Information.
Google bestreitet auf Anfrage der New York Times die Aussagekraft der Analyse. Bei SimpleQA gebe es einige Schwierigkeiten. Der Benchmark simuliere zudem nicht adäquat, wie Menschen tatsächlich suchen.
KI-Assistenten nutzen Werbematerial als Quelle ohne Kennzeichnung
Ein weiteres Problem ist die Qualität der Quellen. Laut der Analyse der New York Times tauchen Reddit und Facebook häufig in den Quellen auf. Facebook wurde bei korrekten Antworten demnach in fünf Prozent der Fälle zitiert, bei fehlerhaften Antworten waren es sieben Prozent.
In manchen Fällen nutzen die KI-Assistenten auch Werbeformate wie Advertorials oder gesponserte Inhalte als Quelle, zeigt eine Untersuchung von Datapulse. Während die Originale noch korrekt gekennzeichnet sind, tauchen diese Hinweise in den KI-Antworten aber nicht mehr auf. Es fehlt also an Transparenz über die Herkunft der Inhalte.