AMD Radeon RX 6800 XT im Test: „Big Navi“ mit RDNA 2 im Detail
2/6Die Radeon-RX-5000-Serie hatte im Sommer 2019 mit „Navi 10“ einen Schlussstrich unter die Architektur Graphics Core Next (GCN) gezogen und mit RDNA (1) eine vollständig neue Architektur eingeführt. Mit der Radeon-RX-6000-Serie folgt jetzt nicht nur eine größere GPU, sondern auch die nächste Architektur-Ausbaustufe RDNA 2, die in angepasster Form auch in den Next-Gen-Konsolen PlayStation 5 und der Xbox Series X/S (Test) genutzt wird.
Das ist alt: RDNA 2 bleibt im Kern RDNA
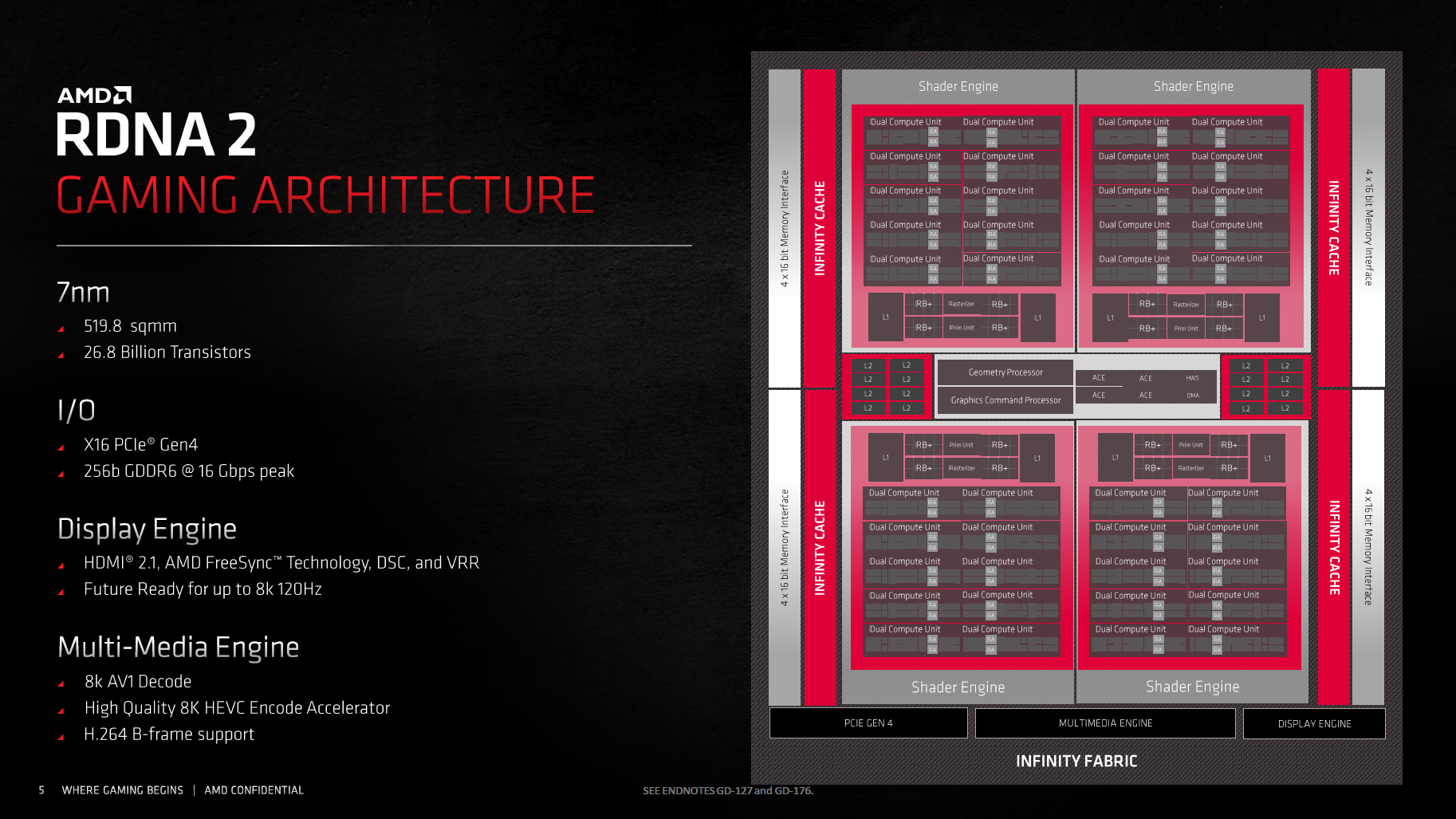
Radeon RX 6800, Radeon RX 6800 XT und auch die Radeon RX 6900 XT setzen dabei auf die gleiche und vorerst größte RDNA-2-GPU, Navi 21 oder auch „Big Navi“ genannt. Navi 21 wird in einem gegenüber Navi 10 leicht optimierten 7-nm-Prozess bei TSMC hergestellt, kommt auf eine stattliche Größe von 519 mm² und setzt sich aus 26,8 Milliarden Transistoren zusammen. Nvidia GA102 beherbergt 28 Mrd. Transistoren.
-
 Navi 21 Chip (Bild: AMD)
Navi 21 Chip (Bild: AMD)

RDNA 2 und RDNA nutzen dieselbe Basis, die bei Navi 21 in vielen Aspekten identisch, in anderen mit leichten Anpassungen übernommen wurde. Navi 21 alias „Big Navi“ bietet allerdings viel mehr Ausführungseinheiten und auch neue Funktionen, taktet höher und ist deutlich energieeffizienter aufgestellt.
Navi 10 mal zwei
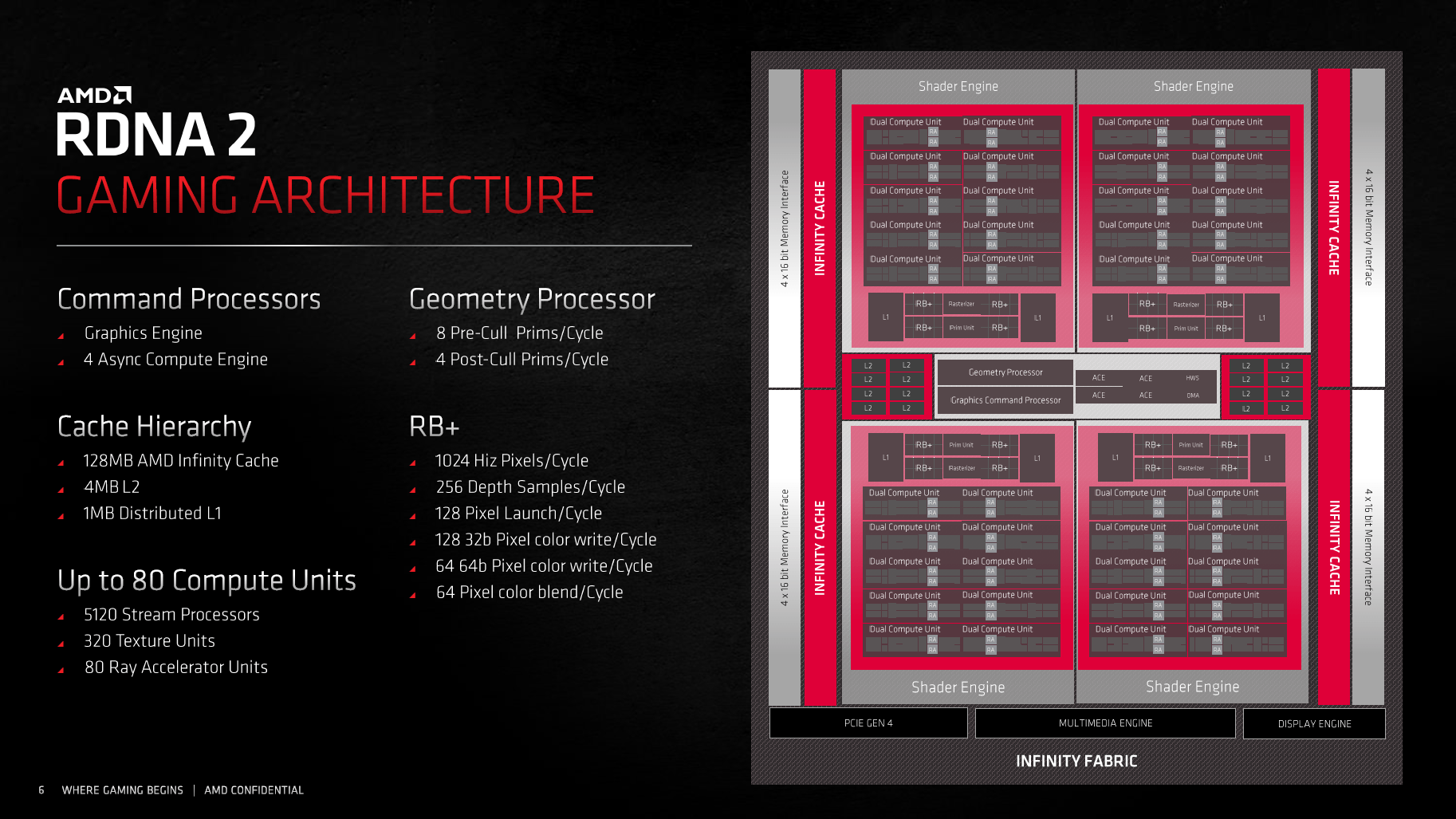
In Navi 10 (Radeon RX 5700) gab es zwei Shader Engines, in Navi 21 sind es vier. Der Aufbau einer Shader Engine ist dabei zum Großteil gleich, noch immer finden 20 Compute Units darin Platz. Die Radeon RX 6900 XT (Codename Navi 21 XTX) kann also auf 80 CUs und damit 5.120 FP32-ALUs zurückgreifen, die Radeon RX 6800 XT (Codename Navi 21 XT) auf 72 CUs (4.608 FP32-ALUs) und die Radeon RX 6800 (Codename Navi 21 XL) auf 60 CUs (3.840 FP32-ALUs). Bei Navi 21 XL wird also eine ganze Shader-Engine deaktiviert. Gleich mit beiden Ausbaustufen durchbricht AMD erstmals die 64-CU-Schallmauer (4.096 ALUs), an der der Hersteller jahrelang festgehalten hat.
