@beckenrandschwi Multisockel zählt nicht 
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
News AMD Zen 6 CCD: 50 Prozent mehr Kerne auf nahezu gleicher Fläche?
- Ersteller MichaG
- Erstellt am
- Zur News: AMD Zen 6 CCD: 50 Prozent mehr Kerne auf nahezu gleicher Fläche?
beckenrandschwi
Commander
- Registriert
- Aug. 2004
- Beiträge
- 2.283
Durch die Einbuchtungen im Heat Spreader hat AMD die nutzbare Fläche für Dies erheblich beschränkt.stefan92x schrieb:@Alesis Wenn es passen sollte, dann wäre eher 12C+32c zu erwarten, also 88 Threads... Und wenn das gehen sollte, könnte AMD auch gleich 64 Dense-Kerne auf AM5 bringen...
Aber ich glaube nicht wirklich daran, dass das 32-Core CCD auf AM5 passen könnte
Ich würde den Raum innen auf 30 x 30 mm² schätzen.
Es wird nicht reichen, so schlank dass es passen würde kann das IOD gar nicht sein.
Ohne die Einbuchtungen wären es ca 37 x 37 mm² dann hätte es vielleicht gelangt
ThirdLife
Captain
- Registriert
- Aug. 2019
- Beiträge
- 4.069
Acht Threads gepinnt auf die ersten Cores:qiller schrieb:Oh, interessant. Bei dir werden nicht direkt die ersten Cores verwendet, sondern Core 3 und 8 des ersten CCDs. Da scheint Windows o. vlt. auch der Chipsatztreiber was bei der Threadverteilung anders zu machen. Kannst du mal 8 Threads testen und die per Taskmanager Affinity-Pinning auf die ersten 8 CPU-Threads pinnen?
- Registriert
- Dez. 2017
- Beiträge
- 859
Also im Allgemeinen sehe ich eine stimmige Generation.
Ich frag mich nur, wieso AMD „gefühlt“ wenig für den mobilen Markt tun will. Es lässt sich die Verzögerung bzw. mehr Refresh der alten „GPU-Generationen“ als integrierte Grafikkarten schon als Bremse sehen. Die besten Chips in den Laptops sind zu teuer, die guten sind „alt“ / entry-level und Mittelfeld ist „leer“.
Ich werde mit Zen 6 aufrüsten bzw. einen neuen PC aufsetzen. Wünschenswert wären DP2.2, DDR6, alle USB-Anschlüsse als USB4.0 oder besser mit Type C, neuer Bluetooth-Standard, WIFI7-Standard, BTF-Mainboard mit einer bezahlbaren Grafikkarte in RTX -80 oder RX -80 Region.
Also ein stimmiges Paket mit den aktuellsten Standards wäre schön, sodass ich wieder 5-6 Jahre oder mehr mit dem aktuellen Setup fahren kann, wo ich nur die Grafikkarte einmal aufrüsten würde.
Ich frag mich nur, wieso AMD „gefühlt“ wenig für den mobilen Markt tun will. Es lässt sich die Verzögerung bzw. mehr Refresh der alten „GPU-Generationen“ als integrierte Grafikkarten schon als Bremse sehen. Die besten Chips in den Laptops sind zu teuer, die guten sind „alt“ / entry-level und Mittelfeld ist „leer“.
Ich werde mit Zen 6 aufrüsten bzw. einen neuen PC aufsetzen. Wünschenswert wären DP2.2, DDR6, alle USB-Anschlüsse als USB4.0 oder besser mit Type C, neuer Bluetooth-Standard, WIFI7-Standard, BTF-Mainboard mit einer bezahlbaren Grafikkarte in RTX -80 oder RX -80 Region.
Also ein stimmiges Paket mit den aktuellsten Standards wäre schön, sodass ich wieder 5-6 Jahre oder mehr mit dem aktuellen Setup fahren kann, wo ich nur die Grafikkarte einmal aufrüsten würde.
ThirdLife
Captain
- Registriert
- Aug. 2019
- Beiträge
- 4.069
Was für DDR6 bitte ? Sei froh wenn du bis dahin überhaupt noch irgendein DDR5-4800er Modul findest. 🤣Eorzorian schrieb:Ich werde mit Zen 6 aufrüsten bzw. einen neuen PC aufsetzen. Wünschenswert wären DP2.2, DDR6, alle USB-Anschlüsse als USB4.0 oder besser mit Type C, neuer Bluetooth-Standard, WIFI7-Standard, BTF-Mainboard mit einer bezahlbaren Grafikkarte in RTX -80 oder RX -80 Region.
