Gewitter
Lt. Commander
- Registriert
- Nov. 2007
- Beiträge
- 1.323
Hallo,
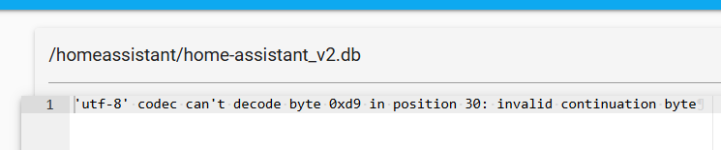
IIn den letzten Wochen hab ich mir ein kleines Smart Home zusammengebaut und soweit funktioniert alles ganz gut, allerdings kommt es immer wieder vor, dass mein Home Assistant Server (Intel NUC) neuerdings abstürzt. Nach mehreren Tagen testen verschiedenster Varianten, scheint es mir so, dass der alte Router TP-Link Archer C6 v2 überlastet sein dürfte. Einerseits ist der Prozessor im Router stets über 90% auch wenn nix passiert, andererseits crasht das System vorwiegend, wenn noch weitere Geräte hinzugefügt werden, wie zB zwei neue Switchbot Geräte.
Die Neustarts vom HA-Server kommen auch meist unerwartet, oftmals Stundenlang alles stabil, wenn ich gar nix mach auch Tagelang. Findet Aktivität statt, kommts teilweise zu Crashes im 10min Takt.
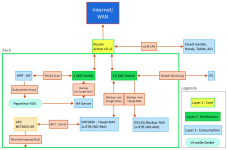
Ich hab mal grob mein Netzwerk skizziert - Im Anhang
Smart Geräte sind 9 Tuya W-LAN Steckdosen.
Seit ich eine weitere Switchbot W-LAN Steckdose und LED Stripe im Home Assistant eingebunden habe, begannen die Probleme.
Gigabit Switch ist der TP-Link TL-SG108
2,5GbE ist der Cudy HS105
Nun ist meine Frage, ob der einerseits Router tatsächlich mit dem Setup überfordert sein könnte und die HA-Server Abstürze zu verantworten hat, laut Google Suche ja, andererseits welcher Router empfehlenswert wäre, bzw auch noch Spielraum für weitere Geräte lässt?
Beim Thema Router weiß ich leider nur von dem was ich gelesen habe, dass Fritz eine gute Marke ist, aber welches Modell ist für diesen Anwendungsfall empfehlenswert?
Danke für die Hilfe schon im Voraus.
IIn den letzten Wochen hab ich mir ein kleines Smart Home zusammengebaut und soweit funktioniert alles ganz gut, allerdings kommt es immer wieder vor, dass mein Home Assistant Server (Intel NUC) neuerdings abstürzt. Nach mehreren Tagen testen verschiedenster Varianten, scheint es mir so, dass der alte Router TP-Link Archer C6 v2 überlastet sein dürfte. Einerseits ist der Prozessor im Router stets über 90% auch wenn nix passiert, andererseits crasht das System vorwiegend, wenn noch weitere Geräte hinzugefügt werden, wie zB zwei neue Switchbot Geräte.
Die Neustarts vom HA-Server kommen auch meist unerwartet, oftmals Stundenlang alles stabil, wenn ich gar nix mach auch Tagelang. Findet Aktivität statt, kommts teilweise zu Crashes im 10min Takt.
Ich hab mal grob mein Netzwerk skizziert - Im Anhang
Smart Geräte sind 9 Tuya W-LAN Steckdosen.
Seit ich eine weitere Switchbot W-LAN Steckdose und LED Stripe im Home Assistant eingebunden habe, begannen die Probleme.
Gigabit Switch ist der TP-Link TL-SG108
2,5GbE ist der Cudy HS105
Nun ist meine Frage, ob der einerseits Router tatsächlich mit dem Setup überfordert sein könnte und die HA-Server Abstürze zu verantworten hat, laut Google Suche ja, andererseits welcher Router empfehlenswert wäre, bzw auch noch Spielraum für weitere Geräte lässt?
Beim Thema Router weiß ich leider nur von dem was ich gelesen habe, dass Fritz eine gute Marke ist, aber welches Modell ist für diesen Anwendungsfall empfehlenswert?
Danke für die Hilfe schon im Voraus.