| Radeon RX 6900 XT | Radeon RX 6800 XT | Radeon RX 6800 | Radeon RX 5700 XT | |
|---|---|---|---|---|
| Architektur | RDNA 2 | RDNA | ||
| GPU | Navi 21 | Navi 10 | ||
| Prozess | TSMC N7P | |||
| Chipgröße | 519 mm² | 251 mm² | ||
| Transistoren | ca. 26,8 Mrd. | ca. 10,3 Mrd. | ||
| Compute Units | 80 | 72 | 60 | 40 |
| FP32-ALUs | 5.120 | 4.608 | 3.840 | 2.560 |
| RT-Beschleunigung | Ja | Nein | ||
| Game-Takt | 2.015 MHz | 2.015 MHz | 1.815 MHz | 1.750 MHz |
| Maximaler Boost-Takt | 2.250 MHz | 2.250 MHz | 2.105 MHz | 1.905 MHz |
| FP32-Leistung | 20,6 TFLOPS | 18,6 TFLOPS | 13,9 TFLOPS | 9 TFLOPS |
| FP16-Leistung | 41,3 TFLOPS | 37,1 TFLOPS | 27,9 TFLOPS | 17,9 TFLOPS |
| Textureinheiten | 320 | 288 | 240 | 160 |
| ROPs | 128 | 96 | 64 | |
| Speicher | 16 GB GDDR6 | 8 GB GDDR6 | ||
| Speichergeschwindigkeit | 16 Gbps | 14 Gbps | ||
| Speicherinterface | 256 Bit | |||
| Speicherbandbreite | 512 GB/s | 448 GB/s | ||
| Infinity Cache | 128 MB | Nicht vorhanden | ||
| L2-Cache | 4 MB | |||
| TBP | 300 Watt | 250 Watt | 225 Watt | |
| Slot-Anbindung | PCIe 4.0 | |||
| DirectX 12 Ultimate | Ja | Nein | ||
| UVP | 999 US-Dollar | 649 Euro | 579 Euro | 399 Euro |
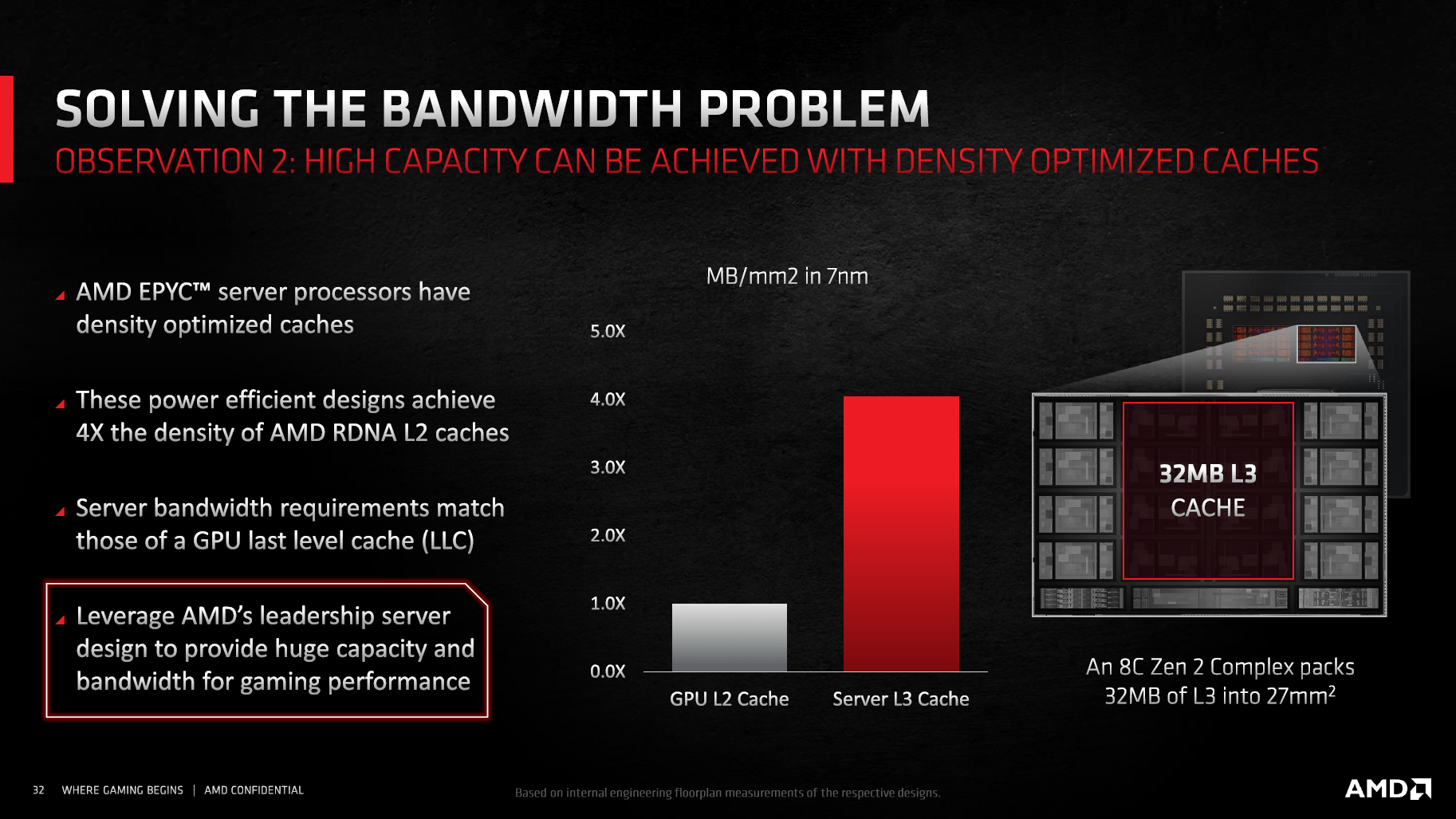
Eine CU von RDNA 2 ist laut AMD bei gleichem Takt genauso schnell wie eine CU von RDNA, der Aufbau mitsamt TMUs, doppelter Skalar-Einheit sowie L0-Cache ist gleich geblieben. Neben der CU gibt es pro Shader-Engine einen 256 KB großen L2-Cache (1 MB insgesamt), einen eigenen Rasterizer sowie eine Primitive-Einheit. Größere Änderungen gibt es bei den ROPs. Sowohl Navi 21 als auch Navi 10 setzen auf 16 ROP-Cluster, bei Navi 21 besteht ein ROP Cluster aber nicht mehr aus vier ROPs, sondern aus acht. Dadurch steigt die Anzahl der ROPs von 64 auf 128 an.
Auch abseits der Shader Engines erinnert Navi 21 an Navi 10. Es gibt einen Command Processor, der die Rechenaufgaben verteilt, sowie vier ACE- und eine HWS-Einheit, die sich um Async Compute kümmern. Der L2-Cache bleibt bei einer unveränderten Größe von 4 MB und auch das Speicherinterface ist mit 256 Bit gleich breit. Dieses setzt sich nun aber nicht mehr aus vier 64-Bit-Controllern, sondern aus sechzehn 16-Bit-Controllern zusammen.
-
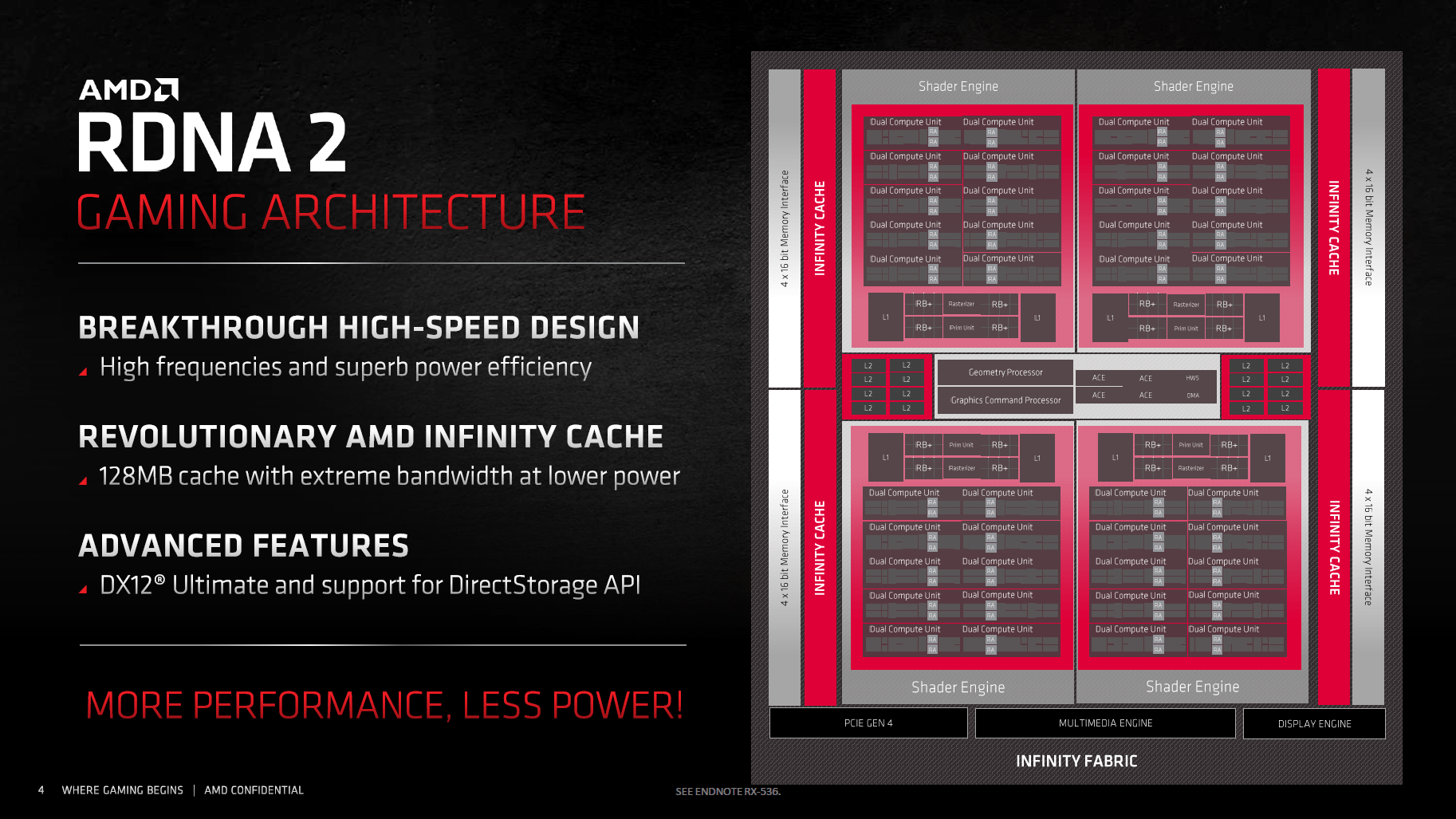 Die RDNA-2-Architektur (Bild: AMD)
Die RDNA-2-Architektur (Bild: AMD)


Die Aufzählung der Gemeinsamkeiten macht deutlich: Es müssen andere Stellschrauben sein, die es AMD ermöglichen, die Leistung am identischen Speicherinterface derart anzuheben, ohne Probleme mit der Auslastung oder der Leistungsaufnahme zu bekommen.
Das ist neu I: Die Geheimwaffe Infinity Cache
Navi 21 hat mit 80 CUs bei gleichem Takt eine doppelt so hohe Rechenleistung wie Navi 10, der L2-Cache ist aber weiterhin 4 MB groß und das Speicherinterface nur 256 Bit breit. In Kombination mit GDDR6 ist die Speicherbandbreite also vergleichsweise klein. Wie passt das zusammen?
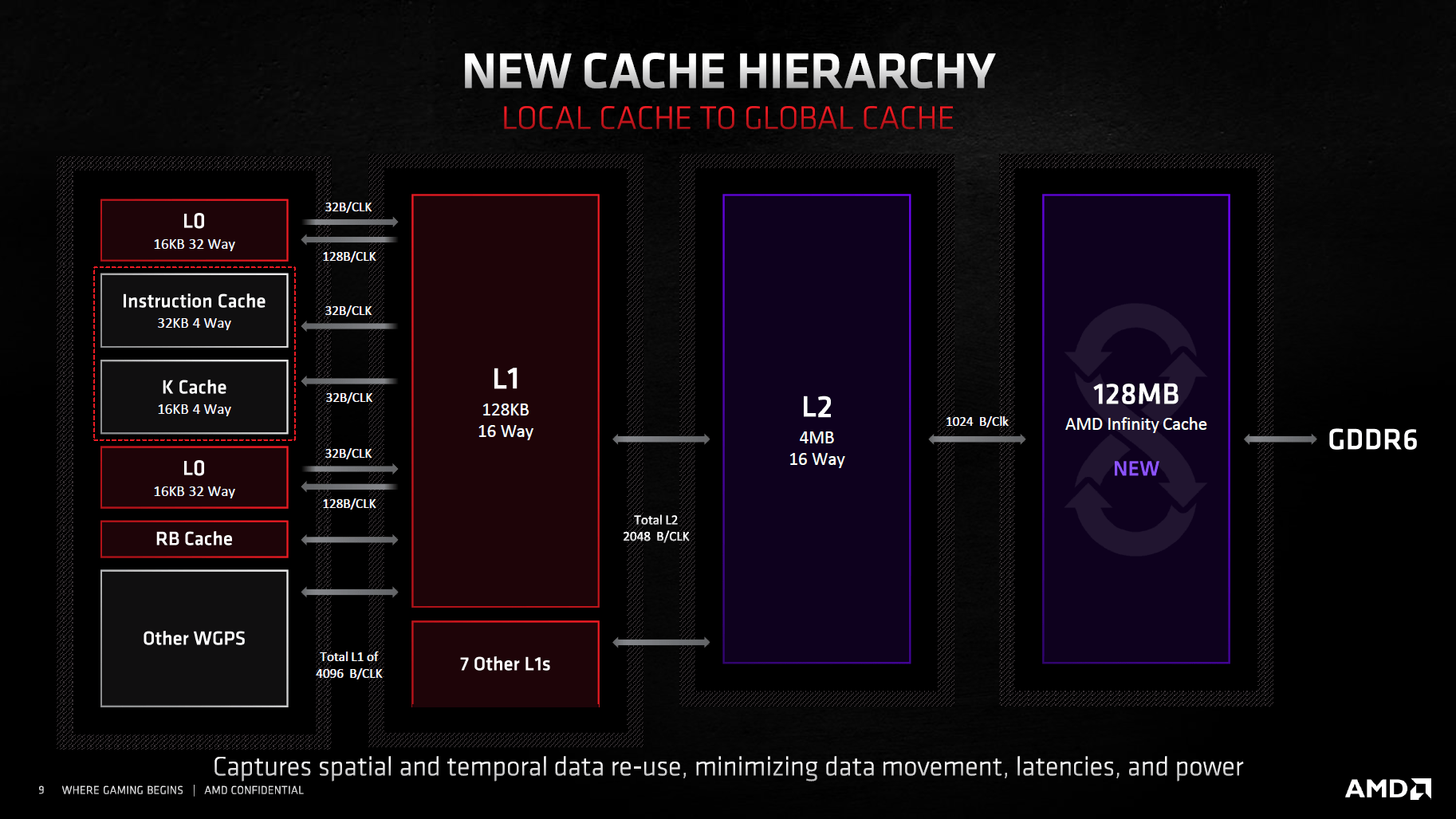
Klassisch gar nicht, aber AMD ist bei RDNA 2 einen ganz neuen Weg gegangen. Navi 21 verfügt über einen 128 MB großen zusätzlichen Cache, den AMD „Infinity Cache“ nennt. Er ist über das auch von Ryzen bekannte Infinity Fabric mit den Recheneinheiten über sechzehn 64-Bit-Kanälen verbunden. Die maximale Bandbreite zwischen Infinity Cache und GPU liegt also bei unglaublichen 2 TB/s – die Radeon VII mit HBM2-Speicher bot gerade einmal 1 TB/s, Nvidias sündhaft teure A100 Tensor Core GPU mit 80 GB HBM2e schafft es ebenfalls auf 2 TB/s.