Ich hab nicht nur Zweifel, ich würde kategorisch ausschliessen, dass AMD eine DDR5 + 6 Plattform gemeinsam anbieten wird inmitten der größten Speicherkrise ever.
Alesis
Commander
- Registriert
- Juni 2022
- Beiträge
- 2.821
Nun, AM5 ist Desktop. Welches Segment ist dein Saurier? Ist also kein Vergleich im Bezug auf deine Aussage, warum AMD nur ein 12 Kerne CCD für AMD 5 bringt, also maximal 24 Kerne. Ich verstehe solche Meinungen nicht.beckenrandschwi schrieb:Naja, mein Dionsaurer hat 44c/88T:
Offensichtlich ist ein 12 Kerne CCD das maximale für AM5. Mehr geht nicht für den Sockel, also maximal 24 Kerne.
Vielleicht sollte man einfach nicht immer unterschlagen, mit pauschal 30% über alle Segmente, ist AMD um 70% weit weg von Intel. Im mobilen Bereich ist AMD um 80% weit weg von Intel. Und während man Intel nicht nur mit US Steuergelder gepimpert hat, hat AMD was bekommen?Eorzorian schrieb:Ich frag mich nur, wieso AMD „gefühlt“ wenig für den mobilen Markt tun will.
Nebenbei will man die Fakten auch nicht sehen, AMD geht aktuell auf 2nm Instinct und Venice. Dort wird Geld verdient, Intel ist in diesem Bereich weit weg. AMD muss offensichtlich Prioritäten setzen. Intel konnte es sich erlauben Raptor 13 als Raptor 14 zu verkaufen. Intel kann es sich leisten, Arrow zu verscherbeln.
Weiter wissen wir nicht, wie sich Medusa gestalten wird.
Das steht und fällt mit dem Zen 6 Kern. Das drum herum hilft ein wenig aber was zählt ist der Kern.Eorzorian schrieb:Also im Allgemeinen sehe ich eine stimmige Generation.
Was verstehst Du unter wenig?Eorzorian schrieb:Ich frag mich nur, wieso AMD „gefühlt“ wenig für den mobilen Markt tun will.
Die Gerüchte besagen
- Medusa Halo
- Medusa Halo Mini/Meduse Premium
- Medusa Point 1 + CDD
- Medusa Point 1
- Meduse Point 2
- Meduse Point 3
- Medusa Ridge
Krackan Point 2 fängt im Preisvergleich bei 570 Euro an. Ich gehe davon aus dass Gorgon Point ein bisschen tiefer rutschen sollte, aber bei der aktuelle Geschichte mit DRAM wird wohl nichts daraus werden.Eorzorian schrieb:Es lässt sich die Verzögerung bzw. mehr Refresh der alten „GPU-Generationen“ als integrierte Grafikkarten schon als Bremse sehen. Die besten Chips in den Laptops sind zu teuer, die guten sind „alt“ / entry-level und Mittelfeld ist „leer“.
Notebook SoCs werden am Jahresanfang vorgestellt, weil die neuen Notebooks Ende Q1 bis Q2 vorgestellt werden. Zen 6 kommt zu spät für den Jahrgang 2026. RDNA 5 in Medusa Halo kommt wahrscheinlich zu spät damit Medusa Halo und Medusa Halo Anfang 2027 starten können.
DDR 6 ist kein Thema für Zen 6 und wahrscheinlich auch nicht für Zen 7.Eorzorian schrieb:Ich werde mit Zen 6 aufrüsten bzw. einen neuen PC aufsetzen. Wünschenswert wären DP2.2, DDR6, alle USB-Anschlüsse als USB4.0 oder besser mit Type C, neuer Bluetooth-Standard, WIFI7-Standard, BTF-Mainboard mit einer bezahlbaren Grafikkarte in RTX -80 oder RX -80 Region.
Es gibt keine Anzeichen dass der Standard bald erschein. Bei der Roadmap von SK Hynix wurde DDR6 im Zeitfenster 2029 bis 2031 eingeordnet.
Es gibt genügend Geräte mit USB A, so dass nur noch USB C anzubieten schwierig ist.
AMD hat die Sache mit USB4 verbockt. USB4 von der CPU erfordert neue Boards und das ohne neuen Chipsatz zu verkaufen wird peinlich. Von einem neuen Chipsatz ist nichts zu hören
Zuletzt bearbeitet:
Schraub dir noch eine Kompressorkühlung dran.NerdmitHerz schrieb:Ich hatte weder bei meinem 5950x (ccd0 5.8 Ghz / ccd1 5.7 Ghz), 5800x3d keine Probleme ihn zu kühlen mit Wasserkühlung. Wobei 5950x noch 3x 360mm intern hatte und mein 5800x3d dann den mora 420 bekam. Mein 9950x klammere ich mal aus, da dieser direct-die und besagten mora 420 bekommen.
