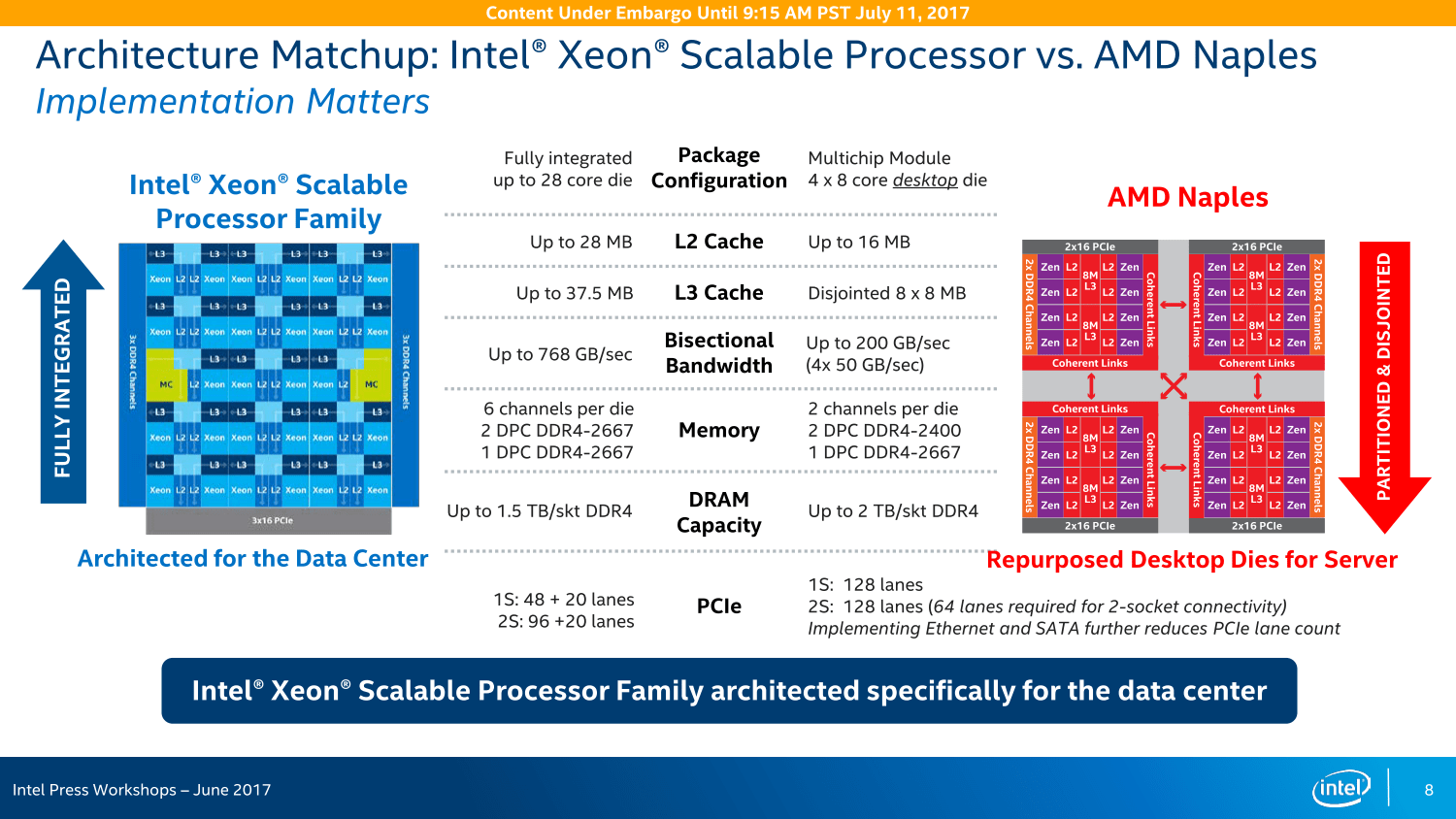
AMD hat schon eine recht starke Plattform mit Epyc gebaut.
Gute Chancen hat man mit EPYC sicherlich in folgenden Bereichen:
- Cloud-Anbieter
- HPC-Anwendungen ohne Vektor-Berechnungen
- HPC-Cluster mit GPU-Beschleunigung (spricht ja nix dagegen einen EPYC mit einer Tesla P100/V100 zu kombinieren)
- reine OpenSource Lösungen
In den Bereichen "Standard-Server" und "Standard-Software" für normale Unternehmen wird sich AMD erstmal schwer tun. Für Skylake-SP gibt es bereits ab heute entsprechende Server-Designs der großen "Fünf":
HPE ProLiant "Gen10"
Dell PowerEdge 14G
Cisco UCS "M5"
Fujitsu PRIMERGY "M4"
Lenovo ThinkSystem "SR***"
Man flutet quasi direkt am Tag-1 mit neuen Servermodellen den Markt, während für EPYC kaum etwas auf der Roadmap steht oder nur kleine Nischen-Produktlinien oder OEMS/ODMs (Asus, Gigabyte & Co) etwas anbieten.
Bei der Software im Enterprise wird es teilweise noch lange dauern, bis die AMD-Plattform offiziell unterstützt werden. Das ist AMDs große Schwäche, in punkto Ökosystem ist man einfach die letzten Jahre vollkommen vom Markt verschwunden.
In diesem Punkt haben die Intel Folien absolut recht.
Gute Chancen hat man mit EPYC sicherlich in folgenden Bereichen:
- Cloud-Anbieter
- HPC-Anwendungen ohne Vektor-Berechnungen
- HPC-Cluster mit GPU-Beschleunigung (spricht ja nix dagegen einen EPYC mit einer Tesla P100/V100 zu kombinieren)
- reine OpenSource Lösungen
In den Bereichen "Standard-Server" und "Standard-Software" für normale Unternehmen wird sich AMD erstmal schwer tun. Für Skylake-SP gibt es bereits ab heute entsprechende Server-Designs der großen "Fünf":
HPE ProLiant "Gen10"
Dell PowerEdge 14G
Cisco UCS "M5"
Fujitsu PRIMERGY "M4"
Lenovo ThinkSystem "SR***"
Man flutet quasi direkt am Tag-1 mit neuen Servermodellen den Markt, während für EPYC kaum etwas auf der Roadmap steht oder nur kleine Nischen-Produktlinien oder OEMS/ODMs (Asus, Gigabyte & Co) etwas anbieten.
Bei der Software im Enterprise wird es teilweise noch lange dauern, bis die AMD-Plattform offiziell unterstützt werden. Das ist AMDs große Schwäche, in punkto Ökosystem ist man einfach die letzten Jahre vollkommen vom Markt verschwunden.
In diesem Punkt haben die Intel Folien absolut recht.