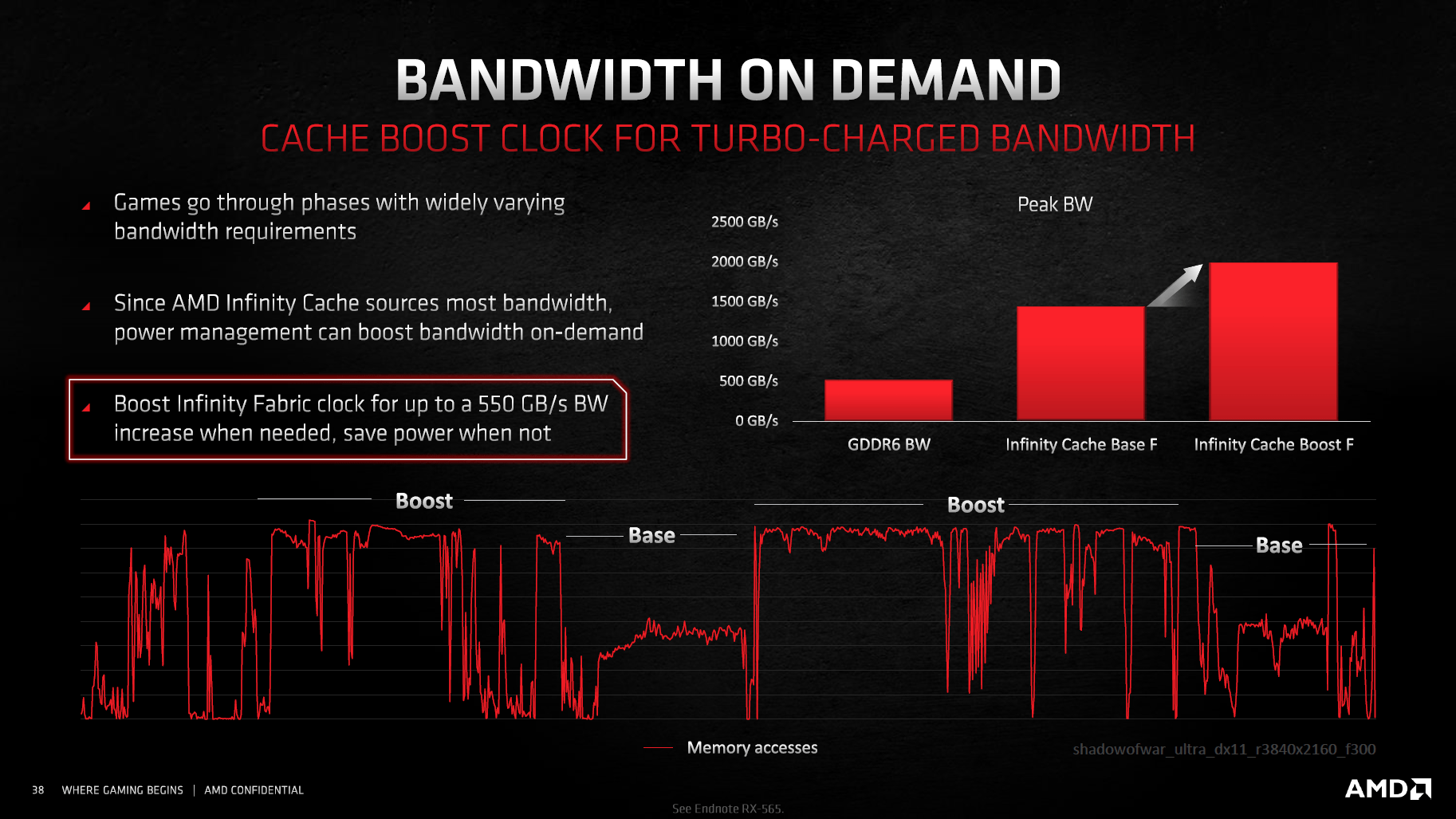
Der Infinity Cache ist an der Infinity-Fabric-Taktdomäne angeschlossen und kann daher unabhängig von der GPU takten. Der maximale Takt beträgt 1,94 GHz. Dieser Takt liegt aber nicht durchweg an, sondern nur dann, wenn auch so viel Speicherbandbreite benötigt wird. Ist der Bedarf geringer, fallen Takt und auch Energieverbrauch niedriger aus.
Ein klassisches 512-Bit-Interface soll langsamer sein
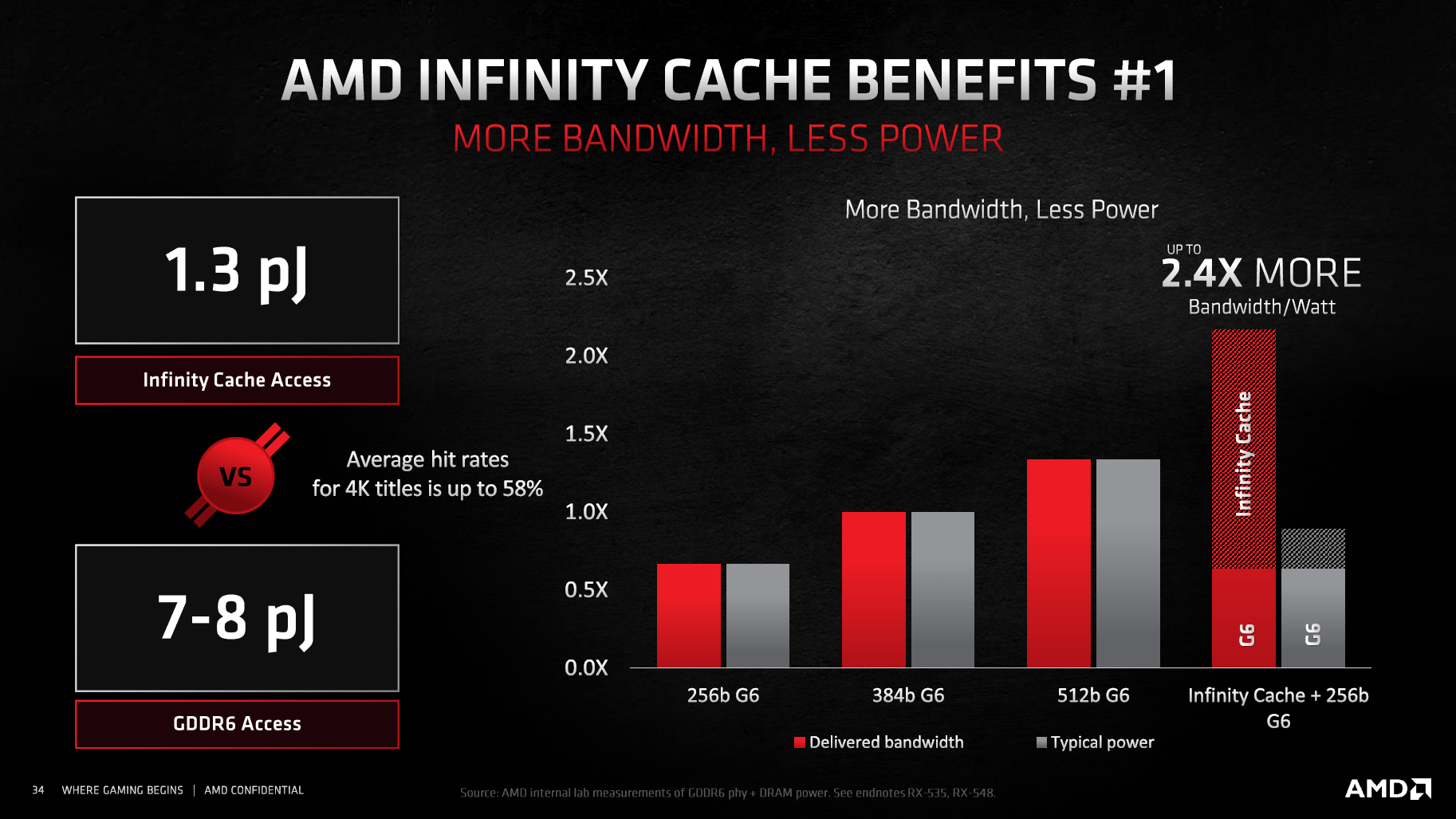
In Verbindung mit dem klassischen 256-Bit-Interface und dem 16-Gbps-GDDR6-Speicher soll die praktisch nutzbare Speicherbandbreite von Navi 21 dank Infinity Cache fast vier Mal so hoch wie nur mit einem 256-Bit-Interface ausfallen, weil viele Anfragen der GPU vom Cache abgefangen werden können. Auch gegenüber einem 384-Bit-Interface soll die auf Navi 21 genutzte Kombination um den Faktor 2,17 mehr Bandbreite liefern, also auch 512 Bit übertreffen. Die dafür benötigte Leistungsaufnahme soll wiederum nur 90 Prozent eines klassischen 512-Bit-Interfaces betragen, sagt AMD.
Weil eine GPU, die benötigten Daten schneller erhält und pro Takt mehr erledigen kann, ist der „Infinity Cache“ laut AMD einer der Gründe, warum die Rechenleistung pro CU mit RDNA 2 gegenüber RDNA am Ende effektiv doch steigen soll, auch wenn die CU an sich nicht schneller geworden ist.
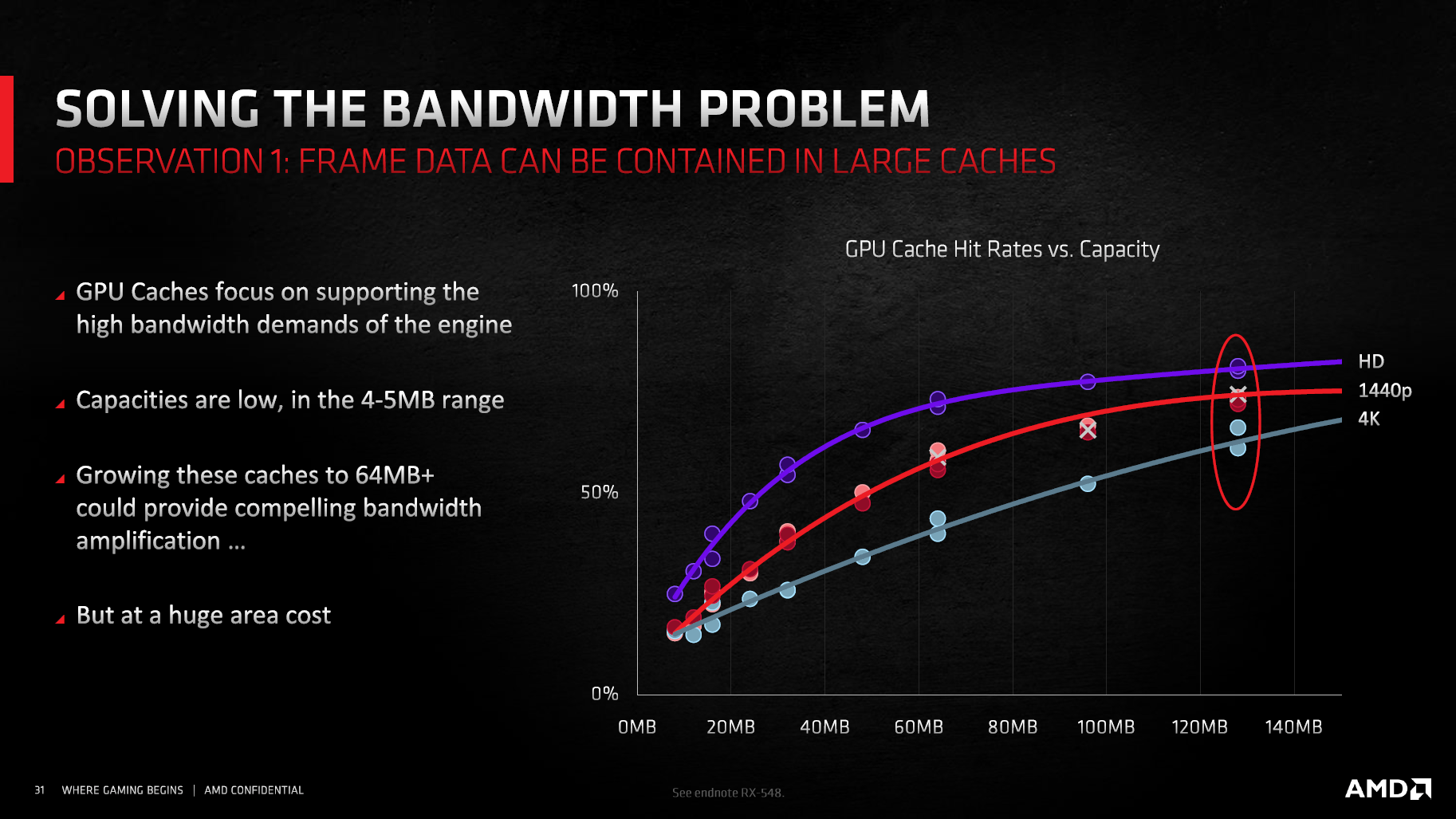
In Spielen soll der Infinity Cache laut AMD sehr effektiv arbeiten können. Die Trefferquote variiere dabei je nach Auflösung, in 1.920 × 1.080 soll sie 80 Prozent betragen, in 3.840 × 2.160 noch 58 Prozent. Liegen die Daten im Cache nicht vor, müssen diese im 16 GB großen Speicher gesucht werden. Sind die Daten dagegen im großen Cache vorhanden, werden diese nie über das VRAM-Speicherinterface übertragen. Weil dieses Übertragen der Daten viel Energie benötigt (AMD spricht von sechs bis acht Mal so viel Energie pro übertragenem Bit im Vergleich zum Infinity Cache), steigt die Energieeffizienz gegenüber einer GPU ohne Infinity Cache an.