Wenn mit Wasserkühlung AIO meinst, dann machst iwas falsch. Vor 2 Wochen ein 9800x3d bei wem aus forum verbaut und der wird von einem noctua Luftkühler mit 1x 120mm gekühlt. Absolut machbar.
Somit sollten zukünftige CPUs egal ob AMD oder Intel problemlos zu kühlen sein
Schon... andererseits ist immer die Frage was "verschieden" bei AMD eigentlich bedeutet. Ich erinnere nur daran, dass "Trento" ein eigener Codename war...ETI1120 schrieb:Wenn es nicht Gerüchte/Leaks gäbe, die besagen dass es zwei verschiedene IODs gibt, und das eine Leak nicht durch den richtigen Wert für die DIMMs eine gewisse bestätigung erfähren hätte, wäre ich vollkommen bei Dir.
12 vs 32 klingt nach einem großen Unterschied. Bei den möglichen Taktraten würde ich aber davon ausgehen, dass die 12 Classic Cores aber eher die Leistung von 16-20 Dense Cores bringen würden, damit klingt der Unterschied schon geringer. Wenn man dann noch bedenkt, dass AMD einen Nachfolger für High-Bandwith-Optimierte Anwendungen braucht, dann wird die gleiche Bandbreite plötzlich sinnvoll. 96 Classic Zen 6 Cores mit 3D-Cache auf SP7 (und damit mit 16x MRDIMM-12800) wären ein sinnvoller Nachfolger für den 9V64H und im Gegensatz zu dieser Speziallösung auf SH5 wieder auf der (dann) normalen Plattform nutzbar.ETI1120 schrieb:Also ist die eigentliche Frage, ist es sinnvoll die CCDs mit 12 und mit 32 Kerne mit derselben Bandbreite anzuschließen?
Nochmal die Frage: Wäre das wirklich (deutlich) überdimensioniert? Auf dem Desktop wird nochmal höher getaktet. Sicher wäre die Anbindung dann pro Kern/Takt immer noch schneller als im Dense-Epyc, aber das muss ja nicht schlecht sein.ETI1120 schrieb:Natürlich kann man das Classic CCD was die Anbindung anbelangt auch überdimensionieren. Aber das schleppt AMD auf dem Desktop mit, wo beide CCD sehr viel Shoreline belegen.
Auch eine Option, die der Effizienz gut tun würde. Ebenso könnte AMD im Desktop-IOD auch einfach einen weniger breiten Sea of Wires implementieren und ein paar Cent damit sparen...ETI1120 schrieb:Sinnvoll wäre es nur wenn das Infinity Fabric auf dem Desktop niedriger takten würde.
Das Interface wird eine echte Alternative zu HBM (wie gerade genannt).ETI1120 schrieb:Als ich gestern Mal das ganze mit MRDIMM DDR5-12800 durchgerechner habe ist mir ganz schummrig geworden.
Spannend finde ich die Frage, wie aufwendig es wäre, die gleiche Shoreline für beide CCDs zu erhalten. Und ich vermute, dass die sich relativ natürlich ergibt. So wie es aussieht, ist der Aufbau eines CCD ja:ETI1120 schrieb:Also für mich ergibt es Sinn konsequent zwei Plattformen zu machen
- SP8 mit 8 Speicher-Kanäle, maximal 8 CCDs a 12 x Zen 6 Classic und einem IOD dessen Shoreline für diese Anforderung abgestimmt ist. Die CCDs passen dann ohne Probleme für den Desktop
- SP7 mit 16 Speicher-Kanälen maximal 8 CCDs a 32 x Zen 6 Dense und einem IOD dessen Shoreline auf diese Anforderung abgestimmt ist.
Sea of Wires
Core - Cache - Core
Core - Cache - Core
...
Beim Dense CCD geht das halt deutlich weiter als beim Classic CCD. Jetzt sind die Dense-Cores ja kleiner, sollen aber wohl den gleichen L3-Cache pro Core wie die Classic-Cores, wenn ich mich nicht irre? Dazu müsste man den Cache im Dense-CCD breiter machen, da jeder Core weniger hoch ist. Schmalere Cores, breiterer Cache würde dann ja ganz von allein auf praktisch die gleiche Breite des Die hinauslaufen. Und dann kann man das auch ausnutzen und wirklich austauschbar aufbauen.
