Ich bin mir nicht ganz sicher, aber für mich hört sich das nach einem klassischen Fall für einen Outer-Join an. Falls ich mich irre und dich nicht ganz verstanden habe, kriegen wir das aber notfalls definitiv mit einer Unterabfrage hin. Erstmal mit Outer-Join:
Code:
SELECT
con.ID AS content_id,
user.ID AS user_id,
user.User AS user_name,
cat.title AS cat_title, -- heißt die Spalte "title"???
scat.title AS scat_title
FROM
oa_content AS con
JOIN
oa_user AS user ON con.Author = user.ID
JOIN
oa_content__cat AS cat ON con.Categorie = cat.cat_id
LEFT JOIN
oa_content__cat AS scat ON con.SubCategorie = cat.cat_id
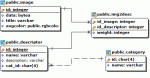
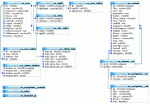
Du hast übrigens eine schreckliche Namensgebung. Bei Content heißt der Primärschlüssel "ID" und bei Categorie plötzlich "cat_id"??? Außerdem komische Groß-Kleinschreibung und andere komische Sachen. Du solltest dir schon überlegen, ob du die Attribute (Spalten) nun groß oder klein schreiben willst, oder mit Unterstrich oder zusammen. Bei der Tabelle "oa_user" lautet der Primärschlüssel anscheinend "ID", bei "oa_content__cat" dann aber wie gesagt anscheinend "cat_id". Doch wieso heißt dann die Spalte "SubCategorie" in "oa_content" nicht logischerweise "sub_category"? Solche Inkonsistenzen machen das ganze extrem schwer zu durchschauen.
Wenn ich in den Beispielen die Spalten falsch benannt habe, musst du das selber anpassen, denn ich steige da nicht durch.....
So, warum ist da hinten dran nun ein LEFT-JOIN? Darum, weil wir die bis dahin mühevoll zusammengebastelte Relation komplett erhalten wollen. Es sollen also auch noch die Tupel (Zeilen) im Ergebnis enthalten sein, bei denen SubCategorie NULL ist. Damit diese Zeilen beim JOIN nicht verschwinden, machen wir hier ein LEFT JOIN.
Eine andere gute Möglichkeit wären Unterabfragen. Beispiel:
Code:
SELECT
con.id,
(SELECT cat.title FROM oa_content__cat AS cat WHERE cat.cat_id = con.Categorie) AS cat_title,
(SELECT scat.title FROM oa_content__cat AS scat WHERE scat.cat_id = con.SubCategorie) AS scat_title
FROM oa_content AS con
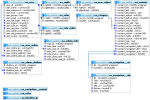
Hab in dem Beispiel der Einfachheit halber die User-Tabelle rausgelassen und wieder geraten, ob die Titel-Spalte von Categorie "title" heißt. Bei Fragen dieser Art bitte in Zukunft auch die Spalten benennen oder idealerweise ein ER-Diagramm anhängen.
Wegen deiner Notation mit den `-Zeichen gehe ich davon aus, dass du MySQL benutzt. Unterabfragen kann MySQL seit Version 4.1.
Beide Beispiele müssten theoretisch funktionieren. Da ich an einigen Stellen raten musste, wie dein DB-Schema genau aussieht, muss aber vielleicht ein bisschen was angepasst werden. Mit mehr Input deinerseits kriegen wir das aber sicher so hin.