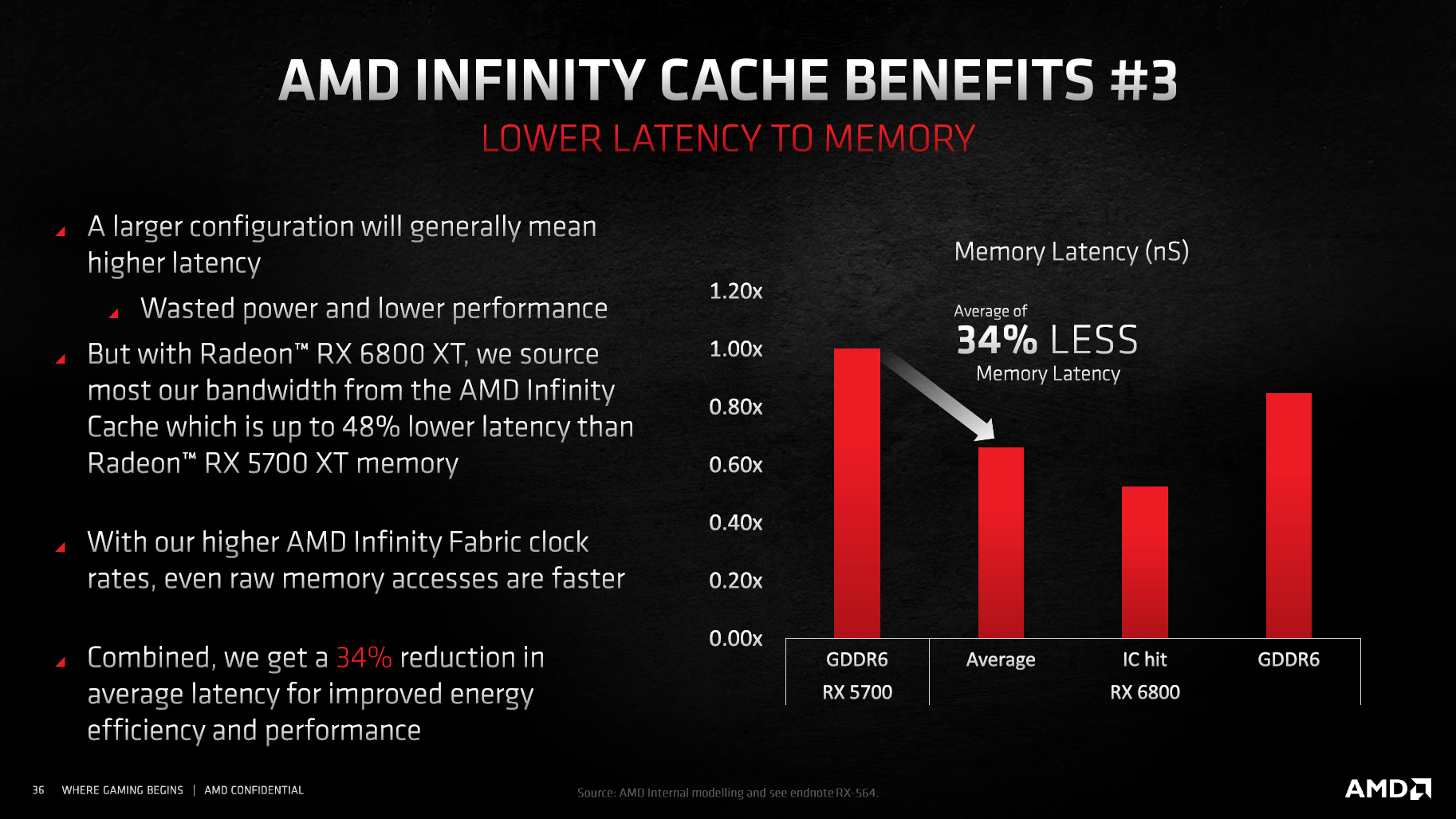
Mit dem großen Cache sollen nicht nur Bandbreite und Energieeffizienz steigen, zugleich soll die Latenz für einen Datenzugriff fallen. Das wundert nicht, da der Cache deutlich näher an den Rechenwerken sitzt als der quasi externe GDDR6-Speicher. AMD spricht von einer mehr als 40 Prozent geringeren Latenz als bei Navi 10. Liegen die Daten dagegen nicht im Cache, ist die Latenz schlechter, als wenn direkt im Speicher gesucht worden wäre. Bei über 50 Prozent Trefferquote liegt die Latenz im Durchschnitt aber niedriger. Dasselbe Spiel ist seit Zen 2 auch von Ryzen bekannt, wo der große L3-Cache „Game Cache“ heißt.
-
 Der Infinty Cache in RDNA 2 (Bild: AMD)
Der Infinty Cache in RDNA 2 (Bild: AMD)

Der „IC“ soll bei jedem Workload gut funktionieren
AMD nennt zwar keine Zahlen, verspricht aber, dass der Infinity Cache auch bei Compute, KI und anderen Rechenaufgaben sehr effektiv arbeitet und leistungstechnisch immer besser abschneidet als ein klassisches Speichersystem. Auch wenn dieser Punkt die größte Unsicherheit in der dreijährigen Entwicklungszeit des Infinity Caches gewesen ist, habe man bis jetzt noch keinen Workload gefunden, der nicht ordentlich mit dem Feature zusammen arbeitet.
Warum der Cache 128 MB groß ist? Mehr Cache ist meistens besser und auch AMD gibt zu, dass ein größerer Cache noch mehr Leistung bieten würde. Doch kostet Cache viel Chipfläche, sodass eine Vergrößerung nicht ohne Weiteres möglich gewesen wäre. Die genutzten 128 MB sollen sich dabei perfekt für Ultra HD eignen, 8K könnte dagegen auch mit einem größeren Cache etwas anfangen. Weil die Auflösung aber vermutlich zu Lebzeiten von Navi 21 kaum bis gar keine Rolle spielen wird und die 128 MB durchaus noch gut, wenn auch eben nicht perfekt mit höheren Auflösungen als 4K zurecht kommen, hat es AMD bei der Größe belassen.
Für den Infinity-Cache muss keine Software angepasst werden, damit dieser benutzt werden kann, AMD hat das in Firmware und Treiber geregelt. Allerdings gibt AMD zu verstehen, dass dies nicht der optimale Weg sei und der Konzern deshalb mit dem Gedanken spiele, eine genauere Kontrolle über den Infinity Cache einzubauen, die Software-Entwickler nutzen könnten, um die Leistung zu maximieren.
Die Skalierung bei kleineren GPUs
Die 128 MB setzen sich bei Navi 21 mit vier Shader Engines aus vier Blöcken mit je 32 MB zusammen. Damit liegt auf der Hand, wie kleinere GPUs konfiguriert sein dürften: Navi 22 mit kolportierten zwei Shader Engines mit 40 CUs dürfte auf 64 MB zurückgreifen. Einen noch kleinere RDNA-2-GPU würde einen weiteren Block weggelassen und der Infinity Cache wäre dann noch 32 MB groß. Damit sinkt zwar automatisch auch die Grafikauflösung, bei der der Cache noch gut funktioniert. Doch dürften 64 MB für WQHD und 32 MB für Full HD ausreichen.
512 Bit waren keine Option mehr
In der Vergangenheit ist AMD das Thema Speicherbandbreite mit einem deutlich breiteren Interface (und HBM) angegangen und Nvidia setzt zwar nicht auf 512, aber immerhin 320 bis 384 Bit und extrem schnellen GDDR6X bei den Topmodellen. 384 Bit hätten laut AMD allerdings nicht genügt um die 80 CUs zu versorgen. 512 Bit hätten es, aber da war der Hersteller mittlerweile offensichtlich geläutert, denn die Nachteile in Bezug auf Chipfläche, Stromverbrauch und Kosten (in Folge von Chipfläche und Platinenlayout) sind enorm.
256 Bit und 16 GB sind ein gutes Team
Einen weiteren großen Vorteil, den Infinity Cache mit dem 256-Bit-VRAM-Interface mit sich bringt, hat AMD gar nicht genannt: 16 GB Speicher, der logische nächste Schritt beim Speicherausbau, sind einfach umsetzbar. Mit den von Nvidia genutzten 320-Bit- oder 384-Bit-Interfaces gibt es hingegen das Problem, dass der umsetzbare Speicherausbau mit 10 respektive 12 GB gegenüber dem bisherigen Standard von 8 GB nicht allzu üppig, oder mit 20 respektive 24 GB – zumindest für Spieler – direkt übertrieben groß und teuer ausfällt. Nvidia GeForce RTX 3080 (10 oder 20 GB) und GeForce RTX 3090 (12 oder 24 GB) machen dieses Dilemma offensichtlich
Und ein kleineres Interface dank Infinity Cache passt nicht nur im High-End-Bereich gut zur naheliegenden Speicher-Evolution. Es ist gut denkbar, dass der Nachfolger der Radeon RX 5700 XT nur ein 192-Bit-Interface und einen 12 GB großen Speicher haben wird. Mit 256 Bit würde es entweder erneut nur 8 GB oder 16 GB geben – letzteres ist für eine WQHD-Grafikkarte nicht nötig. Und der Nachfolger der Radeon RX 5500 XT könnte trotz höherer Rechenleistung wieder problemlos auf 128 Bit und 8 GB setzen.
Das ist neu II: Taktraten von bis zu 2,5 GHz
Grafikkarten hängen bereits seit Nvidias Maxwell-Generation (GeForce 900) um die 2,0-GHz-Marke fest. Ampere hat den Grenzwert mit 2,1 GHz zwar erstmals etwas deutlicher darüber gelegt, eine Revolution beim GPU-Takt hat es aber schon lange nicht mehr gegeben. Das gilt auch für AMD: Radeon-Grafikkarten haben nur mit Glück die 2,0-GHz-Marke durchbrochen.
RDNA 2 gelingt das jetzt spielend und auch die 2,1 GHz von Gaming-Ampere sind kein Maßstab für Navi 21. AMD nennt für die Radeon RX 6800 einen offiziellen Game-Takt von 1.815 MHz und einen Turbo von 2.105 MHz. Für Radeon RX 6800 XT und Radeon RX 6900 XT sind es gar 2.015 MHz und 2.250 MHz. Doch die richtige Überraschung hält die Praxis parat: Der Takt liegt im Einsatz noch viel höher.