SP7 ist aber für manch eine Anwendung auch ein völlig überdimensioniertes Monster. SP8 ist da eine willkommene Ebene darunter für Enterprise-Server und Workstations. Umso faszinierender, dass Intel das Gegenstück für Diamond Rapids gecancelt hat und nur das SP7-Äquivalent bringen willETI1120 schrieb:Die SP8 wird neben SP7 ein bisschen schwächlich.
Oh jaETI1120 schrieb:So wie ich Deine Posts verstehe, siehst Du das genauso.
Piktogramm
Fleet Admiral
- Registriert
- Okt. 2008
- Beiträge
- 10.280
Wenn der IF quer durchs IOD angenommen[1] 512 Adernpaare breit ist, of-Die zu den CCDs aber nur 256, 384 Adernpaare hätte, dann brauchts bei den CCD und dem IOD doch aber Logik + Buffer um die Pakete vom IF zu serialisieren. Das wäre Imho arg deppert, wenn man sich vom Serdes trennen will, dann aber doch wieder (etwas schwächere) Serialisierung auf Paketebene zu betreiben.stefan92x schrieb:Auch eine Option, die der Effizienz gut tun würde. Ebenso könnte AMD im Desktop-IOD auch einfach einen weniger breiten Sea of Wires implementieren und ein paar Cent damit sparen...
Edit: Nachteil wäre dann auch, dass entsprechende Logik bei den CCDs immer raumgreifend wäre, auch auf CCDs die auf anderen Plattformen die volle Anzahl an Kontakten nutzen dürften. Genauso bei den entsprechenden IP-Blöcken vom IOD. Da wäre Recycling bei IODs im Vollausbau entweder Platzverschwendung oder bedeutet Aufwand für Modifikationen/Revaldidierung.
[1] zu faul zum Nachschauen, genaue Werte sind eh irrelevant bei der Überlegung.
Zuletzt bearbeitet:
@Piktogramm tatsächlich hatte ich eher so gedacht: AMD kann zwei IF-Links zwischen CCD und IOD ermöglichen, und beim Customer eventuell einfach nur einen der beiden Links nutzen. Da hätte man keine Serialisierung, man würde einfach nur über zwei parallele Links sprechen (oder eben nur einen). Da man keine SerDes mehr braucht, ist der Platzbedarf auf dem CCD auch recht überschaubar.
Und jetzt kommts: Selbst mit SerDes hat AMD genau das schon gemacht, zwei Links im CCD verbaut und je nach Modell beide genutzt oder nur einen:
https://www.servethehome.com/wp-con...YC-9004-Genoa-Chiplet-Architecture-4x-CCD.jpg
https://www.servethehome.com/wp-con...C-9004-Genoa-Chiplet-Architecture-12x-CCD.jpg
Ein solches Vorgehen wäre für AMD also gar nicht neu.
Und jetzt kommts: Selbst mit SerDes hat AMD genau das schon gemacht, zwei Links im CCD verbaut und je nach Modell beide genutzt oder nur einen:
https://www.servethehome.com/wp-con...YC-9004-Genoa-Chiplet-Architecture-4x-CCD.jpg
https://www.servethehome.com/wp-con...C-9004-Genoa-Chiplet-Architecture-12x-CCD.jpg
Ein solches Vorgehen wäre für AMD also gar nicht neu.
Die Rede ist nicht von verschiedenen Codenamen sondern von verschiedenen Spezifikationen.stefan92x schrieb:Schon... andererseits ist immer die Frage was "verschieden" bei AMD eigentlich bedeutet. Ich erinnere nur daran, dass "Trento" ein eigener Codename war...
Natürlich kann AMD ein IOD machen und bei SP7 nur ein Teil der PCIe Lanes verwenden.
Bei den Servern wo es auf die Bandbreite ankommt?stefan92x schrieb:12 vs 32 klingt nach einem großen Unterschied. Bei den möglichen Taktraten würde ich aber davon ausgehen, dass die 12 Classic Cores aber eher die Leistung von 16-20 Dense Cores bringen würden,
Welche Taktfrequenzen erreichen da die classic Cores? Erwarten wir nicht 4 GHz oder ein bisschen mehr bei den Dense kerne. Und die Performance vs Power Kurve wird über 4 GHz immer flacher ...
Ich würde sagen wenn man die Performance berücksichtigt ist es eher dass 12 Performance Cores die Leistung von 16 dense Cores im Server bringen. Bei Servern mit weniger Kernen steigt das Verhältnis zugunsten der Classic Cores aber die haben dann ja auch je Core mehr Bandbreite zur Verfügung.
stefan92x schrieb:damit klingt der Unterschied schon geringer. Wenn man dann noch bedenkt, dass AMD einen Nachfolger für High-Bandwith-Optimierte Anwendungen braucht, dann wird die gleiche Bandbreite plötzlich sinnvoll.
