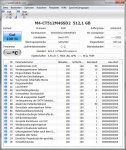
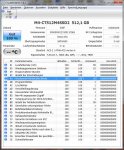
Hallo,
Ich verwende seit ende Juni eine Crucial M4 512GB SSD, 000F Firmware (Betriebsstunden laut Crystal Disk Info ca. 448) und war bis heute morgen sehr zufrieden damit. Von den 512GB sind noch in etwa 90 GB frei. Die Schreibzugriffe sind bei mir sicher etwas über dem durchschnittliche User da ich VMWare Maschinen verwende aber selten mit Ruhezustand oder ähnlichen Schreibintensiven Operationen.
Heute konnten dann plötzlich verschiedene Dateien nicht mehr gelesen werden (Systemdateien und andere; manche davon habe ich sicher schon einige Zeit nicht mehr geöffnet gehabt). c't Desinfect habe ich ausgeführt aber ohne Virusmeldung.
Im Moment lasse ich mal chkdsk über die SSD laufen was allerdings wegen einiger VMWare Disks ziemlich lange dauert da diese bis zu 100GB groß sind (bzw. habe ich den Eindruck das chkdsk bereits hängt; mal schauen ob sich in den nächsten Stunden was tut).
(bzw. habe ich den Eindruck das chkdsk bereits hängt; mal schauen ob sich in den nächsten Stunden was tut).
Wie kann es zu so einem Fehler kommen? Kann es sein, dass ein Speicherbaustein mit Daten defekt wurde? Und, würdet Ihr die SSD zum Händler zwecks Austausch zurückschicken?
Grüße
Ich verwende seit ende Juni eine Crucial M4 512GB SSD, 000F Firmware (Betriebsstunden laut Crystal Disk Info ca. 448) und war bis heute morgen sehr zufrieden damit. Von den 512GB sind noch in etwa 90 GB frei. Die Schreibzugriffe sind bei mir sicher etwas über dem durchschnittliche User da ich VMWare Maschinen verwende aber selten mit Ruhezustand oder ähnlichen Schreibintensiven Operationen.
Heute konnten dann plötzlich verschiedene Dateien nicht mehr gelesen werden (Systemdateien und andere; manche davon habe ich sicher schon einige Zeit nicht mehr geöffnet gehabt). c't Desinfect habe ich ausgeführt aber ohne Virusmeldung.
Im Moment lasse ich mal chkdsk über die SSD laufen was allerdings wegen einiger VMWare Disks ziemlich lange dauert da diese bis zu 100GB groß sind
Wie kann es zu so einem Fehler kommen? Kann es sein, dass ein Speicherbaustein mit Daten defekt wurde? Und, würdet Ihr die SSD zum Händler zwecks Austausch zurückschicken?
Grüße