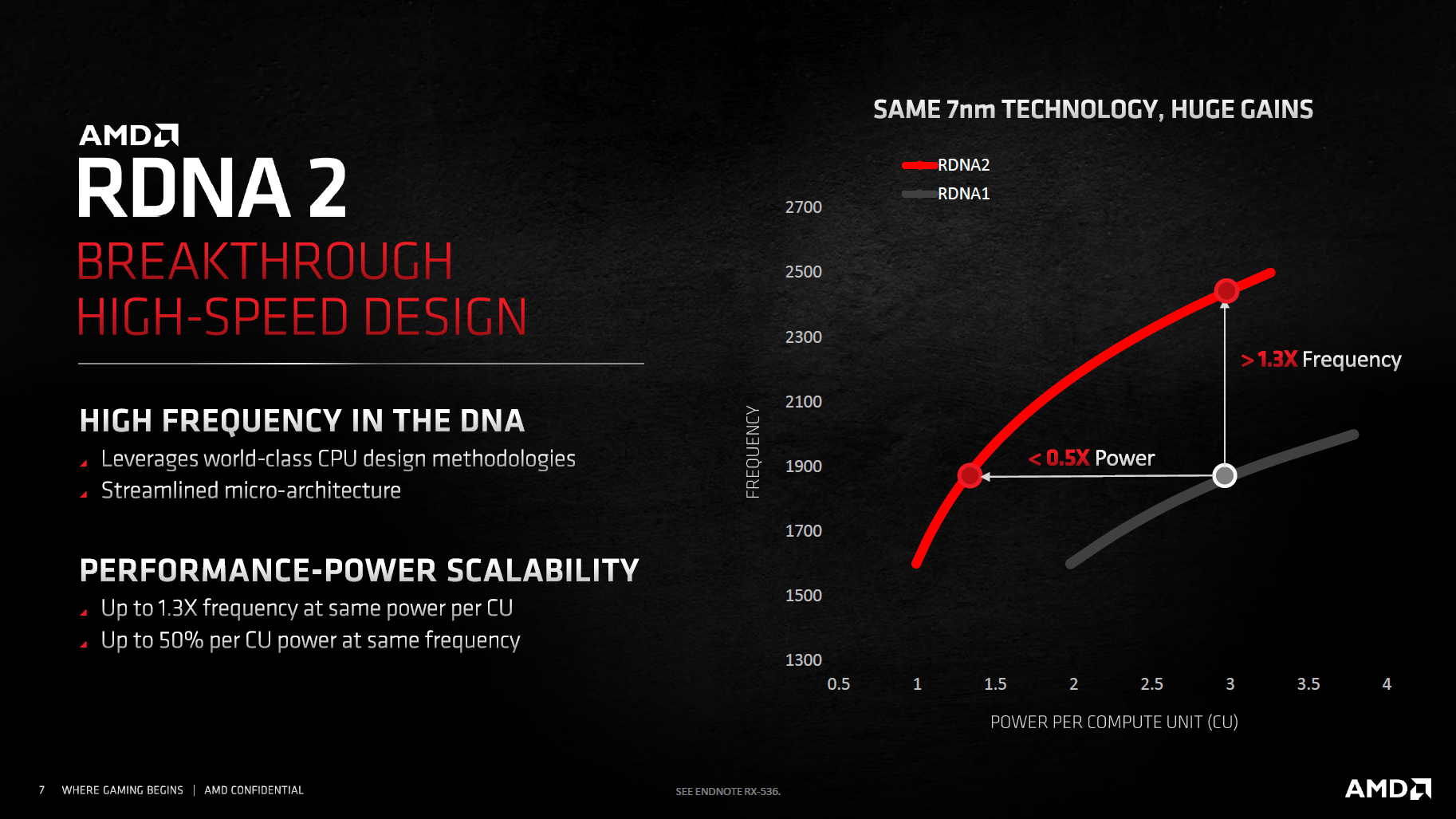
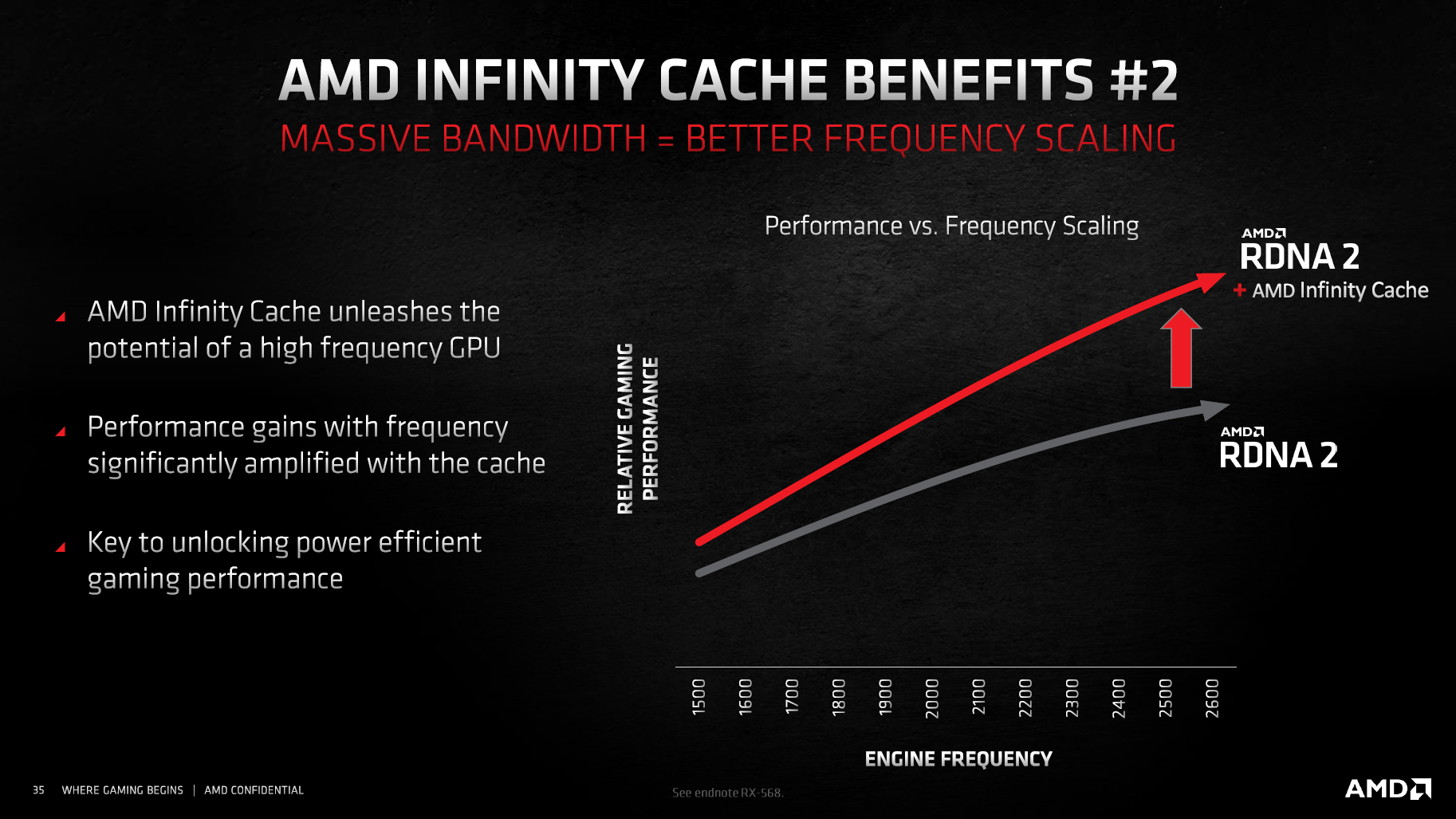
Bereits mit den Standardeinstellungen taktet die Radeon RX 6800 XT in Spielen bis maximal 2.350 MHz. Und wer die Grafikkarte übertaktet, kann Navi 21 auch ohne Spannungserhöhung auf knapp über 2,5 GHz bringen. Der Sprung ist schon für sich beachtlich, noch beachtlicher wird es unter Berücksichtigung des Stromverbrauchs, der durch den hohen Takt nicht negativ beeinträchtigt wird.
Der Grund: RDNA 2 benötigt bei gleichem Takt nur halb so viel elektrische Leistung pro Compute Unit wie RDNA, oder kann bei gleicher Verlustleistung 30 Prozent höher takten. Wie AMD das geschafft hat, dazu gibt der Hersteller keine Details preis. Ein wesentlicher Faktor soll allerdings die manuelle Optimierung vieler Chip-Bestandteile gewesen sein, statt auf eine Automatik zu vertrauen, die weniger den Taktraten, als der Packdichte zugute kommt. Hilfreich soll dabei auch das Team hinter der CPU-Architektur Zen gewesen sein, weil deren Mitglieder Erfahrungen mit hohen Frequenzen haben, die dem GPU-Team gefehlt hätten.
Das ist neu III: 65 Prozent mehr Leistung pro Watt
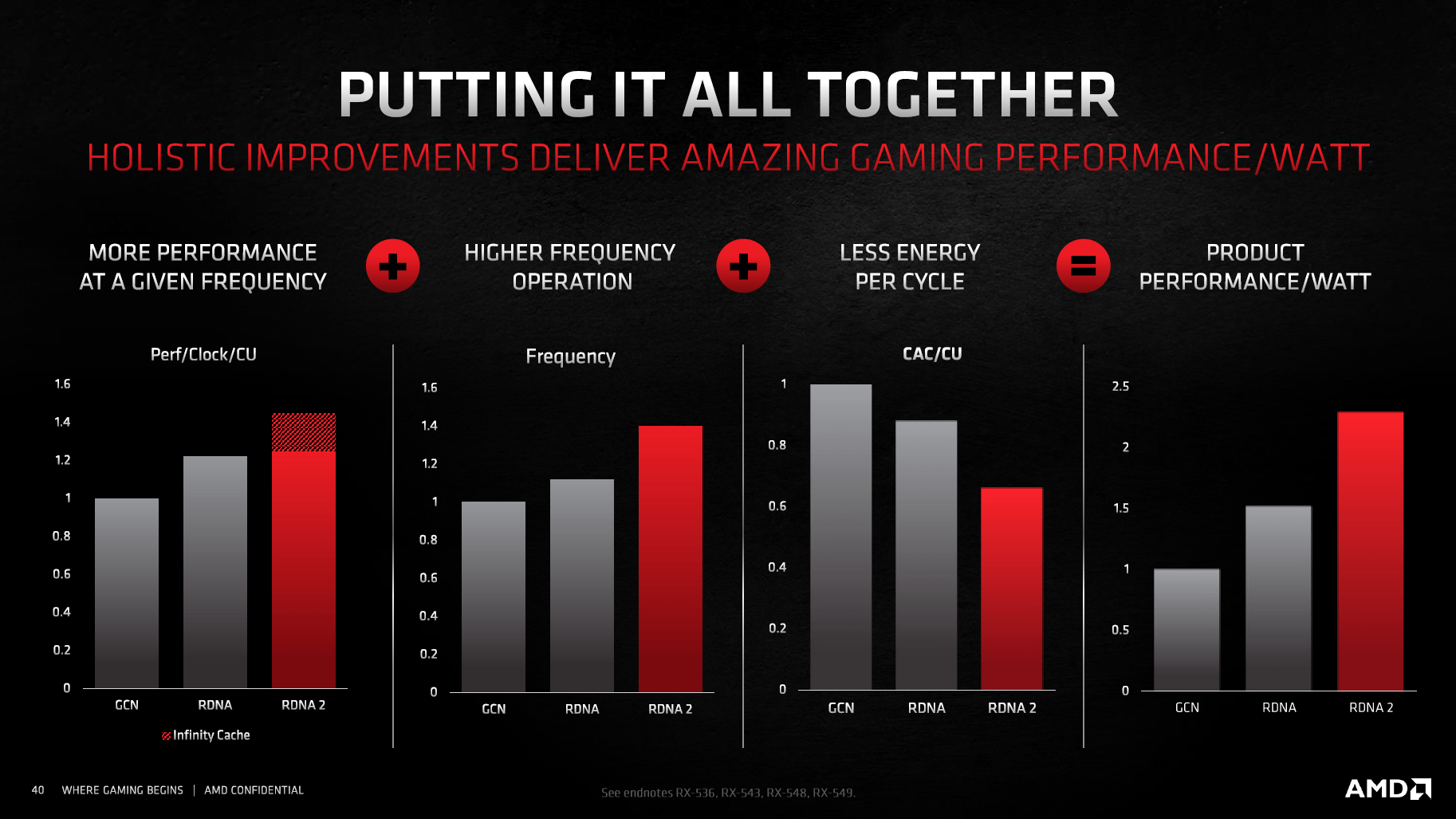
Höherer Takt bei gleichem Verbrauch führt zur dritten wesentlichen Neuerung der Navi-21-GPU mit RDNA 2: Der massiv gestiegenen Energieeffizienz, und zwar ohne dass AMD einen großartig anderen Fertigungsprozess nutzt. Er soll zwar leicht gegenüber TSMCs N7P optimiert worden sein, der Basis-Prozess sei aber immer noch derselbe. Nichtsdestoweniger nennt AMD für die Radeon RX 6800 XT eine um 54 Prozent verbesserte Performance pro Watt, bei der Radeon RX 6900 XT sind es gar 65 Prozent.
Den einen Grund für diesen enormen Schritt gibt es nicht, stattdessen sollen viele verschiedene Änderungen dazu beigetragen haben. 16 Prozentpunkte von den 54 Prozent Fortschritt bei der Radeon RX 6800 XT sollen von den höheren Taktraten stammen, weil sie auf RDNA 2 nicht mehr Leistung benötigen. 17 weitere Prozentpunkte stammen von allgemeinen Optimierungen wie zum Beispiel einem reduzierten Datenverkehr, darüber hinaus wurde das Clock-Gating weiter optimiert. Und 21 Prozentpunkte setzen sich aus einer verbesserten Performance pro Takt zusammen, die unter anderem durch den Infinity Cache mit seiner hohen Trefferquote und dem kleineren 256-Bit-Interface herrührt, sowie einer verbesserten Geometry-Leistung inklusive Tessellation zusammen.