Du weißt wie AMD die Dense Kerne auch noch nennt? --- through put cores
Bei den Anwendungen auf dem Desktop kommt es nicht so sehr auf Bandbreite an. Sonst hätte sich AM4 gar nicht so lange halten können. Und es hätte gar nicht das Gejammere gegeben, warum es kein Zen 4 für AM4 gäbe.stefan92x schrieb:Nochmal die Frage: Wäre das wirklich (deutlich) überdimensioniert? Auf dem Desktop wird nochmal höher getaktet. Sicher wäre die Anbindung dann pro Kern/Takt immer noch schneller als im Dense-Epyc, aber das muss ja nicht schlecht sein.
Und wie sieht die Rechnung bei einem 2 CCD Ryzen mit 2 Kanälen CUDIMM gegen die Server mit MRDIMM DDR5-12800 aus?
stefan92x schrieb:Auch eine Option, die der Effizienz gut tun würde. Ebenso könnte AMD im Desktop-IOD auch einfach einen weniger breiten Sea of Wires implementieren und ein paar Cent damit sparen...
Effizienz im Desktop ist nicht von Belang. Das sieht man ganz einfach dass die CPU Kerne am ineffizientesten Punkt der Performance-Power Kurve betrieben werden.
Man spart keine Cents wenn man Dinge die man nicht braucht nicht implementiert.
HBM und DIMMs sind andere Welten. Jeweils andere Anforderungen.stefan92x schrieb:Das Interface wird eine echte Alternative zu HBM (wie gerade genannt).
Wer verbaut bei Data Center Lösungen nur einen HBM Stack?
Die Bandbreite bei den Servern macht einen gewaltigen Satz nach oben.
Und diese Bandbreite muss man auch im IOD und in den CCDs bewältigen. Das war übrigens der grund warum mir schummrig wurde.
Wenn man den Sicherheitszuschlag von Zen 2 auf den Faktor 2 reduziert kommt man bei SP7 auf 400 GB/s für die Anbindung eines CCD und bei SP8 auf 200 GB/s. Ist das realistisch bzw. realisierbar? Die Taktfrequnz des Infinity Fabrics hochzuziehen treibt die Power.
Aus den Seitenverhältnissen auf den Fotos ist klar, dass beim Dense CCD die Kerne in 8 x 4 angeordnet sind.stefan92x schrieb:Spannend finde ich die Frage, wie aufwendig es wäre, die gleiche Shoreline für beide CCDs zu erhalten. Und ich vermute, dass die sich relativ natürlich ergibt. So wie es aussieht, ist der Aufbau eines CCD ja:
Sea of Wires
Core - Cache - Core
Core - Cache - Core
...
Die Säulen aus Cache werden bei beiden gleich breit sein, die Kerne sind unterschiedlich groß.
Man kann sich viel vorstellen, aber es ist kein Puzzle bei dem die einzelnen Teile beliebig zugeschnitzten werden können. Es spielen beim Layout viele Faktoren rein.stefan92x schrieb:Beim Dense CCD geht das halt deutlich weiter als beim Classic CCD. Jetzt sind die Dense-Cores ja kleiner, sollen aber wohl den gleichen L3-Cache pro Core wie die Classic-Cores, wenn ich mich nicht irre? Dazu müsste man den Cache im Dense-CCD breiter machen, da jeder Core weniger hoch ist. Schmalere Cores, breiterer Cache würde dann ja ganz von allein auf praktisch die gleiche Breite des Die hinauslaufen. Und dann kann man das auch ausnutzen und wirklich austauschbar aufbauen.
Bisher war es unproblematisch beide Typen von CCDs an denselben IOD anzuschließen. Aber die Verbindungen für 18 PCIe Lanes zu layouten ist einfacher als die Verbindungen eines 256 bit breiten bidirektionalen Busses. Wobei die Frage ist, ob es wirklich bei 256 bit bleibt. Werden es 2 x 256 beim Classic und 4 x 256 beim Dense oder geht die Busbreite nach oben, 384bit 512bit ? Die neueste generation des Faunouts von TSMC kann 2200 Lines per mm.
Die Frage ist, ob die ganzen Klimmzüge die notwendig sind, um dieselbe Shoreline zu erreichen es wirklich wert sind.
Hast Du Dir einmal überlegt wie der IOD innen aufgebaut sein muss um die 1600 GB/s auf die CCDs zu verteilen? Wie breit war bisher Inifinity Fabric im Server IOD? wie breit muss es für SP7 werden?
