Hallo Leute
Hoffentlich bin ich hier richtig. Ich habe einen Kunden von dem ich Bilder und Videos erhalte. Das sind über 1000 Dateien. Es gibt verschiedene Objekte als Beispiel: Objekt 1A, oder Objekt 1B usw. Das sind insgesamt ca 200 Objekte (sagen wir 200 Ordner mit über 1000 Bilder).
Ich erhalte vom Kunden ein XML Feed, da ist eine Textdatei mit verschiedenen Links die direkt zu den Bildern und Videos führt. Auf Anfrage ob ich FTP Zugriff bekomme, wurde mir abgelehnt.
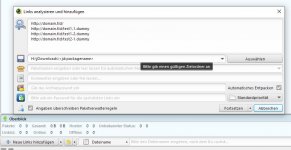
Mit jdownloader2 kann ich diese Links von Hand einfügen und herunterladen, jedoch ist das ziemlich umständlich bei über 1000 Dateien.
Gibt es eine Möglichkeit diese Bilder und Videos anders zu herunterladen?
Hoffentlich bin ich hier richtig. Ich habe einen Kunden von dem ich Bilder und Videos erhalte. Das sind über 1000 Dateien. Es gibt verschiedene Objekte als Beispiel: Objekt 1A, oder Objekt 1B usw. Das sind insgesamt ca 200 Objekte (sagen wir 200 Ordner mit über 1000 Bilder).
Ich erhalte vom Kunden ein XML Feed, da ist eine Textdatei mit verschiedenen Links die direkt zu den Bildern und Videos führt. Auf Anfrage ob ich FTP Zugriff bekomme, wurde mir abgelehnt.
Mit jdownloader2 kann ich diese Links von Hand einfügen und herunterladen, jedoch ist das ziemlich umständlich bei über 1000 Dateien.
Gibt es eine Möglichkeit diese Bilder und Videos anders zu herunterladen?