Eggcake schrieb:
Die Zugriffszeit wirkt sich nur auf den Zugriff auf 512B aus, was relativ selten vorkommt. Anders gesagt:
20MB/s 4k Random und eine Zugriffszeit von 0.1ms sind genau gleich performant wie 20MB/s 4k Random und 1ms Zugriffszeit [bei 512B].
Genau erklären kann ich den Unterschied aber auch nicht - Auswirkungen auf die Performance hat das aber so gut wie keine.
0,1ms Read Zugriffszeit bedeutet, dass 512Byte Random Reads mit einer Transferrate
von ~5 MB/s übertragen werden können. Jede 0,1 Millisekunde 512 Byte.
Rechnung: 1 s = 1000 ms
1000 ms/0,1 ms = 10000 IOPS * 0,5 KB = 5000 KB/s / 1024 = 4,88... MB/s
Wenn, wie du sagst 512Byte Zugriffe eh selten vorkommen, und wir annehmen, dass 4K-Random Reads ist das häufigste Zugriffsmuster ist und wir mal 2 SSDs gegenüberstellen:
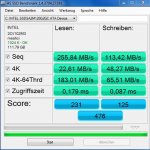
SSD A:
4K-Random - 20 MB/s
0,5K-Random (Zugriffszeit 0,1 ms) - 4,88 MB/s
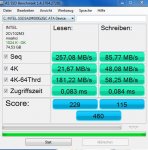
SSD B:
4K-Random - 20 MB/s
0,5K-Random (Zugriffszeit 1,0 ms) - 0,488 MB/s
So ist die Zugriffszeit von SSD B (1 ms) zehnmal so hoch wie von SSD A (0,1 ms), aber diese Umstand hätte keinen Einfluss auf die, ich sage mal zum Beispiel Programmstart-Performance, wenn wir davon ausgehen, dass ein Programmstart hauptsächlich aus 4K-Random-Reads besteht. Denn im 4K Bereich sind hier beide SSDs gleich schnell.
Rein theoretisch dürfte der 4K Read Speed immer ungefähr achtfach so schnell sein wie die 0,5K Speed. Denn Ein SSD-Controller liest ja immer eine gesamte Page aus, welche oft 4K groß ist (bei 2x nm Flash 8K, aber den lass ich jetzt mal außen vor). Wenn also der Controller um 0,5K Benutzerdaten auszulesen die ganzen 4K der Page auslesen muss, hat er ungefähr das 8fache an "Arbeit", als er eigentlich bräuchte, um nur die Nutzdaten auszulesen.
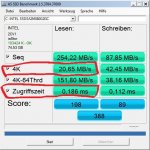
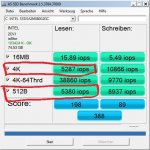
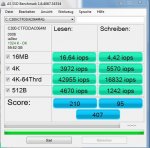
bei meiner Postville G2 siehts so aus:
4K Read 23,01 MB/s
Acc.Time 0,146 ms (= ~ 3,34 MB/s)
23,01 / 3,34 = das 6,89fache bei 4K Read als bei 0,5K Read. Kommt also ungefähr hin was ich hier behaupte xD
Ganz interessant dazu fand ich einen heise-Artikel, der die Zeiten, die eine SSD braucht um eine Page auszulesen in die einzelnen Zwischenschritte aufgeschlüsselt.
Betrachtet man die Transferraten in der Tabelle, so fallen eklatante Unterschiede zwischen sequenziellen und zufällig verteilten Zugriffen, Messungen mit verschiedenen Blockgrößen sowie Lese- und Schreibraten auf. Diese lassen sich mit dem internen Aufbau einer SSD und ein paar Spezialitäten von Flash-Chips erklären: Beim Lesen holt der Flash-Chip immer eine komplette Page (2 bis 4 KByte) aus den Flash-Zellen in ein Pufferregister. Das dauert bei einem aktuellen Samsung-SLC-Chip (siehe Soft-Link) nach dem Übertragen und Anlegen der Adresse rund 25 µs. Von dort wandert alle 25 ns (Read Cycle Time) ein Byte zum Controller. Somit dauert das Auslesen einer 4-KByte-Page rund 127 µs. Das ergäbe – für einen einzelnen Flash-Chip – eine Transferrate von gerade einmal 30,8 MByte/s. Die Latenzzeit für den Datentransfer zwischen Zellen und Register kann der Chip im Idealfall kaschieren, da er aus zwei Dice mit je vier Planes besteht. Jede Plane hat eigene Pufferregister, sodass eine Plane Daten von den Flash-Zellen holen kann, während eine andere den Controller füttert. Somit kann der Chip rund 38 MByte/s liefern. Die Transferraten von MLC-Speicher liegen noch weit unter denen ihrer SLC-Kollegen.

") ).
).