Also ich bin gerne bereit zu glauben, dass AMD zwei IODs macht. einen um die 800 GB/s Speicher-Bandbreite bewältigen zu können und einen um die 1600 GB/s Speicher-Bandbreite bewältigen zu können. Und über den IOD greifen die CCDs auch noch auf die PCIe Lanes zu.
Aus meiner Sicht gibt es genügend Argumente für beide Seiten:
Derselbe IOD bei SP7 und SP8 vs jeweils eigene IODs für SP7 und SP8
Aber man muss berücksichtigen dass der Wechsel von 18 PCIe Lanes zu Sea of Wires die Anzahl der notwenigen Verbindungen zwischen den Dies massiv erhöht und dies erhebliche Auswirkungen auf das Design der Chips hat.
Der Punkt ist doch ganz einfach der. In den Rechenzentren muss Platz geschaffen werden und da kommen die Monster gerade recht.stefan92x schrieb:SP7 ist aber für manch eine Anwendung auch ein völlig überdimensioniertes Monster. SP8 ist da eine willkommene Ebene darunter für Enterprise-Server und Workstations. Umso faszinierender, dass Intel das Gegenstück für Diamond Rapids gecancelt hat und nur das SP7-Äquivalent bringen will
So wie ich es mitbekomme gibt es bei vielen Unternehmen die bisher ihre Server lokal hatten, eine Überlegung ihre Server hosten zu lassen. Und dann sind wir auch danicht mehr im Serverraum eines kleinen Unternehmens sondern im Rechenzentrum wo man alles möglich dicht packen will.
Wie wir es ja (noch viel drastischer beschnitten) auch bei SP5/SP6 sehen.ETI1120 schrieb:Natürlich kann AMD ein IOD machen und bei SP7 nur ein Teil der PCIe Lanes verwenden.
Und dennoch gibt es Anwendungen, die von mehr Bandbreite pro Kern noch deutlich profitieren können. Nicht viele, aber es gibt sie (wie gesagt, ich rechne so halb damit, dass die Variante mit Classic Cores auf SP7 Venice-X sein wird)ETI1120 schrieb:Du weißt wie AMD die Dense Kerne auch noch nennt? --- through put cores
Vielleicht besser anders formuliert: Wenn man nur die Hälfte der Shoreline des CCD nutzt, kann der IOD schmaler als zwei CCD sein (so wie es ja aktuell bei Ryzen auch ist), statt die gleiche Breite haben zu müssen. Würde übrigens auch ganz elegant ermöglichen, einen zukünftigen Halo-Chip mit mehr Speicherkanälen auch breiter an die CCDs anzubinden (angenommen, dass der Halo IOD eben größer wäre, wenn er wieder die GPU enthält).ETI1120 schrieb:Man spart keine Cents wenn man Dinge die man nicht braucht nicht implementiert.
3x4 könnte es dann für Classic sein.ETI1120 schrieb:Aus den Seitenverhältnissen auf den Fotos ist klar, dass beim Dense CCD die Kerne in 8 x 4 angeordnet sind.
Ich komm bei unterschiedlich großen Kernen einfach nicht auf die gleiche Breite für den Cache?ETI1120 schrieb:Die Säulen aus Cache werden bei beiden gleich breit sein, die Kerne sind unterschiedlich groß.
Beliebig nicht. Aber gerade weil der Aufwand so groß ist, kann es durchaus sinnvoll sein, nach kompatiblen Lösungen zu schauen, um manchen Aufwand nur einmal zu haben.ETI1120 schrieb:Man kann sich viel vorstellen, aber es ist kein Puzzle bei dem die einzelnen Teile beliebig zugeschnitzten werden können
Oder vorher eben die Frage: Wie viele Klimmzüge sind es überhaupt?ETI1120 schrieb:Die Frage ist, ob die ganzen Klimmzüge die notwendig sind, um dieselbe Shoreline zu erreichen es wirklich wert sind.
Nicht im Detail. Aber es verwundert mich nicht, dass der IOD so verdammt groß wird, wenn ich daran denke.ETI1120 schrieb:Hast Du Dir einmal überlegt wie der IOD innen aufgebaut sein muss um die 1600 GB/s auf die CCDs zu verteilen?
Da stimme ich dir zu. Gerade das macht es ja so spannendETI1120 schrieb:Aus meiner Sicht gibt es genügend Argumente für beide Seiten:
Derselbe IOD bei SP7 und SP8 vs jeweils eigene IODs für SP7 und SP8
Wenn man sich die Die-Shots von Strix Halo anschaut, scheint das gar nicht mal so drastisch zu sein. Anders natürlich schon (gerade wenn man nicht mehr den SerDes-Block im Layout berücksichtigen muss, könnten auch größere Unterschiede auftauchen).ETI1120 schrieb:Aber man muss berücksichtigen dass der Wechsel von 18 PCIe Lanes zu Sea of Wires die Anzahl der notwenigen Verbindungen zwischen den Dies massiv erhöht und dies erhebliche Auswirkungen auf das Design der Chips hat.
