
Was ist Hyper-Threading?: Die Grundlagen erklärt
Vorwort
Intel hat es lange dementiert und die Einführung der „Hyper-Threading Technologie“ im Heimbereich immer wieder auf den Prescott hinaus geschoben. Doch seit ein paar Wochen ist es amtlich: Schon der Northwood wird in den kommenden Modellen über dieses Feature verfügen. Was bei Intels Server-Prozessoren mit Prestonia-Kern, den Xeons, schon seit Anfang des Jahres möglich ist, hält nun also auch bei den Desktop-Prozessoren Einzug. Der neue Intel Pentium 4 mit 3066MHz wird diese Technologie zum ersten Mal in die Rechner des Privatanwenders tragen. Dass der weltweit größte Halbleiterhersteller einzig und allein dafür ein leicht modifiziertes Prozessorlogo entworfen hat, macht deutlich, welche Bedeutung Hyper-Threading für Intel besitzt. Sie scheint vom Marketing her schon fast mit der MMX-Erweiterung gleichzuziehen. Deshalb ist es höchste Zeit, dass auch wir uns etwas mit der Funktionsweise von Hyper-Threading beschäftigen.
Wieso Hyper-Threading?
In der Vergangenheit wurden Leistungssteigerungen vor allem durch höhere Taktraten, größere Caches und andere Optimierungen (Prefetch) in der Microarchitektur eines Prozessors ermöglicht. Ein höherer Prozessortakt bedeutet zwar die Berechnung von mehr Instruktionen pro Zeiteinheit, als Takt bezeichnet, bringt jedoch auch immer eine Zunahme in der Leistungsaufnahme mit sich. Darüberhinaus steigt die Systemleistung nicht linear mit dem Prozessortakt. So eignet sich die 20-stufige Pipeline der Netburst Architektur des Pentium 4 zwar ausgezeichnet für hohe Taktraten, doch kommt es zu Unterbrechungen des „Instruktions-Flusses“ in der Pipeline durch Cache Misses, Interrupts oder falsche Sprung-Vorhersagen, sind die Vorteile schnell wieder dahin. So sind Zugriffe auf den Arbeitsspeicher, die bei einem Cache Miss zum Nachladen benötigter Daten erforderlich sind, schneckenlangsam, wenn man sie mit den Transaktionen im internen Prozessor-Cache vergleicht.
Eine Möglichkeit, die Prozessorgeschwindigkeit zu steigern, wäre z.B. die Vergrößerung der L1 und L2 Caches. Allerdings macht gerade dies einen Prozessor noch komplexer, noch größer und noch teurer und selbst dann sind Cache Misses nicht auszuschließen. Weiterhin steigen mit größeren Caches auch die Schwierigkeiten entsprechende Taktraten und Latenzzeiten zu erreichen. Die Caches können also nur dann wirklich schnell sein, wenn sie klein sind. Verbesserte Fertigungstechnologien werden jedoch auch in Zukunft die Caches weiter anwachsen lassen.
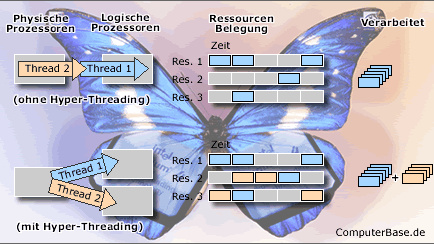
Eine andere Möglichkeit, die Geschwindigkeit eines Prozessors zu steigern, ist das sogenannte Instruction-Level Parallelism (ILP). Hierbei versucht man die pro Taktzyklus ausgeführten Instruktionen zu erhöhen. So verfügen aktuelle Prozessoren beispielsweise über mehrere Ausführungseinheiten, die Instruktionen parallel verarbeiten können. Je mehr unabhängige Befehle der CPU gleichzeitg zur Verfügung stehen, umso effektiver fällt die Nutzung der Taktrate aus. Doch solange die Daten in der Programmreihenfolge ausgeführt ('In-Order Execution') werden, bleibt ein großes Stück Effektivität auf der Strecke. Mit Hilfe der 'Out-of-Order Execution', bei dem die Instruktionen zur Verarbeitung vorher sortiert werden, kann die CPU zwar wesentlich effektiver zur Sache zu gehen, doch wird auch hier Thread für Thread (engl. Pfad), also Programmteil für Programmteil, nacheinander bearbeitet. Wird eine Prozessor-Ressource für einen Thread nicht gebraucht, so liegt sie brach, da nur selten genügend Instruktionen zur Verfügung stehen, um alle Ressourcen voll auszunutzen.
Def. Thread: Kleinster ausführbarer Teil eines Tasks. Beim Task handelt es sich um jenen meist sehr kleinen Teil eines Programms, den ein Prozessor auf einmal bearbeiten kann. Ein Prozessor ist sogar in der Lage, Programmbruchstücke zu bearbeiten, die deutlich kleiner als Tasks sind. Allerdings funktioniert dies nur bis zu einer Untergrenze, die man als Thread bezeichnet. (Wissen.de)
Heutzutage kommt darüber hinaus noch ein weiteres Problem dazu. So haben bereits aktuelle Prozessoren eine Leistungsaufnahme, die nicht mehr ohne weiteres einem Desktop-System im Arbeitszimmer zugemutet werden kann. Allmählich sind die Grenzen erreicht. Einzig und allein mit der kontinuierlichen Erhöhung der Taktrate ist es also nicht getan. Vielmehr müssen die bestehenden Ressourcen des Prozessors effektiver ausgenutzt werden, um auf diese Art und Weise die Leistung des gesamten Computers zu steigern. Das ist der Punkt, an dem die Hyper-Threading Technologie ansetzt.