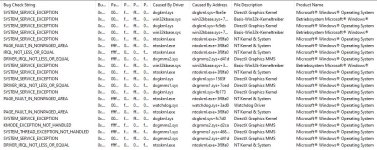
TLDR: Wird vermutlich ein Treiberproblem sein.
Du hast ja eingangs schon richtig erkannt, dass viele Bugchecks in DirectX Modulen ausgelöst werden. Einige davon, von denen wir keine Dumps haben, sind quasi faulty-driver-only Bugchecks (
IRQL_NOT_LESS_OR_EQUAL,
DRIVER_IRQL_NOT_LESS_OR_EQUAL). Deine CPU und der Chipsatz sind von 2008, das Bios von 2010 und die neuesten Treiber von 2016, da kann es schon sein, dass beim Verwenden der aktuellen Windows 10 Version Probleme entstehen.
Weiß nicht wirklich, was man da überhaupt empfehlen könnte. Windows einmal komplett neu installieren ist eine Option, ich wäre aber nicht überrascht, falls deine Probleme dadurch nicht verschwinden.
RAM ist gut möglich, halte ich aber für bisschen unwahrscheinlicher als ein Treiberproblem. Genauso wie Netzteil, das würde sich durch andere Bugchecks und Symptomatik äußern. Memtest einmal durchlaufen zu lassen ist aber nie verkehrt und ein trotzdem ein guter Tipp.
Standardtipps wie
Chkdsk /f /r und
sfc /scannow kannst du auch mal versuchen.
Ich würde an deiner Stelle mal in ein Linux booten und eine Zeit lang verwenden. Die Bluescreens bekommst du ja anscheinend im Stundentakt, sollte also wirklich ein Hardwarefehler vorliegen müsstest du auch unter Linux ziemlich rasch Abstürze/kernel panics bekommen. Sollte dort aber alles wie geschmiert laufen, bekräftigt das den Verdacht auf ein Treiberproblem unter Windows.
Die folgende wall-of-text trägt nicht direkt zur Lösung bei und kannst du ignorieren, wenn dich technische Details nicht so interessieren. Ist aber für andere vielleicht ganz interessant.
#1 092622-12656-01.dmp
#2 092522-8234-01.dmp
#3 092522-7828-01.dmp
#4 092522-7906-01.dmp
#5 092522-8031-01.dmp
#5:
Rich (BBCode):
SYSTEM_SERVICE_EXCEPTION (3b)
An exception happened while executing a system service routine.
Arguments:
Arg1: 00000000c0000005, Exception code that caused the BugCheck
Arg2: ffff8919e8e7cf4a, Address of the instruction which caused the BugCheck
Arg3: ffffb48ff3a53170, Address of the context record for the exception that caused the BugCheck
Arg4: 0000000000000000, zero.
Rich (BBCode):
# Call Site
00 nt!KeBugCheckEx
01 nt!KiBugCheckDispatch
02 nt!KiSystemServiceHandler
03 nt!RtlpExecuteHandlerForException
04 nt!RtlDispatchException
05 nt!KiDispatchException
06 nt!KiExceptionDispatch
07 nt!KiPageFault
08 win32kbase!NtDCompositionConfirmFrame
09 win32k!NtDCompositionConfirmFrame
0a nt!KiSystemServiceCopyEnd
0b 0x0
Auf dem Stacktrace sieht man, dass unmittelbar vor dem Bugcheck ein page fault ausgelöst wurde. Das allein bedeutet noch keinen Fehler, tatsächlich sind page faults Teil vom normalen Windowsbetrieb und werden unter anderem ausgelöst, falls die CPU auf Speicherseiten zugreifen möchte, die sich nicht physischen RAM (working set) befinden, sondern auf die HDD/SSD ausgelagert wurden. Der page fault handler sorgt dann dafür, dass die Speicherseite vom Sekundärspeicher wieder in den RAM geladen wird, und die CPU kann anschließend dort weitermachen, wo sie aufgehört hat.
Arg1 ist
0xc0000005, was
STATUS_ACCESS_VIOLATION entspricht. Das heißt der page fault handler hat den page fault nicht beheben können, weil die Adresse ungültig ist.