-
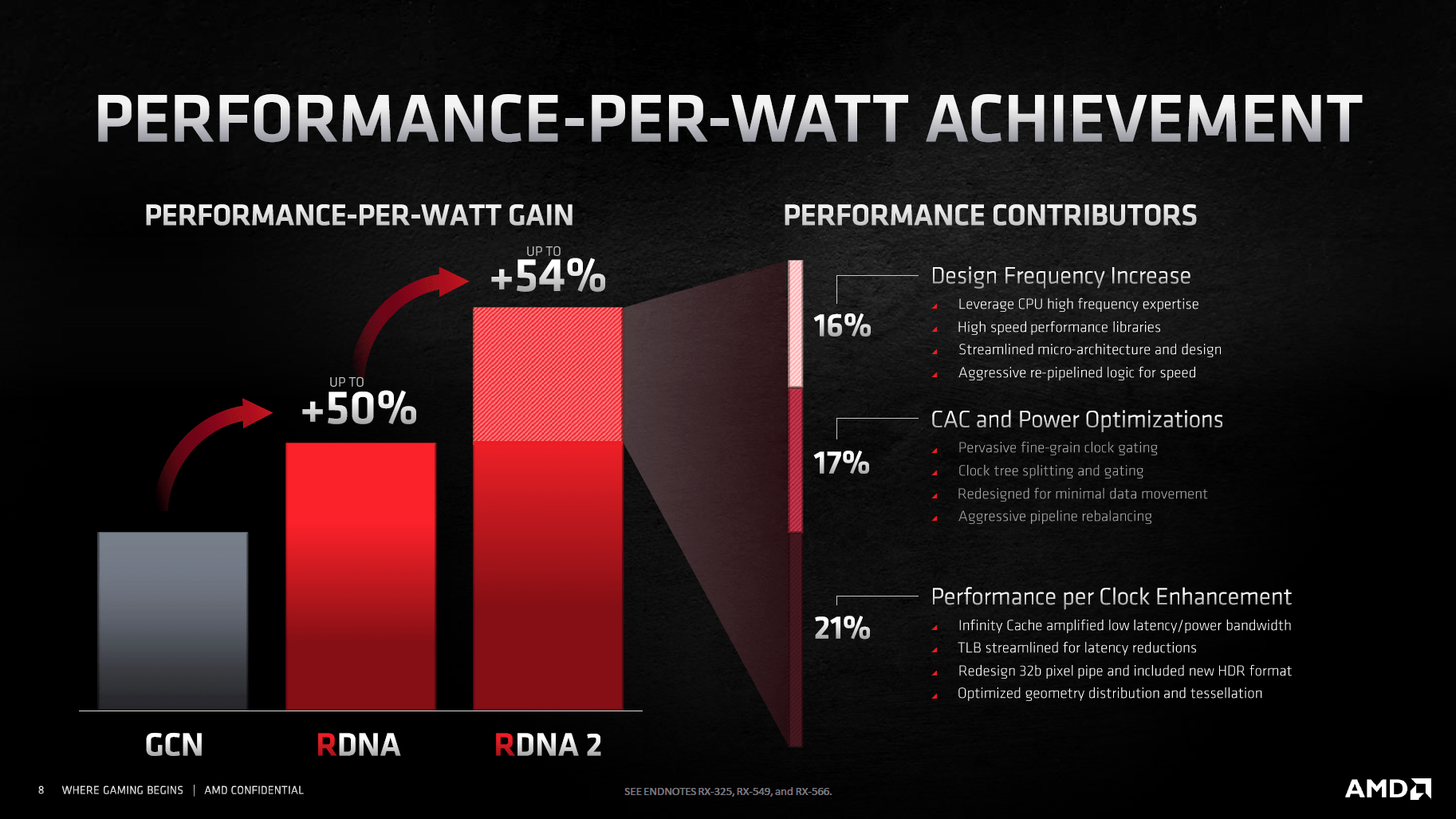 Die Energieeffizienz ist deutlich gestiegen (Bild: AMD)
Die Energieeffizienz ist deutlich gestiegen (Bild: AMD)

Das ist neu IV: RDNA 2 kann Hardware-Raytracing
Die vierte wesentliche Neuerung ist die Implementierung einer Raytracing-Beschleunigung in Hardware. Nvidia hat Hardware-Raytracing mit der GeForce-RTX-2000-Serie bereits vor zwei Jahren eingeführt und mit den neuen GeForce-RTX-3000-Karten optimiert. Seitdem hat sich „RTX“ als Synonym für in Hardware beschleunigtes Raytracing etabliert, doch RTX ist lediglich Nvidias Marketing-Bezeichnung für die Umsetzung einer Technologie, die beispielsweise Microsoft in DirectX 12 mit „DXR“ beschrieben hat.
Bei AMD hält Raytracing erstmals mit RDNA 2 Einzug. Und die Umsetzung entspricht nicht 1:1 der, die Nvidia gewählt hat.
Während Nvidia mächtige separate Raytracing-Einheiten auf der GPU verbaut, die relativ viel Fläche benötigen, dafür aber auch die Erstellung der BVH-Struktur und die Schnittstellenprüfung (Ray Traversal) beschleunigen, verzichtet AMD auf die Beschleunigung der Bounding-Volume-Hierarchy-Struktur (BVH) in Hardware. Sie wird stattdessen auf den normalen FP32-ALUs als Compute Shader durchgeführt.
-
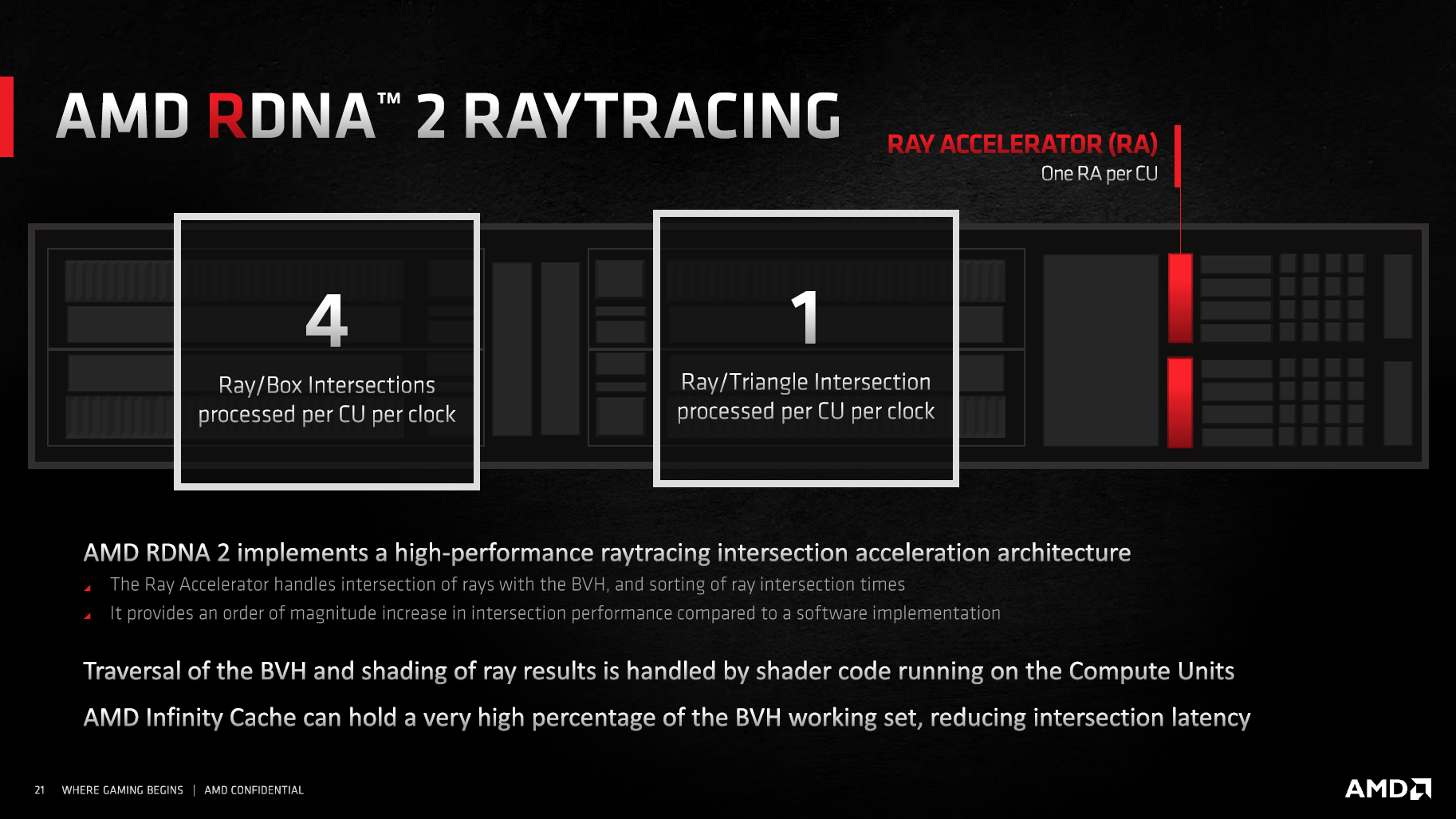 Spezielle Raytracing-Einheit bei RDNA 2 (Bild: AMD)
Spezielle Raytracing-Einheit bei RDNA 2 (Bild: AMD)

Wie viel langsamer das gegenüber der separaten Beschleunigung ist, dazu äußert sich AMD nicht, die Benchmarks werden allerdings zeigen, dass es Leistung kostet. Laut AMD soll Infinity Cache in der Lage sein, den Leistungseinbruch klein zu halten, weil er bereits erstellte BVH-Strukturen zu einem Großteil speichern kann, sodass diese nicht neu erstellt werden müssen.
Die Compute Unit wird um einen „Ray Accelerator“ erweitert
Ray Traversal wird wie bei Turing und Ampere auch auf RDNA 2 in separaten Einheiten beschleunigt. Dafür hat AMD in jede Compute Unit einen „Ray Accelerator“ (RA) verbaut, Navi 21 bietet also 80 RAs. Ein RA kann pro Takt vier Ray/Box-Schnittstellen oder eine Ray/Dreiecksschnittstelle berechnen, was um den Faktor 10 schneller sein soll, als wenn dies alles per Compute Shader berechnet werden würde. Anders als bis jetzt vermutet, soll der RA auch gleichzeitig zu den FP32-ALUs und den restlichen Einheiten einer Compute Unit arbeiten können. AMD spricht explizit von „no blocking“ während Ray Traversal berechnet wird.
Da AMD die Raytracing-Einheit in der Compute Unit verbaut, skaliert ihre Anzahl automatisch mit den anderen Bauteilen der CU. Die Radeon RX 6900 XT kann also auf 80 RAs bei 80 CUs, die Radeon RX 6800 XT auf 72 RAs bei 72 CUs und die Radeon RX 6800 auf 60 RAs bei 60 CUs zurück greifen. Zukünftige kleinere RDNA-2-Grafikkarten werden dieses Schema fortsetzen.
Ein Konkurrent zu DLSS kommt – später
Bei Nvidia sind Raytracing und das „KI-Upsampling“ DLSS mittlerweile feste Partner, kann DLSS seit Version 2.0 den Leistungsverlust durch Raytracing doch teilweise ohne Qualitätsverlust ausgleichen. Zum Start von RDNA 2 bietet AMD keine Konkurrenztechnologie, allerdings befindet sich eine eigene Lösung namens FidelityFX Super Resolution in Entwicklung. Sie soll in Zusammenarbeit mit mehreren Spieleentwicklern entstehen.

Was sich genau hinter FidelityFX Super Resolution versteckt, wie die DLSS-Konkurrenz funktioniert, oder welche Lösung besser ist, ist noch völlig unklar. Dasselbe gilt für ein Erscheinungsdatum. Kurzfristig dürfte AMD das DLSS von Nvidia aber nicht kontern bzw. es überhaupt versuchen.