Klar, für Hyperscaler und sonstige große RZ sind die interessant, solange nach Cores abgerechnet wird. Wer kleiner ist, will aber allein schon aus Redundanzgründen nicht unbedingt die Monster haben. SP8 scheint auch keine Einschränkungen beim PCIe zu haben und somit für alles andere interessant zu werden - Storage Systeme, Systeme mit vielen Beschleunigern (solange die RAM-Bandbreite dafür ok ist) etc. Und natürlich dann auch noch das Thema Workstation, für das SP8 auch deutlich besser geeignet wirkt.ETI1120 schrieb:Der Punkt ist doch ganz einfach der. In den Rechenzentren muss Platz geschaffen werden und da kommen die Monster gerade recht.
Das sind alles Märkte (vielleicht bis auf Workstations), in denen Intel immer noch ziemlich gut aufgestellt ist, und die Intel mit Diamond Rapids aufgibt. So wie AMD mit der RDNA3.5 iGPU dieses Jahr eine offene Flanke für Panther Lake setzt, so öffnet Intel mit der Entscheidung gegen Diamond Rapids-SP Tür und Tor für AMDs SP8-Plattform.
Piktogramm
Fleet Admiral
- Registriert
- Okt. 2008
- Beiträge
- 10.280
Wenn ich es richtig verstanden habe, ist doch beim "Sea of Wires" der Gag, dass der IF direkt zum CCD durchgeschliffen wird. Da die Anzahl die Adernpaare zu reduzieren bedingt, dass das Durchschleifen nicht mehr funktioniert. Die IF Endpoints könnten nicht mehr auf dem CCD liegen, sondern müssten wieder in das IOD zurück und Pakete serialisiert werden, dann wäre das arg sinnlos. Da würde vom bisherhigem SERDES-Block vor allem die PHY wegfallen, aber recht viel der Logik weiterhin notwendig sein.stefan92x schrieb:@Piktogramm tatsächlich hatte ich eher so gedacht: AMD kann zwei IF-Links zwischen CCD und IOD ermöglichen, und beim Customer eventuell einfach nur einen der beiden Links nutzen. Da hätte man keine Serialisierung, man würde einfach nur über zwei parallele Links sprechen (oder eben nur einen). Da man keine SerDes mehr braucht, ist der Platzbedarf auf dem CCD auch recht überschaubar.
[...]
Und bei sowas wie IF einfach mal "Adernpaare" streichen halte ich für unrealistisch. Zudem AMD bisher eher Bandbreite über die Menge an IF-Endpoints ja Block skaliert (suche: "endpoint"): https://old.chipsandcheese.com/2025/10/31/37437/
Ein Endpoint hat 64B oder halt 512 Adernpaare + Fehlerkorrektur.
Der Gag ist, dass die Verbindung ohne zusätzliche PHYs/SerDes erfolgen kann.Piktogramm schrieb:Wenn ich es richtig verstanden habe, ist doch beim "Sea of Wires" der Gag, dass der IF direkt zum CCD durchgeschliffen wird.
Ich schlage ja nicht vor, die Adernpaare für einen Link zu reduzieren, sondern die Anzahl der Links. CCDs mit zwei Links, von denen einer nur optional verbunden wird, hat AMD eben schon gebaut.Piktogramm schrieb:Da die Anzahl die Adernpaare zu reduzieren bedingt, dass das Durchschleifen nicht mehr funktioniert.
Aber wie gesagt einen PCIe Bus durchs Package zu führen ist etwas anderes als ein Sea of Wires.stefan92x schrieb:Und jetzt kommts: Selbst mit SerDes hat AMD genau das schon gemacht, zwei Links im CCD verbaut und je nach Modell beide genutzt oder nur einen:
https://www.servethehome.com/wp-con...YC-9004-Genoa-Chiplet-Architecture-4x-CCD.jpg
https://www.servethehome.com/wp-con...C-9004-Genoa-Chiplet-Architecture-12x-CCD.jpg
Ein solches Vorgehen wäre für AMD also gar nicht neu.
Für den Sea of Wires hat AMD die Anzahl der Chiplets reduziert und deren Größe deutlich erhöht.