Die
Docs sagen dazu:
This can happen because a NULL pointer dereferenced or a random incorrect address was accessed. This in turn can be caused by memory being freed prematurely, or data structure corruption.
Rich (BBCode):
0: kd> .cxr 0xffffb48ff3a53170
rax=0000000000000000 rbx=0000000000000009 rcx=ffff8938065f78c0
rdx=0000000000000008 rsi=ffff8938007c79d0 rdi=ffff893800608a30
rip=ffff8919e8e7cf4a rsp=ffffb48ff3a53b70 rbp=ffffb48ff3a53c80
r8=0000000000000008 r9=7fffa48b7f24ee30 r10=0000000000000000
r11=ffffb48ff3a53b00 r12=000002669be7b890 r13=00000266925e40b0
r14=ffff893800608a38 r15=0000000000000000
iopl=0 nv up ei ng nz na po nc
cs=0010 ss=0018 ds=002b es=002b fs=0053 gs=002b efl=00010286
win32kbase!NtDCompositionConfirmFrame+0x22a:
ffff8919`e8e7cf4a 488b4010 mov rax,qword ptr [rax+10h] ds:002b:00000000`00000010=????????????????
Hier wird versucht,
[rax+10h] zu dereferenzieren. rax ist aber null, also eine klassische null pointer Dereferenzierung.
weiters:
In the past, this error has been linked to excessive use of the paged pool, which may occur due to user-mode graphics drivers crossing over and passing bad data to the kernel code. If you suspect this is the case, use the pool options in Driver Verifier to gather additional information.
Also oft ein Treiberproblem. Grafikkartentreiber würde auch ganz gut passen.
#4
Rich (BBCode):
KERNEL_SECURITY_CHECK_FAILURE (139)
A kernel component has corrupted a critical data structure. The corruption
could potentially allow a malicious user to gain control of this machine.
Arguments:
Arg1: 0000000000000003, A LIST_ENTRY has been corrupted (i.e. double remove).
Arg2: ffffec88428a04b0, Address of the trap frame for the exception that caused the BugCheck
Arg3: ffffec88428a0408, Address of the exception record for the exception that caused the BugCheck
Arg4: 0000000000000000, Reserved
Rich (BBCode):
# Call Site
00 nt!KeBugCheckEx
01 nt!KiBugCheckDispatch
02 nt!KiFastFailDispatch
03 nt!KiRaiseSecurityCheckFailure
04 nt!KiInsertTimerTable
05 nt!KiCommitThreadWait
06 nt!KeDelayExecutionThread
07 nt!MiGatherMappedPages
08 nt!MiMappedPageWriter
09 nt!PspSystemThreadStartup
0a nt!KiStartSystemThread
Hier wird ein
KTIMER Objekt in die Timer Tabelle des Prozessors eingefügt, was den Bugcheck auslöst. Timer laufen auf einem hohen IRQL und werden, wie der Name sagt, von Windows verwendet, um z. B. Zeit zu messen (GetTickCount usw.).
Die
Docs haben diesen Spezialfall aufgelistet:
- A driver has corrupted a periodic KTIMER. This type of bug check typically occurs in nt!Ke* or nt!Ki* code and involves signaling a timer, or inserting or removing a timer from a timer table. The timer being manipulated may be the corrupted one, but it might be necessary to inspect the timer table with !timer (or manually walking the timer list links) to identify which timer has been corrupted. Sometimes, Driver Verifier with special pool can help track down the culprit (if the corrupted KTIMER is in a pool block that has already been freed).
Was hier genau schiefgelaufen ist, lässt sich nur mit einem kompletten Kerneldump sagen.
Code:
1: kd> !timer
fffff78000000000: Unable to get shared data
Wenn man sich auf die Docs verlässt, ist es ziemlich sicher ein Treiberproblem.
#3
Rich (BBCode):
PAGE_FAULT_IN_NONPAGED_AREA (50)
Invalid system memory was referenced. This cannot be protected by try-except.
Typically the address is just plain bad or it is pointing at freed memory.