Auch noch neu: DX12 Ultimate, SAM, AV1 und mehr
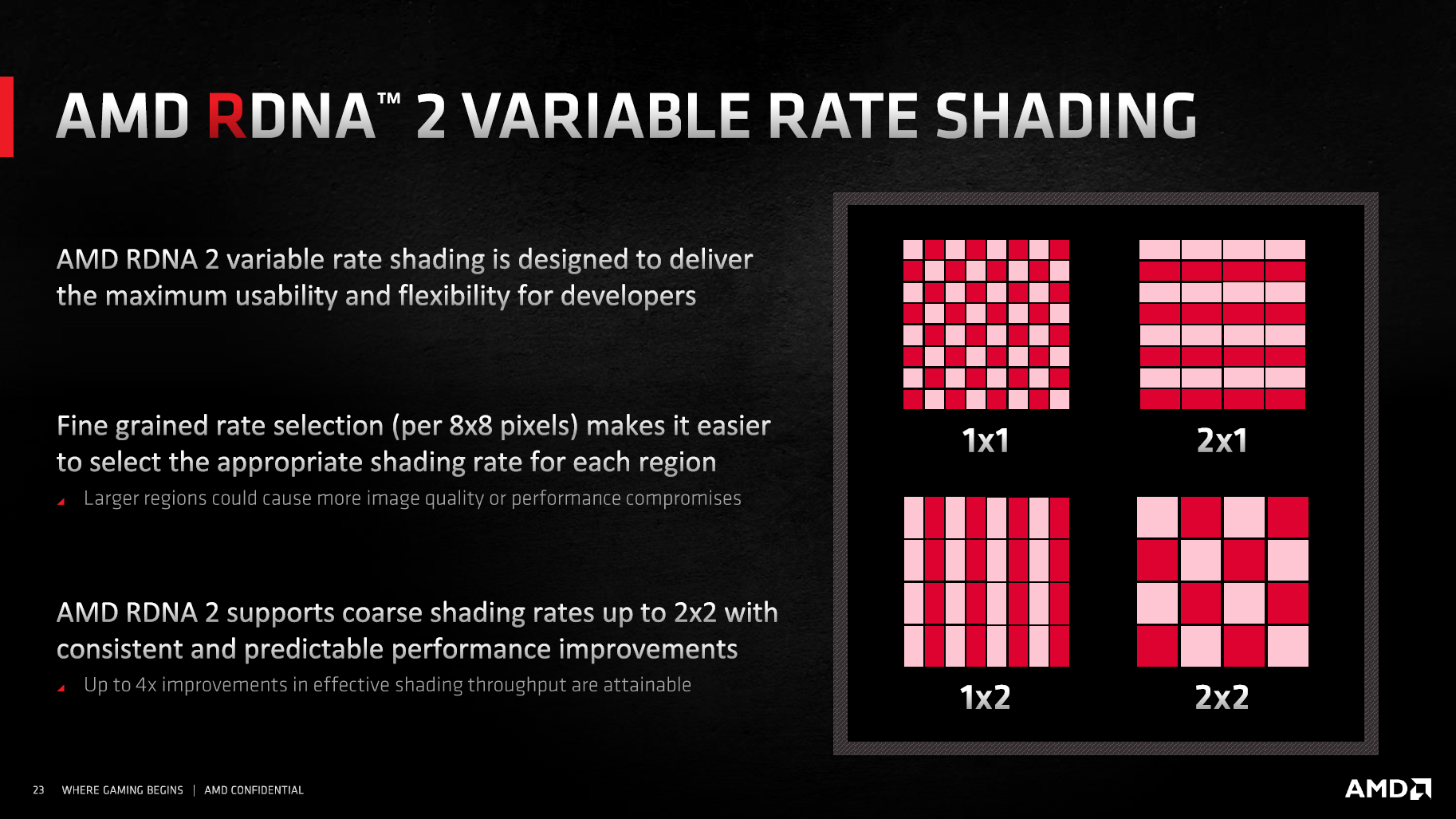
Auch wenn die zuvor genannten die vier wichtigsten Änderungen bei RDNA 2 sind, hat AMD noch zahlreiche weitere Änderungen vorgenommen. So unterstützt RDNA 2 nicht nur Raytracing, sondern das gesamte Feature-Set um DirectX 12 Ultimate: Variable Rate Shading, Mesh Shader und Sampler Feedback sind damit ebenso mit von der Partie. Dasselbe gilt für DirectStorage (bei Nvidia: RTX I/O), wie es auf der Xbox Series X bereits zum Einsatz kommt.
-
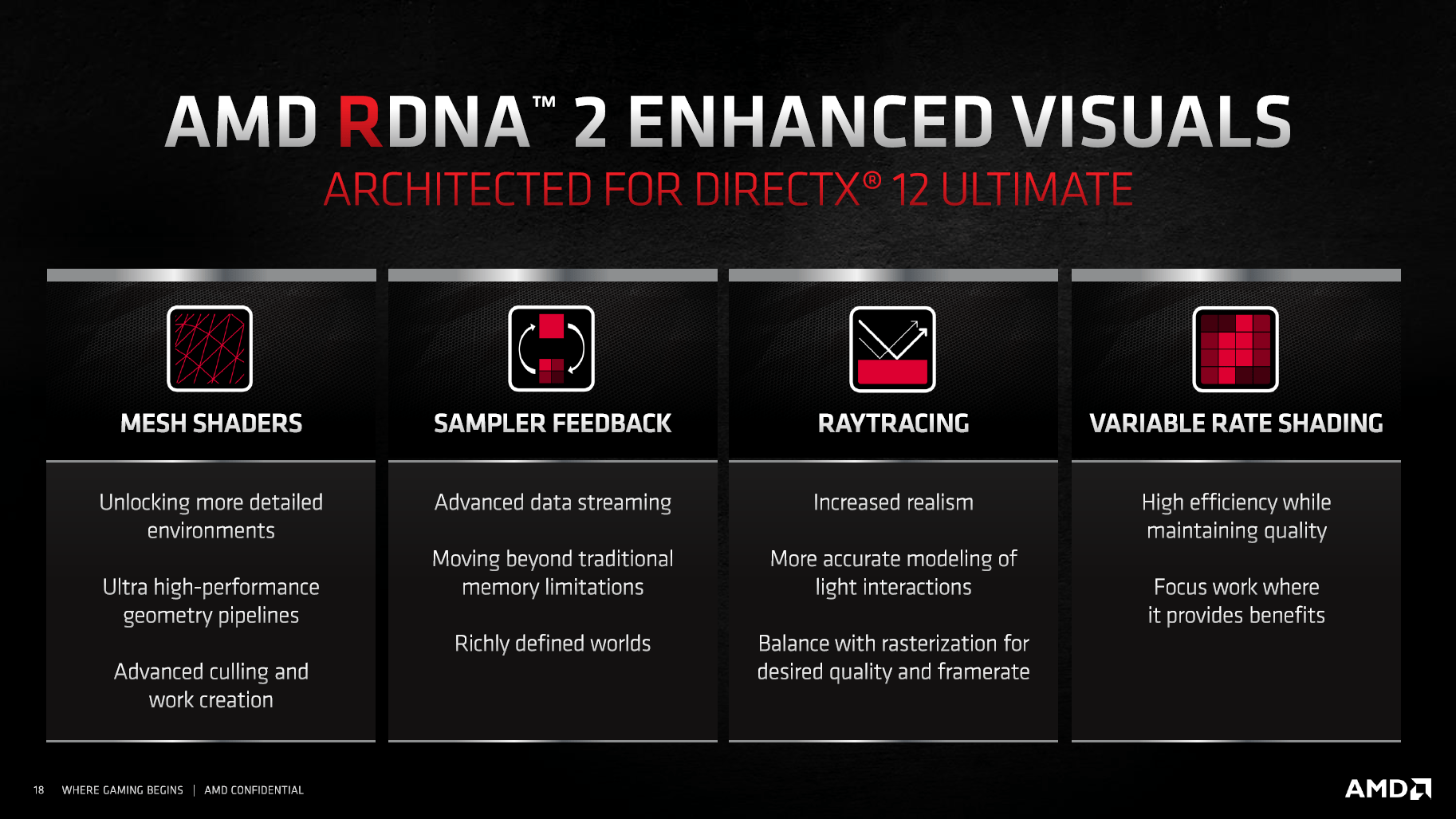 DirectX 12 Ultimate bei RDNA 2 (Bild: AMD)
DirectX 12 Ultimate bei RDNA 2 (Bild: AMD)
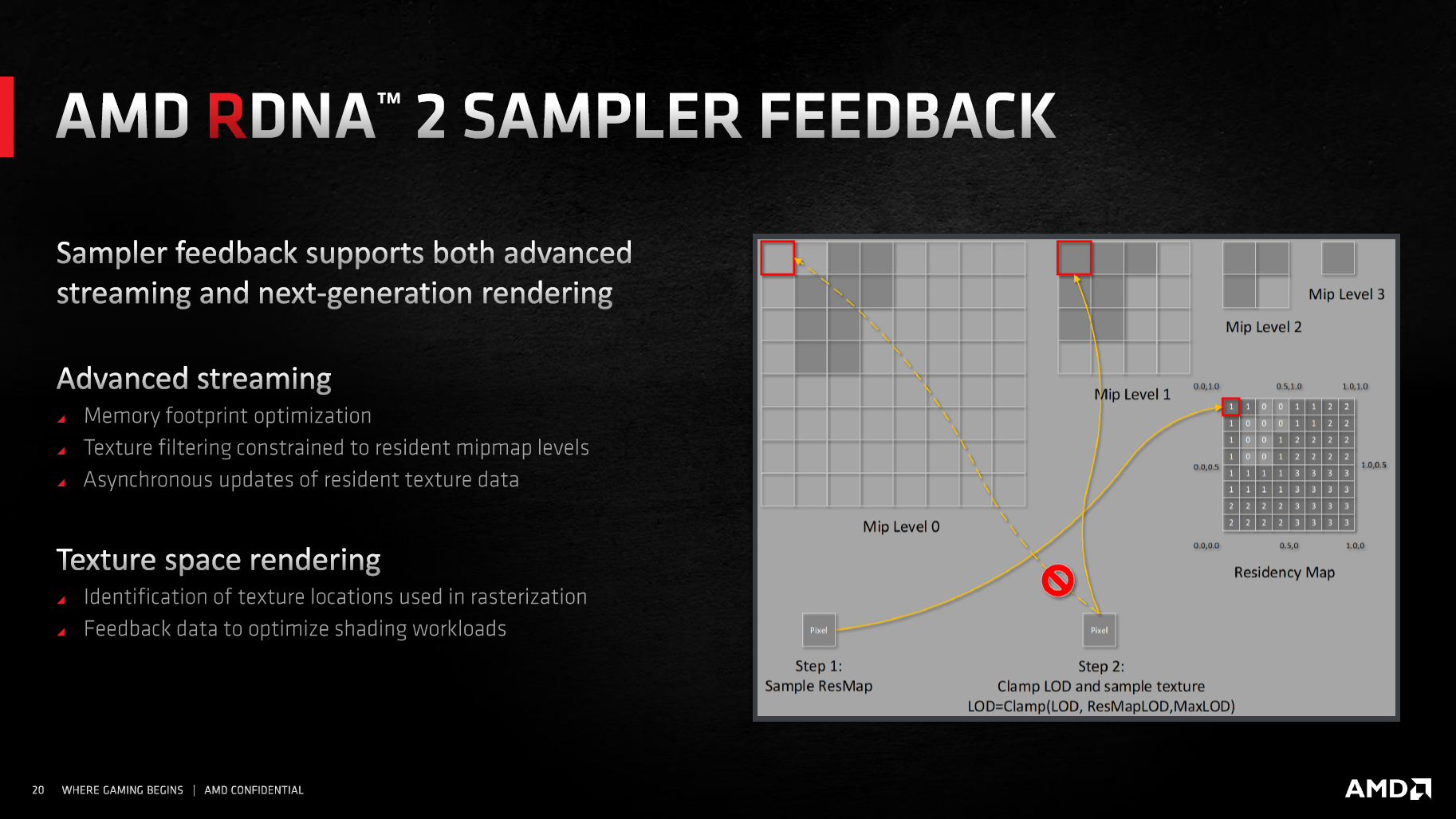
Mit SAM kann die CPU den Grafikspeicher nutzen
Ein weiteres neues Feature von RDNA 2 hört auf die Bezeichnung Smart Access Memory (SAM). Es zielt auf ein besseres Zusammenspiel von CPU und GPU ab.
In einem modernen System kann eine CPU gerade einmal auf 256 MB des schnellen Grafikkartenspeichers zugreifen. AMD macht sich mit SAM nun ein schon länger vorhandenes Feature im PCIe-Protokoll zu Nutze, das sich Resizable Base Address Register (BAR) nennt und mit dem es möglich ist, auch deutlich mehr Speicher zu nutzen, Nvidia hat (als Reaktion) bereits angekündigt, ebenfalls daran zu arbeiten.
-
 AMD SAM auf Ryzen 5000 (Bild: AMD)
AMD SAM auf Ryzen 5000 (Bild: AMD)


AMDs SAM ist eine proprietäre Lösung, die nur auf hauseigener Hardware funktioniert. Neben einem Ryzen-5000-Prozessor wird ein Mainboard mit B550- oder X570-Chipsatz benötigt. Darüber hinaus braucht es ein im UEFI-Modus installiertes 64-Bit-Betriebssystem (Windows 10 oder Linux) und ein kompatibles BIOS mit mindestens AGESA 1.1.0.0. In diesem müssen die Optionen „CSM Support“ abgeschaltet und gleichzeitig „Above 4G Decode“ sowie „Resizable Bar Support“ aktiviert sein. SAM soll laut AMD je nach Spiel einen Leistungszuwachs zwischen 5 und 11 Prozent erbringen. ComputerBase hat auch das getestet.
Neue Videocodecs und HDMI 2.1
Navi 21 unterstützt mit AV1 nach Nvidia Ampere und Intel Xe nun ebenfalls das Decoding des neuesten Video-Codecs, auf den unter anderem YouTube in Zukunft setzen wird. Die neue Videoeinheit kann AV1 bis hinauf zu 8K30 decodieren, 8K60 bleibt damit vorerst exklusiv Ampere vorbehalten.
AV1-Decoding funktioniert bei RDNA 2 nicht nur auf dem Papier, sondern auch schon in der Praxis, wie Tests der Redaktion zeigen. Das Video „Japan in 8K“ lässt sich mit AV1-Codec sowohl in 4K60 als auch 8K30 auf einer Radeon RX 6800XT bei minimaler CPU-Auslastung verlustfrei wiedergeben, „Dropped Frames“ treten nur innerhalb der ersten ein bis zwei Sekunden auf.