AFAIU gibt es keine IF Endpoints. Sowohl die CCDs als auch die IODs haben ein eigenes Infinity Fabric. Die Infinity Fabric Links zwischen den Dies Koppeln die Infinity Fabrics der jeweiligen Dies.Piktogramm schrieb:Die IF Endpoints könnten nicht mehr auf dem CCD liegen, sondern müssten wieder in das IOD zurück und Pakete serialisiert werden, dann wäre das arg sinnlos.
Beim Zen 3 CCD hatte AMD einen doppelten Ringbus also müssen die Leitungen des Infinity Fabric Links vom IOD mit beiden Ringbussen verschaltet werden.
Aus der Präsentation von Zen 2 kann man schließen, dass auch das Zen 2 IOD einen doppelte Ringbus hatte.
IIRC hat AMD die Anschlüsse an den Infinty Fabric Ports genannt.
Die SERDES waren eine zusätzliche Komplikation die hinter dem Infinty Fabric Port liegen, vom Ringbus ausgeseen. Die Ports selbst haben wegen der breite des Busses ihre eigene Komplexität.Piktogramm schrieb:Da würde vom bisherhigem SERDES-Block vor allem die PHY wegfallen, aber recht viel der Logik weiterhin notwendig sein.
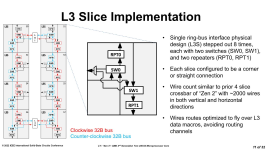
Was eben unklar ist wie sich die Topologie des Infinity Fabric in den CCDs entwickelt. bei 12 Kernen wird es AFAIU mit einem doppelten Ringbus nicht mehr geben. Bei 32 Kernen schon gar nicht.
Auf der anderen Seite kann ich mir nicht vorstellen wie es mit einem 256 bit breiten Bus im IOD funktionieren soll.
Anhänge
Piktogramm
Fleet Admiral
- Registriert
- Okt. 2008
- Beiträge
- 10.280
@stefan92x
https://old.chipsandcheese.com/2025/10/31/37437/
Nochmal nachgeschaut. GMI mit 32B/clk scheint es zu geben und bei Strix Halo in Richtung CCD verbaut zu sein mit ~60GB/s Bandbreite bei 2GHz IF(?). Die iGPU von Strix Halo hat GMI mit 64B/clk wie auch die CCDs der größeren Plattformen.
Ok, 32B/clk GMI für die CCDs fürs Pro-/Consumerkram scheint realistisch.
Wobei mir die Bandbreiten (~60GB/s) für CCDs mit zukünftig 12Kernen etwas wenig erscheint.
@ETI1120
Ich habe die Bezeichnungen von Chips and Cheese übernommen, damit klar wird worauf ich mich beziehe.
So richtig verständlich ist mir das mit dem IF nicht. Wenn bei StrixHalo die IGPU einfach mal 8 Ports haben kann, dann kann da intern nicht nur ein geduplexter Ringbus a 64B/clk liegen. So ein Ringbus bekommt ja nicht mehr Bandbreite, nur weil mehr Ports dranhängen. Mindestens bei StrixHalo, intern muss das Ding nochmals anders aufgebaut sein.
https://old.chipsandcheese.com/2025/10/31/37437/
Nochmal nachgeschaut. GMI mit 32B/clk scheint es zu geben und bei Strix Halo in Richtung CCD verbaut zu sein mit ~60GB/s Bandbreite bei 2GHz IF(?). Die iGPU von Strix Halo hat GMI mit 64B/clk wie auch die CCDs der größeren Plattformen.
Ok, 32B/clk GMI für die CCDs fürs Pro-/Consumerkram scheint realistisch.
Wobei mir die Bandbreiten (~60GB/s) für CCDs mit zukünftig 12Kernen etwas wenig erscheint.
@ETI1120
Ich habe die Bezeichnungen von Chips and Cheese übernommen, damit klar wird worauf ich mich beziehe.
So richtig verständlich ist mir das mit dem IF nicht. Wenn bei StrixHalo die IGPU einfach mal 8 Ports haben kann, dann kann da intern nicht nur ein geduplexter Ringbus a 64B/clk liegen. So ein Ringbus bekommt ja nicht mehr Bandbreite, nur weil mehr Ports dranhängen. Mindestens bei StrixHalo, intern muss das Ding nochmals anders aufgebaut sein.
Faust2011 schrieb:Wenn ich mir noch was wünschen dürfte von AMD, dann wäre es den Idle-Verbrauch zu senken. Aber das geht wohl wg. der Chiplet-Architektur nicht - oder doch? 🤔
wie weit soll der denn runter?
Ähnliche Themen
- Antworten
- 51
- Aufrufe
- 6.415