Arguments:
Arg1: fffffd68b2273730, memory referenced.
Arg2: 0000000000000000, X64: bit 0 set if the fault was due to a not-present PTE.
bit 1 is set if the fault was due to a write, clear if a read.
bit 3 is set if the processor decided the fault was due to a corrupted PTE.
bit 4 is set if the fault was due to attempted execute of a no-execute PTE.
- ARM64: bit 1 is set if the fault was due to a write, clear if a read.
bit 3 is set if the fault was due to attempted execute of a no-execute PTE.
Arg3: fffffd68b15f531c, If non-zero, the instruction address which referenced the bad memory
address.
Arg4: 0000000000000002, (reserved)
Rich (BBCode):
# Call Site
00 nt!KeBugCheckEx
01 nt!MiSystemFault
02 nt!MmAccessFault
03 nt!KiPageFault
04 win32kbase!NtDCompositionConfirmFrame
05 win32k!NtDCompositionConfirmFrame
06 nt!KiSystemServiceCopyEnd
07 0x0
Hier ist wieder ein page fault, allerdings mit einem anderen Bugcheck. Bei #5 war der Grund die Dereferenzierung eines null pointers, hier ist die Adresse nicht direkt ungültig, aber es gibt zur virtuellen Adresse
0xfffffd68b15f531c keine korrespondierende Adresse im physischen RAM, was sich durch einen fehlenden PTE (page table entry) Eintrag bemerkbar macht ("bit 0 set if the fault was due to a not-present PTE"). PTEs beschreiben das mapping von einer virtuellen Adresse zu einer physischen Adresse.
Die
Docs sagen dazu:
The PAGE_FAULT_IN_NONPAGED_AREA bug check has a value of 0x00000050. This indicates that invalid system memory has been referenced. Typically the memory address is wrong or the memory address is pointing at freed memory.
Rich (BBCode):
1: kd> .trap 0xfffff6005c2f49e0
NOTE: The trap frame does not contain all registers.
Some register values may be zeroed or incorrect.
rax=0000000000000000 rbx=0000000000000000 rcx=ffff9a80011a0180
rdx=0000000000000000 rsi=0000000000000000 rdi=0000000000000000
rip=fffffd68b15f531c rsp=fffff6005c2f4b70 rbp=fffff6005c2f4c80
r8=0000000000000001 r9=0000000000000001 r10=fffffd2c806b90d0
r11=fffffd2c807f8f50 r12=0000000000000000 r13=0000000000000000
r14=0000000000000000 r15=0000000000000000
iopl=0 nv up ei pl zr na po nc
win32kbase!NtDCompositionConfirmFrame+0x1bc:
fffffd68`b15f531c 48ff150dc12000 call qword ptr [win32kbase!_imp_KeEnterCriticalRegion (fffffd68`b1801430)] ds:fffffd68`b1801430=????????????????
Hier wird versucht, auf eine nicht belegte Adresse zuzugreifen (non-paged area)
Arg4 des Bugchecks ist
0x2.
0x2 - NONPAGED_BUGCHECK_NOT_PRESENT_PAGE_TABLE The address referenced does not have a valid active page table entry.
Rich (BBCode):
1: kd> r cr2
Last set context:
cr2=fffffd68b2273730
Rich (BBCode):
1: kd> !pte fffffd68b2273730
VA fffffd68b2273730
PXE at FFFF984C26130FD0 PPE at FFFF984C261FAD10 PDE at FFFF984C3F5A2C88 PTE at FFFF987EB4591398
contains 0A0000010DD6C863 contains 0A0000010E70D863 contains 0000000000000000
pfn 10dd6c ---DA--KWEV pfn 10e70d ---DA--KWEV contains 0000000000000000
not valid
Die Formatierung ist hier bisschen merkwürdig, aber man sieht, dass es keinen PTE für diese Adresse gibt, deswegen kann der page fault handler auch nichts machen (deswegen "PAGE_FAULT_IN_NONPAGED_AREA").
weiters:
Bug check 0x50 can be caused by the installation of a faulty system service or faulty driver code. Antivirus software can also trigger this error, as can a corrupted NTFS volume.