-
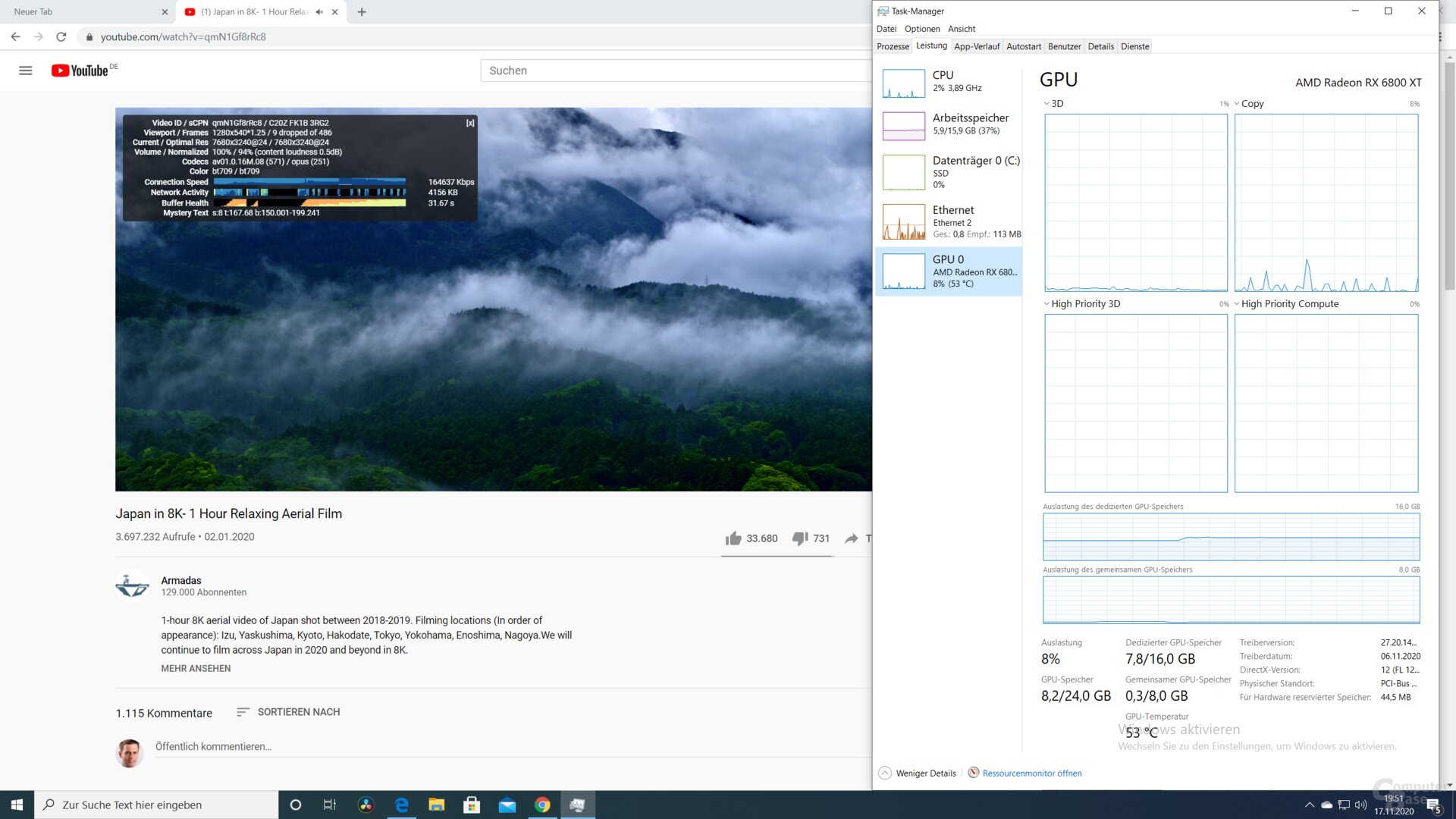 AV1 mit 8K30 wird von RDNA 2 effektiv beschleunigt
AV1 mit 8K30 wird von RDNA 2 effektiv beschleunigt
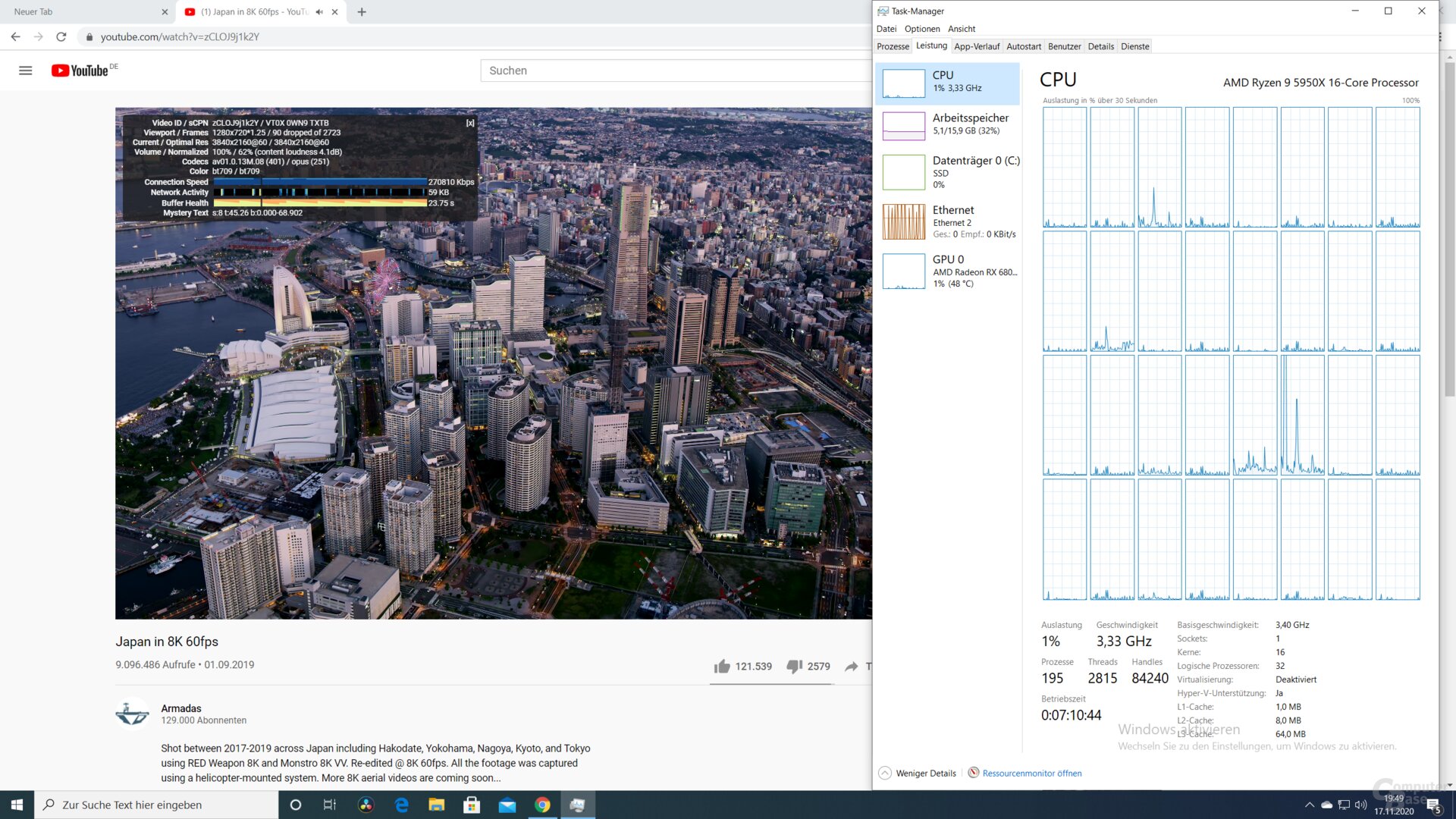
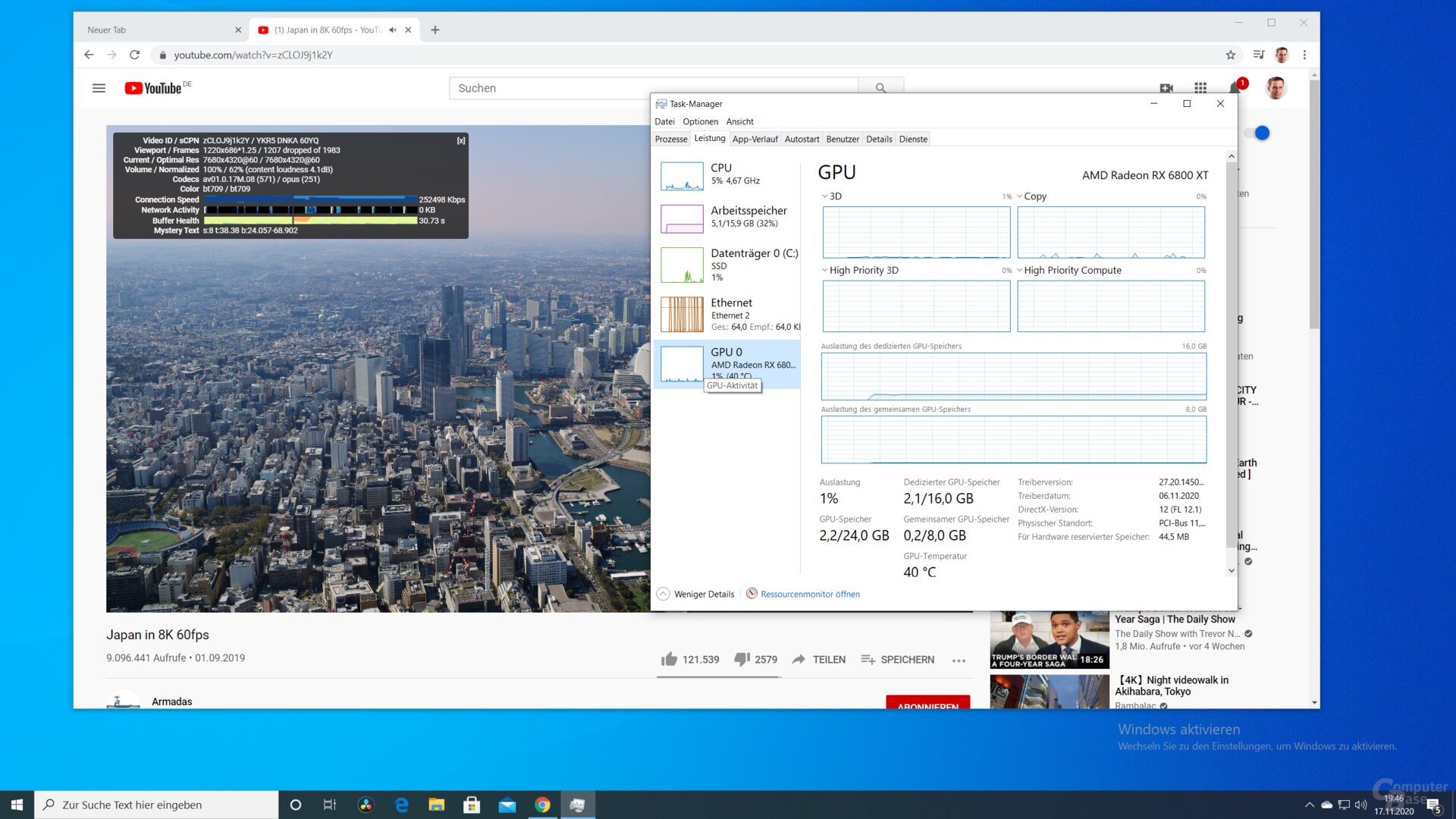
Encodieren wird mit AV1 nicht unterstützt, was auch für VP9 gilt, das mit bis zu 4K90 oder 8K24 decodiert werden kann. H.264 sowie H.265 können auch encodiert werden.
| H.264 | H.265 | VP9 | AV1 | |
|---|---|---|---|---|
| Dekodieren | 1080p600 4K150 |
1080p360 4K90 8K24 |
4K90 8K24 |
8K30 |
| Enkodieren | 1080p360 4K90 |
1080p360 4K60 |
Nicht möglich | |
Navi 21 kann Monitore mittels DisplayPort 1.4 DSC, USB Type-C und nun auch HDMI 2.1 DSC ansteuern. Allerdings hat AMD nur die 40-Gbit-Variante integriert und nicht die maximal mögliche Variante mit 48 Gbit, was in der Praxis jedoch keinerlei Rolle spielen sollte.
FidelityFX ist für Raytracing angepasst
Auch die frei nutzbare Effektbibliothek FidelityFX bekommt mit RDNA 2 eine Aktualisierung. Neben dem – laut AMD geplanten, aber noch nicht fertig entwickelten – DLSS-Konkurrenten „Super Resolution“ wird in Kürze ein Denoiser hinzukommen, den Entwickler beim Einsatz von Raytracing nutzen können. Dieser wird per Compute ausgeführt und soll speziell für RDNA 2 optimiert sein, Nvidia setzt für das Entrauschen hingegen die Tensor-Kerne ein. Auch eine Variante von Variable Rate Shading wird zur Verfügung stehen. Ausgesuchten Entwicklern stehen beide Effekte jetzt schon zur Verfügung, die allgemeine Veröffentlichung soll in Kürze stattfinden.