It could also occur after the installation of faulty hardware or in the event of failure of installed hardware (usually related to defective RAM, be it main memory, L2 RAM cache, or video RAM).
Hier werden wieder Treiber genannt, aber auch andere Ursachen.
#2
Rich (BBCode):
SYSTEM_SERVICE_EXCEPTION (3b)
An exception happened while executing a system service routine.
Arguments:
Arg1: 00000000c0000005, Exception code that caused the BugCheck
Arg2: fffff8035677be5e, Address of the instruction which caused the BugCheck
Arg3: ffffa38fe73a2c70, Address of the context record for the exception that caused the BugCheck
Arg4: 0000000000000000, zero.
Rich (BBCode):
# Call Site
00 nt!KeBugCheckEx
01 nt!KiBugCheckDispatch
02 nt!KiSystemServiceHandler
03 nt!RtlpExecuteHandlerForException
04 nt!RtlDispatchException
05 nt!KiDispatchException
06 nt!KiExceptionDispatch
07 nt!KiPageFault
08 dxgkrnl!SignalSynchronizationObjectInternal
09 dxgkrnl!DxgkSignalSynchronizationObjectFromGpu2
0a nt!KiSystemServiceCopyEnd
0b 0x0
Hier wieder ähnlich zu #5, jedoch bin ich mir nicht ganz sicher was hier den page fault auslöst... Das könnte tatsächlich eher auf RAM hindeuten.
Rich (BBCode):
1: kd> .trap ffffa38f`e73a34e0
NOTE: The trap frame does not contain all registers.
Some register values may be zeroed or incorrect.
rax=ffffa38fe73a3798 rbx=0000000000000000 rcx=ffffa38fe73a37a0
rdx=0000000000000000 rsi=0000000000000000 rdi=0000000000000000
rip=fffff8035677be5e rsp=ffffa38fe73a3670 rbp=ffffa38fe73a3c80
r8=0000000000000000 r9=0000000000000000 r10=ffffa38fe73a3748
r11=0000000000000001 r12=0000000000000000 r13=0000000000000000
r14=0000000000000000 r15=0000000000000000
iopl=0 nv up ei pl zr na po nc
dxgkrnl!SignalSynchronizationObjectInternal+0xf4e:
fffff803`5677be5e 4585e4 test r12d,r12d
Rich (BBCode):
1: kd> r cr2
Last set context:
cr2=00000000038984c6
Rich (BBCode):
1: kd> !pte 38984c6
Levels not implemented for this platform
Zu #1 hab ich ja weiter oben schon was geschrieben, hier ist der Fehlercode
0xc000001d, was
STATUS_ILLEGAL_INSTRUCTION entspricht.
Rich (BBCode):
SYSTEM_SERVICE_EXCEPTION (3b)
An exception happened while executing a system service routine.
Arguments:
Arg1: 00000000c000001d, Exception code that caused the BugCheck
Arg2: fffff8070a5cbe82, Address of the instruction which caused the BugCheck
Arg3: fffff90538491c70, Address of the context record for the exception that caused the BugCheck
Arg4: 0000000000000000, zero.
Das bedeutet, der Bugcheck wurde ausgelöst, weil die CPU eine Instruktion nicht verarbeiten/dekodieren kann. In diesem Fall ist der instruction pointer bei
dxgkrnl!SignalSynchronizationObjectInternal+0xf72 um 1 Byte zu weit "vorne" und liest deshalb ein multi-byte NOP (
0F 1F 40 00) nicht korrekt. Ich hatte zuerst gedacht, dass die CPU aus 2008 diese Instruktion noch nicht unterstützt, aber laut Intel ist das doch der Fall (siehe Post oben).
Was das angeht bin ich auch überfragt. 2 Instruktionen weiter ist das Ziel eines conditional jump, möglicherweise kann das durch einen random Bit flip verursacht werden, aber da bin ich ehrlich überfragt.
Interessanterweise passiert das in derselben Funktion wie bei Dump #2, innerhalb von
SignalSynchronizationObjectInternal. Das müsste dann schon sehr großer Zufall sein.